







0. 摘要
无监督多视图立体方法最近取得了可喜的进展。然而,以前的方法主要依赖于光度一致性假设,这可能会受到两个限制:低识别度的区域和依赖于视图的效果,例如低纹理区域和反射。为了解决这些问题,我们提出了一种新的双对比学习方法,称为 CL-MVSNet。具体来说,我们的模型将两个对比分支集成到无监督 MVS 框架中,以构建额外的监督信号。一方面,我们提出了图像级对比分支来引导模型获得更多的上下文感知,从而在不可区分的区域中实现更完整的深度估计。另一方面,我们利用场景级对比分支来提高表示能力,提高依赖于视图的效果的鲁棒性。此外,为了恢复更准确的 3D 几何形状,我们引入了光度一致性损失,这鼓励模型更多地关注准确的点,同时减轻不良点的梯度惩罚。对DTU和Tanks and Temples的大量实验表明,我们的方法在所有端到端无监督框架中实现了最先进的性能,并且在无需微调的情况下大幅优于有监督的对应框架。
1. 引言
主要贡献如下:
- 提出了图像级对比一致性损失,这使用模型更加具有上下文感知能力并在不易区分的区域中实现更完整的重建。
- 提出了场景级对比一致性损失,这增强了表示能力,从而提高了视图相关效果的鲁棒性。
- 提出了
光度一致性损失来进一步推进对比学习框架,使模型能够专注于准确的点,从而实现更准确的重建。
- DTU和Tanks and Temples基准测试的实验表明,我们的方法优于最先进的端到端无监督模型,并超越其有监督模型。
1. 相关工作
2.1. 监督MVS
随着深度学习技术和大规模3D数据集的发展,有监督MVS近年来取得了重大进展。MVSNet提出了一种流行的MVS流水线,可以概括为四个步骤:特征提取、成本聚合、成本量正则化和深度回归。最近的工作通过引入多级架构 RNN 来努力减轻巨大的内存和计算成本以及其他一些方法。然而,上述所有方法都依赖于标记的训练数据,而在实践中获得这些数据的成本很高。
2.2. 端到端非监督与多阶段自监督MVS
把没有监督信号的MVS框架分为两类,到端非监督和多阶段自监督。前者主要依赖光度一致性假设,它强制重建的图像和reference image保持光度一致性,但是这在很多场景下是无法保证的,所以近年来也有研究者考虑法线一致性、语义一致性等等;后者力求通过处理推断得到的深度图来得到可靠的伪标签来监督训练,但是这使得训练过程不是端到端的。并且额外产生的标签数据也占用存储空间,自监督训练也十分耗时。
3. Method
本节将详细阐述文章的主要贡献。我们首先描述无监督主干(第 3.1 节),然后描述所提出的图像级对比度一致性(第 3.2 节)、场景级对比度一致性(第 3.3 节)和L0.5光度一致性(第 3.4 节)。 最后,我们介绍了训练期间的整体损失函数(第 3.5 节)。我们的架构概述如图2所示。CL-MVSNet是一个适用于任意基于学习的 MVS 的通用框架。我们以代表性的CasMVSNet作为这项工作的backbone。
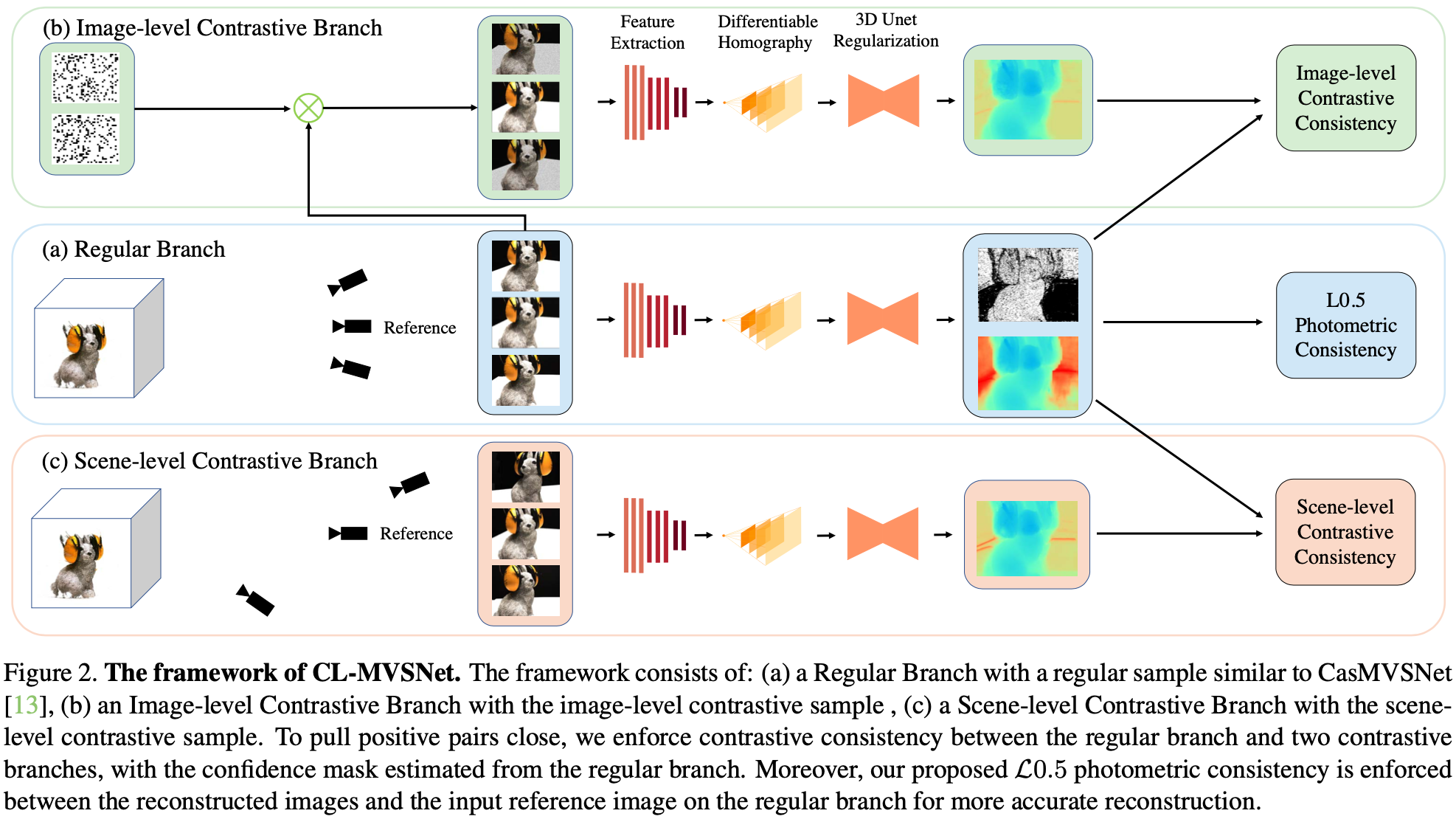
3.1. 非监督 Multi-view Stereo
输入一张ref图和若干张src图,分阶段特征提取这些步骤和CasMVSNet一样。在代价体聚合阶段,我们将个通道的N个特征体
分成
组,然后构造原始代价体C如下:
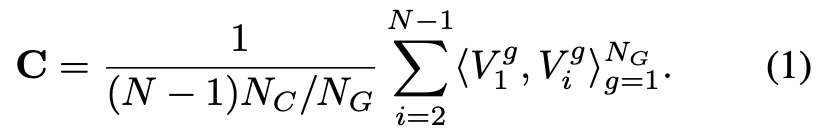
然后使用3D UNet来处理这个原始代价体,使用softmax来获得概率体,然后使用加权和获得最终深度图D:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









