









原文链接:https://arxiv.org/pdf/2412.10373
简介:目前,基于时序输入的3D占用预测方法多融合过去帧的表达,预测当前帧的占用,但其忽视了驾驶场景的连续性和3D场景演化的先验(如仅有动态物体会移动)。本文将3D占用估计任务视为以当前传感器输入为条件的4D占用预测任务,并将场景分解为(1)静态场景的自车运动对齐,(2)动态物体的局部运动和(3)新观测场景。本文提出的高斯世界模型GaussianWorld显式地利用先验,考虑当前RGB观测,在3D高斯空间中推断场景演化。
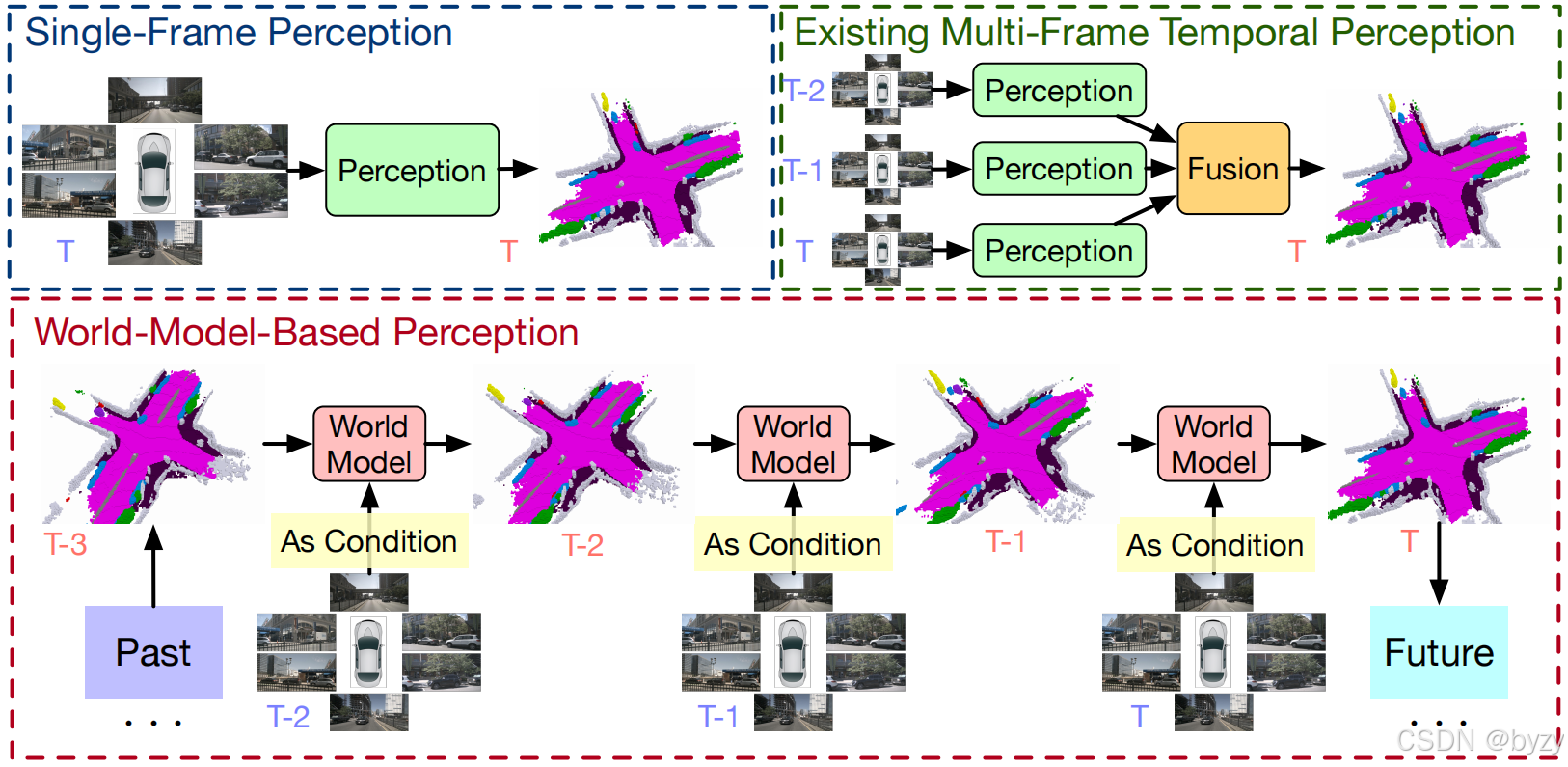
1. 感知的世界模型
感知模型基于当前帧
T
T
T和过去
t
t
t帧的传感器输入
{
x
T
,
x
T
−
1
,
⋯
,
x
T
−
t
}
\{x^T,x^{T-1},\cdots,x^{T-t}\}
{xT,xT−1,⋯,xT−t},获取感知
y
T
y^T
yT:
y
T
=
A
(
{
x
T
,
⋯
,
x
T
−
t
}
,
{
p
T
,
⋯
,
p
T
−
t
}
)
y^T=A(\{x^T,\cdots,x^{T-t}\},\{p^T,\cdots,p^{T-t}\})
yT=A({xT,⋯,xT−t},{pT,⋯,pT−t})
其中 p t p^t pt为 t t t时刻的自车位置。
传统的感知时序建模包括三个阶段:感知、变换和融合。感知模块
P
e
r
P_{er}
Per提取各帧的场景表达
z
z
z;变换模块
T
r
a
n
s
T_{rans}
Trans根据自车轨迹,将过去帧特征对齐到当前帧;融合模块
F
u
s
e
F_{use}
Fuse整合多帧表达进行感知。传统流程如下所示:
z
n
=
P
e
r
(
x
n
)
,
a
n
=
T
r
a
n
s
(
z
n
,
p
n
)
,
y
T
=
F
u
s
e
(
a
T
,
⋯
,
a
T
−
t
)
z^n=P_{er}(x^n),\;\;a^n=T_{rans}(z^n,p^n),\;\;y^T=F_{use}(a^T,\cdots,a^{T-t})
zn=Per(xn),an=Trans(zn,pn),yT=Fuse(aT,⋯,aT−t)
其中 a n a^n an为第 n n n帧对齐的场景表达, n = T − t , ⋯ , T n=T-t,\cdots,T n=T−t,⋯,T。
上述方案没有考虑到相邻帧的关联性,性能有限。本文提出基于世界模型的方法,利用场景演化进行感知。感知世界模型
w
w
w基于过去帧表达
z
T
−
1
z^{T-1}
zT−1和当前帧传感器输入
x
T
x^T
xT预测当前表达
z
T
z^T
zT:
z
T
=
w
(
z
T
−
1
,
x
T
)
z^T=w(z^{T-1},x^T)
zT=w(zT−1,xT)
进一步,本文将3D感知任务视为以当前传感器输入为条件的4D预测任务:
y
T
=
A
(
z
T
−
1
,
x
T
)
=
h
(
w
(
z
T
−
1
,
x
T
)
)
y^T=A(z^{T-1},x^T)=h(w(z^{T-1},x^T))
yT=A(zT−1,xT)=h(w(zT−1,xT))
其中 h h h为基于表达 z z z的感知头。
得到预测的场景表达 z T z^T zT和下一帧观测 x T + 1 x^{T+1} xT+1后,可将其输入世界模型预测下一帧表达 z T + 1 z^{T+1} zT+1。
若去掉 z T − 1 z^{T-1} zT−1的输入,则本文方法与GaussianFormer相似。
2. 显式场景演化建模
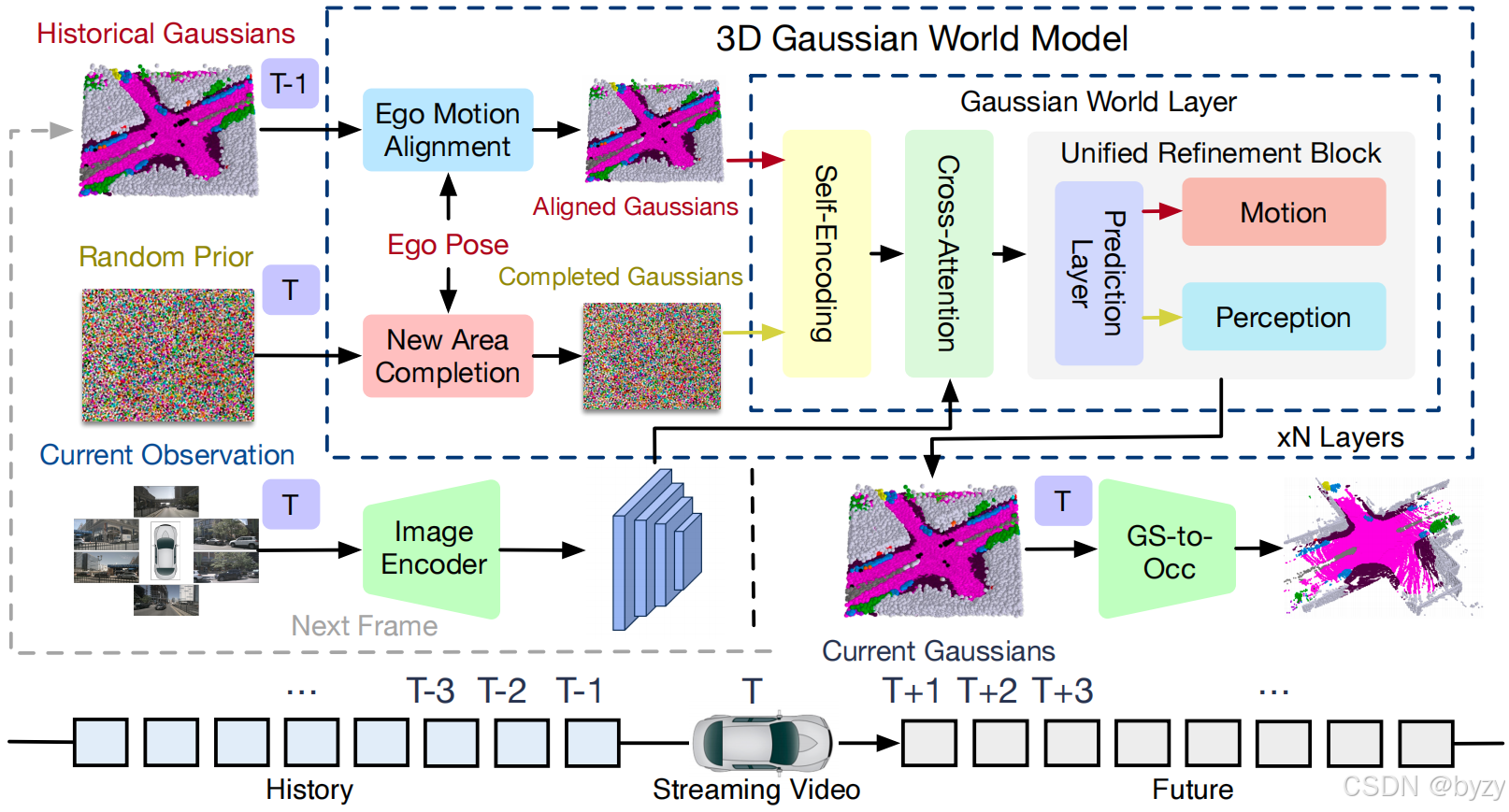
场景的演化可分解为三个因素:(1)静态场景的自车运动对齐;(2)动态物体的局部运动;(3)新观测区域的补全。如图所示。

本文使用3D高斯作为场景表达,以显式、连续地建模场景演化。每个3D语义高斯包括位置
p
p
p、尺度
s
s
s、旋转
r
r
r和语义概率
c
c
c属性。此外,本文引入时间特征
f
f
f属性,以捕捉3D高斯的历史信息。则3D高斯
g
g
g可表达为:
g
=
{
p
,
s
,
r
,
c
,
f
}
g=\{p,s,r,c,f\}
g={p,s,r,c,f}
提出的GaussianWorld
w
w
w根据过去的3D高斯
g
T
−
1
g^{T-1}
gT−1和当前传感器输入
x
T
x^T
xT,预测当前的3D高斯
g
T
g^T
gT:
g
T
=
w
(
g
T
−
1
,
x
T
)
g^T=w(g^{T-1},x^T)
gT=w(gT−1,xT)
静态场景的自车运动对齐。使用对齐模块
A
l
i
g
n
A_{lign}
Align将上一帧3D高斯
g
T
−
1
g^{T-1}
gT−1对齐到当前帧,即基于自车轨迹,对场景的所有3D高斯使用全局仿射变换。给定仿射变换矩阵
M
e
g
o
M_{ego}
Mego,对齐的3D高斯
g
A
T
g_A^T
gAT为
g
A
T
=
A
l
i
g
n
(
g
T
−
1
,
M
e
g
o
)
=
R
e
f
(
g
T
−
1
;
M
e
g
o
⋅
A
t
t
r
(
g
T
−
1
;
p
)
;
p
)
g_A^T=A_{lign}(g^{T-1},M_{ego})=R_{ef}(g^{T-1};M_{ego}\cdot A_{ttr}(g^{T-1};p);p)
gAT=Align(gT−1,Mego)=Ref(gT−1;Mego⋅Attr(gT−1;p);p)
其中 A t t r A_{ttr} Attr(g;p)为3D高斯 g g g的 p p p属性, R e f ( g ; n ; p ) R_{ef}(g;n;p) Ref(g;n;p)为使用 n n n更新3D高斯 g g g的 p p p属性。
动态物体的局部运动。基于语义概率,对齐的3D高斯
g
A
T
g_A^T
gAT被分为互斥的两类:动态高斯集{g_D}和静态高斯集
{
g
S
}
\{g_S\}
{gS}。使用运动层
M
o
v
e
M_{ove}
Move预测动态高斯的移动:
g
M
T
=
M
o
v
e
(
g
A
T
,
x
T
)
=
R
e
f
(
g
A
T
;
E
n
c
(
g
A
T
,
x
T
)
⋅
I
(
g
A
T
∈
{
g
D
}
)
;
p
)
g_M^T=M_{ove}(g_A^T,x_T)=R_{ef}(g_A^T;E_{nc}(g_A^T,x_T)\cdot I(g_A^T\in\{g_D\});p)
gMT=Move(gAT,xT)=Ref(gAT;Enc(gAT,xT)⋅I(gAT∈{gD});p)
其中 E n c E_{nc} Enc为编码模块, I ( ⋅ ) I(\cdot) I(⋅)为指示函数。
新观测区域的补全。在自车运动过程中,本文丢弃移动到边界外的高斯,并用随机初始化的高斯补全新观测区域。新的高斯
g
I
T
g_I^T
gIT是通过在新观测区域均匀采样得到的。使用感知层
P
e
r
P_{er}
Per预测新高斯的所有属性:
g
C
T
=
P
e
r
(
g
I
T
,
x
T
)
=
R
e
f
(
g
I
T
;
E
n
c
(
g
I
T
,
x
T
)
;
{
p
,
s
,
r
,
c
,
f
}
)
g_C^T=P_{er}(g_I^T,x_T)=R_{ef}(g_I^T;E_{nc}(g_I^T,x_T);\{p,s,r,c,f\})
gCT=Per(gIT,xT)=Ref(gIT;Enc(gIT,xT);{p,s,r,c,f})
3. 3D高斯世界模型
当前帧的初始表达为对齐的高斯
g
A
T
g_A^T
gAT和新增的高斯
g
I
T
g_I^T
gIT:
g
T
=
[
g
A
T
,
g
I
T
]
g^T=[g_A^T,g_I^T]
gT=[gAT,gIT]
分别使用运动层
M
o
v
e
M_{ove}
Move和感知层
P
e
r
P_{er}
Per,基于
x
T
x^T
xT更新
g
A
T
g_A^T
gAT和
g
I
T
g_I^T
gIT。注意这两个模块共享结构和参数(均为编码模块
E
n
c
E_{nc}
Enc+细化模块
R
e
f
R_{ef}
Ref,唯一区别在于更新的高斯属性),从而可被集成到统一的演化模块
E
v
o
l
E_{vol}
Evol中并行计算。
g
l
+
1
T
=
E
v
o
l
(
g
l
T
,
x
T
)
=
{
P
e
r
(
g
l
T
,
x
T
)
若新
M
o
v
e
(
g
l
T
,
x
T
)
否则
g_{l+1}^T=E_{vol}(g_l^T,x_T)=\begin{cases}P_{er}(g_l^T,x_T)&若新\\M_{ove}(g_l^T,x_T)&否则\end{cases}
gl+1T=Evol(glT,xT)={Per(glT,xT)Move(glT,xT)若新否则
其中
g
l
T
g_l^T
glT为第
l
l
l(
l
=
1
,
⋯
,
n
e
l=1,\cdots,n_e
l=1,⋯,ne)层演化模块的3D高斯。为处理3D表达和真实世界潜在的不对齐,本文还引入
n
r
n_r
nr个细化层,微调3D高斯的属性:
g
n
+
1
T
=
R
e
f
i
n
e
(
g
n
T
,
x
T
)
=
R
e
f
(
g
n
T
;
E
n
c
(
g
n
T
,
x
T
)
;
{
p
,
s
,
r
,
c
,
f
}
)
g_{n+1}^T=R_{efine}(g_n^T,x_T)=R_{ef}(g_n^T;E_{nc}(g_n^T,x_T);\{p,s,r,c,f\})
gn+1T=Refine(gnT,xT)=Ref(gnT;Enc(gnT,xT);{p,s,r,c,f})
其中
g
n
T
g_n^T
gnT为第
n
n
n个细化层的3D高斯。

使用交叉熵损失和lovasz-softmax损失,并在单帧任务上预训练。随后,使用流式训练策略微调模型,即每轮迭代中,会将当前帧图像和上一帧预测的3D高斯输入模型进行3D占用预测。
由于训练早期预测误差较大,因此早期训练使用短序列,并逐步增加序列长度,以增强训练稳定性。此外,使用概率建模,以概率 p p p随机丢弃上一帧的3D高斯表达,并在训练中逐渐减小 p p p,以使模型适应长序列。


















 7063
7063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











