








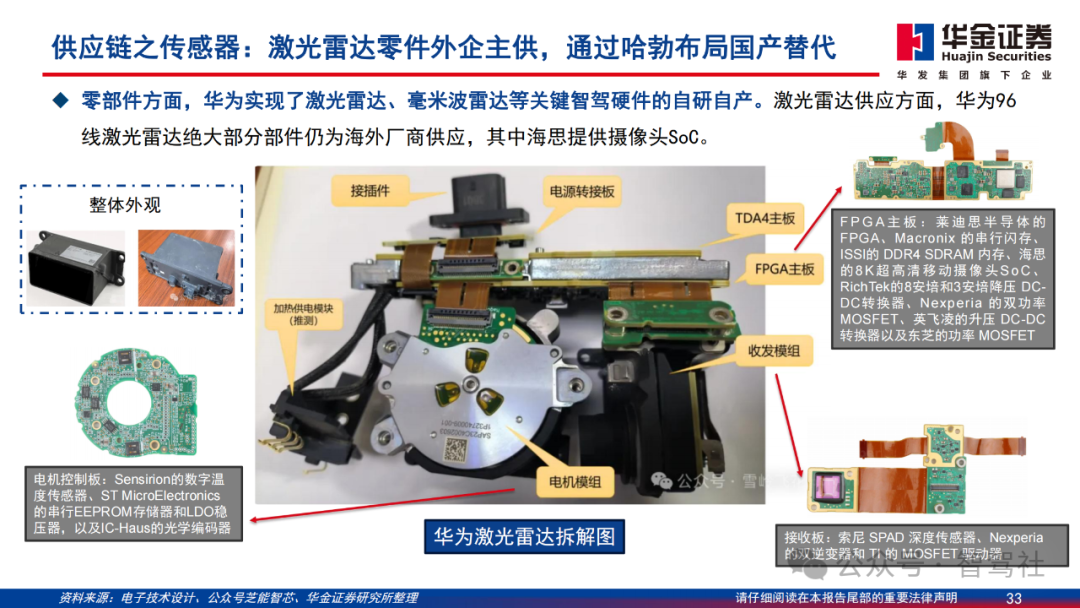
华为ADS智驾方案始终坚持激光雷达+毫米波雷达+摄像头的多传感器融合路线,行业降本压力下硬件配置从超配逐步转向贴合实际需求,带动整体硬件成本下降。
1)单车传感器数量呈现下降趋势,包括激光雷达从3个减配至1个、毫米波雷达从6R减配至3R、摄像头数量亦有所减少;
2)车侧算力从400TOPS降低至200TOPS、更贴合实际需求,同时或在探索“Max + Pro”双版本智驾硬件配置方案。
算法架构方面,从2021年的ADS1.0到2023年的ADS 2.0,障碍物识别从人工标注走向自主决策、道路识别上从有图方案转为无图方案,而今年4月发布的3.0版本采用端到端大模型。
华为ADS在感知、决策规划两大方面持续选代:
1)障碍物识别方面,从BEV升级至G0D,优化对异形障碍物、罕见障碍物的识别性能;
2)车道识别及路径规划方面,从1.0的“有高精地图”转向2.0的“无图”,无外购高精地图基础下,采用RCR算法完成车道实时识别及路径规划,提升了智驾方案的城市泛化速度及更新频率;
3)ADS 3.0采用端到端大模型,有别于特斯拉所宣传的“大一统”模型,华为ADS采用感知+决策分层的GOD+PDP架构。
智驾生态逐步扩大,华为作为国内领先智驾厂商有望引领产业发展。华为目前已与五大车企深度合作,三大合作模式下终端车企“朋友圈”陆续开拓中。ADS高阶包或已实现销售规模超30亿元,车BU已接近盈亏平衡。同时,华为积极参与国内智驾标准建立,未来有望持续引领我国智驾产业发展。华为智驾持续发展带动其合作车型竞争力不断提升,因此我们推荐关注华为合作智驾车型相关供应链的发展机遇。


























(获得材料,加小编微信号zhijiashexiaoming)





















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











