







 本文详细解析了Xilinx7系列FPGA中的可编程逻辑单元(CLB)、SLICE结构,特别是SLICEL和SLICEM内的LUT6、MUX、触发器等功能,以及CarryChain在加法运算中的应用。同时讨论了如何优化计数器使用以改善时序性能和资源分配。
本文详细解析了Xilinx7系列FPGA中的可编程逻辑单元(CLB)、SLICE结构,特别是SLICEL和SLICEM内的LUT6、MUX、触发器等功能,以及CarryChain在加法运算中的应用。同时讨论了如何优化计数器使用以改善时序性能和资源分配。
声明:
本文章部分转载自傅里叶的猫,作者猫叔
本文章部分转载自FPGA探索者,作者肉娃娃
本文以Xilinx 7 系列 FPGA 底层资源为例。
FPGA 主要有六部分组成:可编程输入输出单元(IO)、可编程逻辑单元(CLB)、完整的时钟管理、嵌入块状RAM、布线资源、内嵌的底层功能单元和内嵌专用硬件模块。其中最为主要的是可编程输出输出单元、可编程逻辑单元和布线资源。这些逻辑单元的内部结构像大型“停车场”。

可配置逻辑单元
可配置逻辑单元(Configurable Logic Block,CLB)在 FPGA 中最为丰富,由两个 SLICE 组成。由于 SLICE 有 SLICEL(L:Logic)和 SLICEM(M:Memory)之分,因此 CLB 可分为 CLBLL 和 CLBLM 两类。
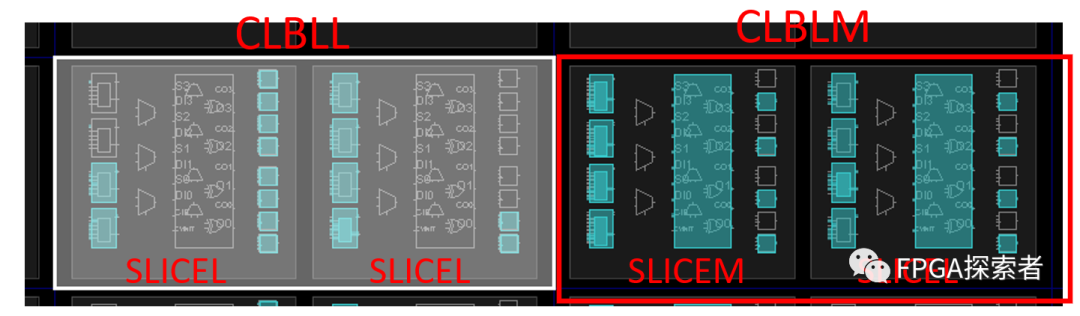
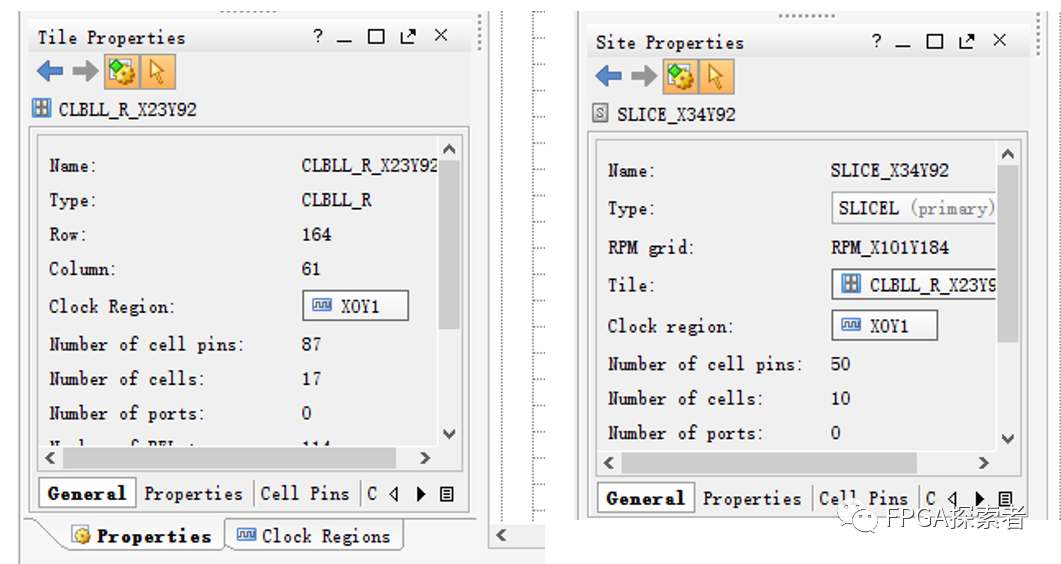
点击内部的逻辑单元,通过阴影区别包含的范围,你可以清晰的看到结构划分的层级。在旁边窗口可以清晰的看到选中部分的属性(Properties)。
来,再放大,放大到一个 SLICEL,如下图所示。

SLICEL 和 SLICEM 内部都包含 4 个 6 输入查找表(Look-Up-Table,LUT6)、3 个数据选择器(MUX)、1 个进位链(Carry Chain)和 8 个触发器(Flip-Flop),下面分部分介绍的时候,时不时可以再回头看这张结构图。
输入查找表(LUT6)
虽然 SLICEL 和 SLICEM 的结构组成一样,但两者更细化的结构上略有不同,区别在于 LUT6 上(如下图所示),从而导致LUT6的功能有所不同(如下表格所示)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5469
5469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











