









北大和字节发布一个新的图像生成框架VAR。首次使GPT风格的AR模型在图像生成上超越了Diffusion transformer。
同时展现出了与大语言模型观察到的类似Scaling laws的规律。在ImageNet 256x256基准上,VAR将FID从18.65大幅提升到1.80,IS从80.4提升到356.4,推理速度提高了20倍。

相关链接
项目地址:https://github.com/FoundationVision/VAR
Demo地址:https://var.vision
模型下载地址:https://huggingface.co/FoundationVision/var
VAR简介

视觉自回归建模(VAR)是一种新的视觉生成范式,它将图像的自回归学习重新定义为从粗到细的“下一个尺度预测”或“下一个分辨率预测”,与标准光栅扫描“下一个令牌”不同预言”。这种简单、直观的方法允许自回归(AR)转换器快速学习视觉分布并很好地概括。
自回归视觉生成的新范式✨:
视觉自回归建模(VAR)将图像的自回归学习重新定义为从粗到细的“下一个尺度预测”或“下一个分辨率预测”,与标准光栅扫描“下一个标记预测”不同。
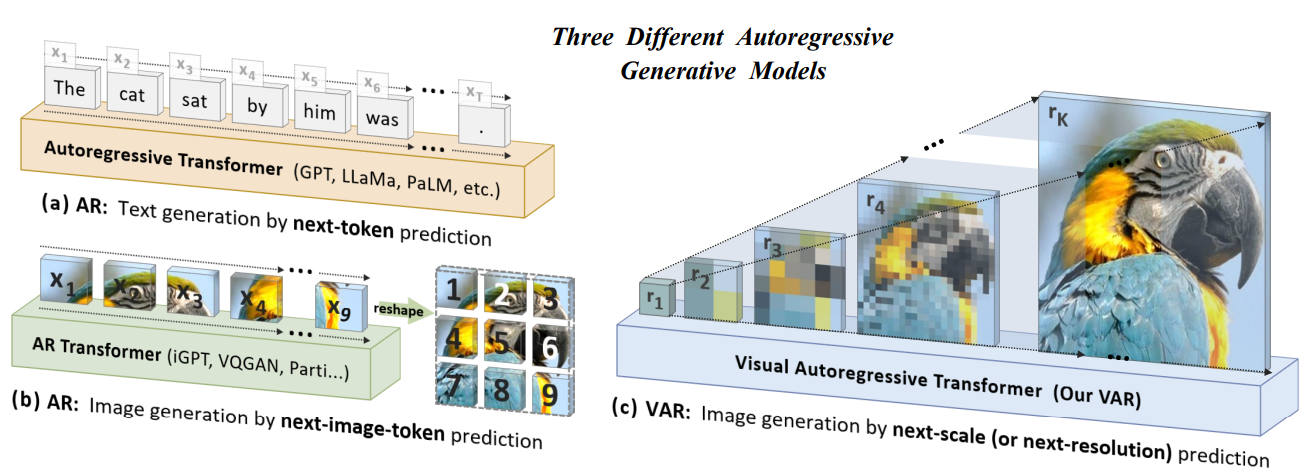
GPT式自回归模型首次超越扩散模型:
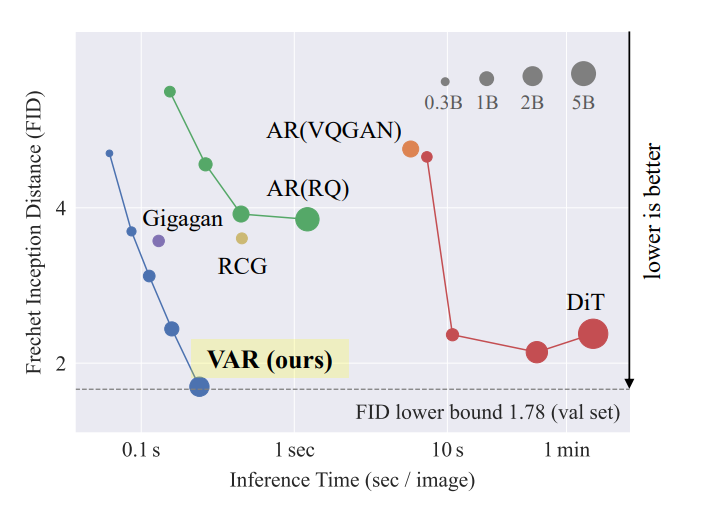
该图研究了不同模型在ImageNet-256条件生成基准上的缩放行为。半径表示模型尺寸。轴采用对数刻度。 VAR首次使自回归模型在图像生成方面在多个维度上超越了扩散变换器(DiT):图像质量、推理速度、数据效率和可扩展性。
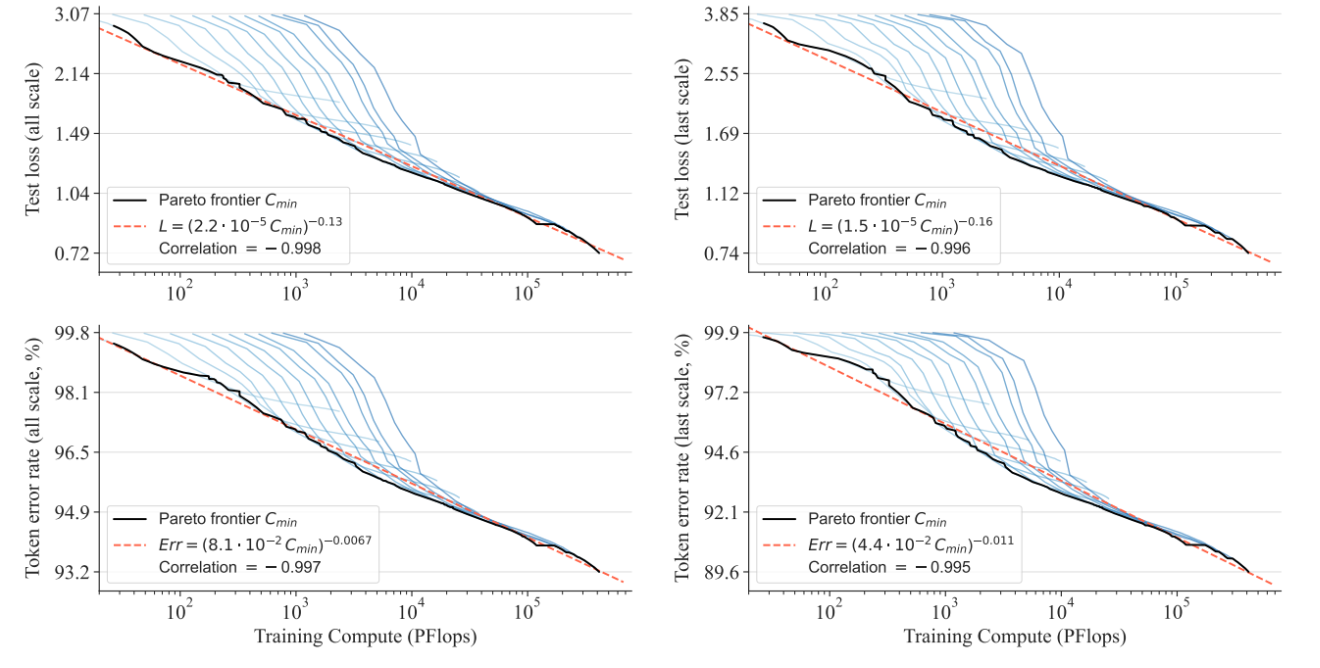
发现VAR Transformer中的幂律缩放定律
零样本泛化能力



提供模型下载地址
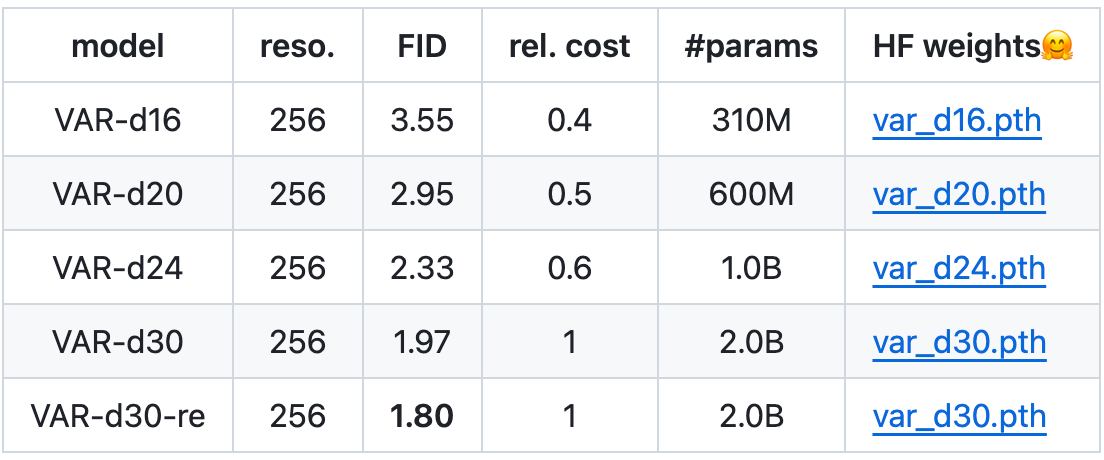
实验
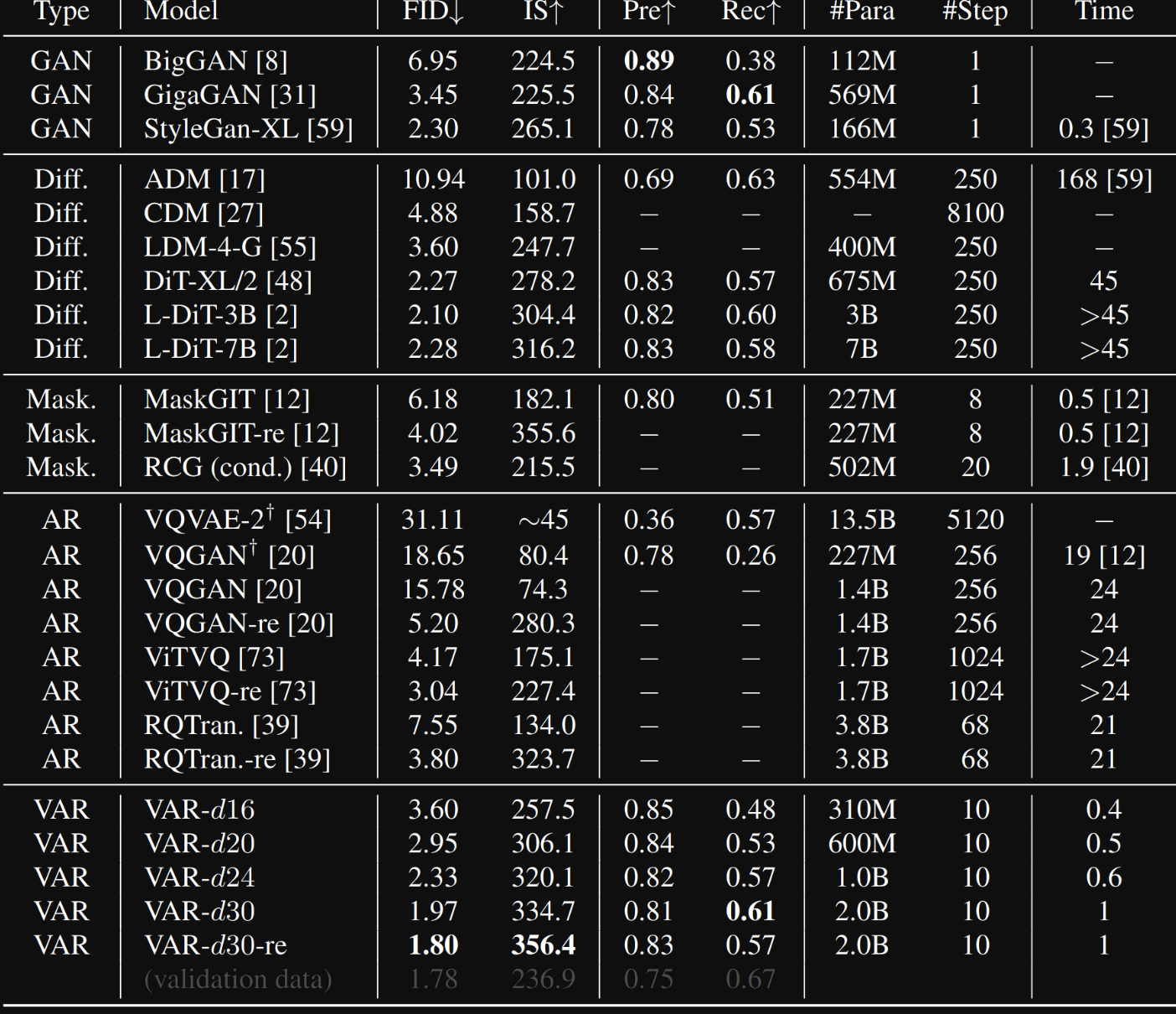
在 ImageNet-256×256基准上,VAR通过将Fréchet起始距离(FID)从5.20提高到1.80、起始分数(IS)从280.3提高到356.4,显着提高了其 AR 基线,推理速度提高了24倍。VAR使得GPT式自回归模型在FID分数、IS分数、推理速度和可扩展性方面首先超越了扩散变压器(DiT)。
Demo生图效果




















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











