







MMoE(Multi-gate Mixture-of-Experts)是一种多任务学习模型,它通过使用多个专家网络(Experts)和门控机制(Gates)来学习不同任务之间的关系。每个任务都有自己的门控网络,用于控制来自不同专家网络的信息流。以下是MMoE模型的一个简化的代码实现示例,包括详细的注释和背后原理:
原理解释:
-
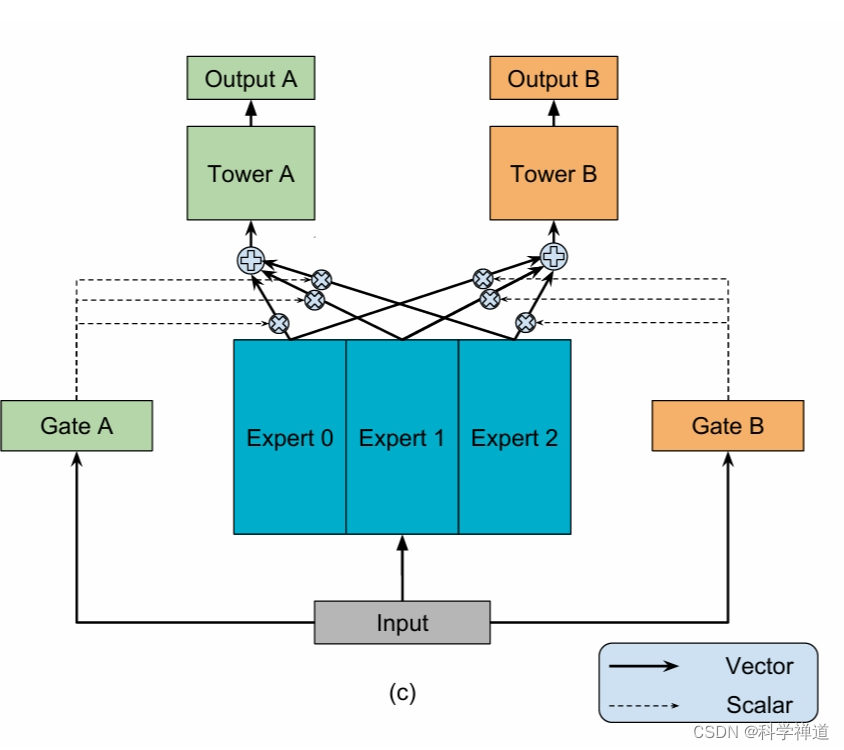
专家网络(Experts):每个专家网络专注于学习对所有任务有用的特征。
-
门控网络(Gates):每个任务都有自己的门控网络,它们负责分配不同专家的输出,以形成该任务的最终表示。
-
塔连接(Tower Connections):每个任务的门控网络不仅考虑来自专家网络的信息,还可以考虑来自其他任务门控网络的信息,形成塔连接。
-
任务特定层(Task-Specific Layers):每个任务在MMoE之上有自己的特定层,用于最终的预测。
架构框图
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, input_dim, expert_dim):
super(Expert, self).__init__()
# 专家网络,学习共享特征
self.fc = nn.Linear(input_dim, expert_dim)
def forward(self, x):
return self.fc(x)
class Gate(nn.Module):
def __init__(self, input_dim, num_experts, num_tasks):
super(Gate, self).__init__()
# 门控网络,为每个任务学习权重
self.gates = nn.Linear(input_dim, num_tasks)
# 门控softmax,为每个专家分配权重
self.gate_softmax = nn.Softmax(dim=-1)
def forward(self, x):
# 学习门控权重
gate_logits = self.gates(x)
# 将权重softmax归一化,以便进行加权求和
gate_weights = self.gate_softmax(gate_logits)
return gate_weights
class MMoE(nn.Module):
def __init__(self, input_dim, expert_dim, num_experts, num_tasks):
super(MMoE, self).__init__()
# 专家集合
self.experts = nn.ModuleList([Expert(input_dim, expert_dim) for _ in range(num_experts)])
# 门控集合,每个任务有自己的门控网络
self.gates = nn.ModuleList([Gate(expert_dim, num_experts, num_tasks) for _ in range(num_tasks)])
# 任务特定层,每个任务有自己的输出层
self.task_specific_layers = nn.ModuleList([nn.Linear(expert_dim, 1) for _ in range(num_tasks)])
def forward(self, x, task_ids):
expert_outputs = []
for expert in self.experts:
expert_output = expert(x)
expert_outputs.append(expert_output)
final_outputs = []
for i, gate in enumerate(self.gates):
# 每个任务的门控网络接收所有专家的输出
gate_input = torch.stack(expert_outputs) # 转换为多任务输入
gate_weights = gate(gate_input)
# 加权求和专家输出
mixed_output = torch.sum(gate_weights.unsqueeze(0) * torch.stack(expert_outputs), dim=1)
# 通过任务特定层进行预测
task_output = self.task_specific_layers[i](mixed_output)
final_outputs.append(task_output)
return final_outputs
# 假设参数
input_dim = 100 # 输入特征维度
expert_dim = 50 # 专家网络输出维度
num_experts = 3 # 专家网络数量
num_tasks = 2 # 任务数量
# 初始化MMoE模型
mmoe_model = MMoE(input_dim, expert_dim, num_experts, num_tasks)
# 假设输入和任务ID
x = torch.randn(10, input_dim) # 假设有10个样本
task_ids = torch.tensor([0, 1, 0, 1, 0, 0, 1, 1, 0, 1]) # 假设的二分类任务ID
# 前向传播
outputs = mmoe_model(x, task_ids)
print(outputs)在这个代码示例中:
Expert类定义了专家网络,它负责学习所有任务共有的特征。Gate类定义了门控网络,它为每个任务分配来自不同专家的输出的权重。MMoE类是整个模型,它包含专家集合、门控集合和任务特定层。
这是一个简化的示例,用于展示MMoE的核心原理。在实际应用中,MMoE模型可能需要更复杂的网络结构、更精细的门控机制和更高级的任务特定层。此外,模型的训练还需要损失函数、优化器和适当的训练循环。
1. MMoE的提出和贡献
MMoE(Multi-gate Mixture-of-Experts)是一种多任务学习模型,由Google的研究团队提出。该模型的核心贡献在于其创新的结构设计,它通过引入多个专家网络(Experts)和门控网络(Gates)来显式地建模不同任务之间的关系,并优化每个任务的表现。
MMoE的主要贡献包括:
-
任务关系建模:
MMoE通过门控网络为每个任务学习如何从多个专家网络中选择有用的信息。这种方法允许模型自动调整参数,以捕获任务之间的共享信息和特定任务的信息。 -
参数效率:
与其他多任务学习方法相比,MMoE避免了为每个任务增加大量新参数的需求。门控网络通常是轻量级的,而专家网络是所有任务共享的,这使得MMoE在参数数量上更加高效。 -
提高模型性能:
在任务之间相关性较低时,MMoE模型能够更好地利用专家网络的信息,从而提高模型的整体性能。 -
改善训练稳定性:
MMoE结构在训练过程中显示出更好的稳定性和收敛性。这与最近的研究表明,调控和控制机制能够提升神经网络在非凸问题上优化的效果是一致的。 -
广泛的应用场景:
MMoE不仅在理论上具有创新性,而且在实际应用中也表现出色。它已被应用于推荐系统等多个领域,证明了其在处理大规模实际问题时的有效性。 -
合成数据集的实验验证:
通过在合成数据集上的实验,MMoE展示了在不同任务相关性水平下的性能,特别是在任务相关性较低时,其性能优势更为明显。 -
实际数据集上的成功应用:
在UCI Census-income数据集和Google内容推荐系统上的实验进一步证明了MMoE模型的有效性。
MMoE模型的提出,为多任务学习领域带来了一种新的视角,特别是在处理任务之间相关性较弱的情况时,展现出了其独特的优势。通过门控网络的机制来平衡多任务的方法,在真实业务场景中具有重要的借鉴意义。
2.论文解读
论文标题
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
摘要解读
这篇论文提出了一种新的多任务学习方法,名为Multi-gate Mixture-of-Experts (MMoE),它能够直接从数据中建模任务之间的关系。MMoE结构通过在所有任务中共享专家子模型,并为每个任务训练一个门控网络,从而适应多任务学习。实验表明,当任务之间的相关性较弱时,MMoE模型优于其他基线方法,并且训练时更容易收敛。
1. 引言
在推荐系统中,多任务学习被用来同时优化多个目标,例如,不仅希望用户购买推荐的视频,还希望他们真正喜欢这些视频。然而,现有的多任务学习模型往往对任务之间的相关性敏感,当任务之间的差异较大时,模型性能会受到影响。因此,如何平衡不同任务之间的目标和关系,成为一个重要问题。MMoE模型通过引入Mixture-of-Experts结构,允许模型自动分配参数来捕获共享任务信息或特定任务信息,避免了为每个任务增加新参数的需求。
2. 相关工作
- 多任务学习在DNN中的应用:多任务学习可以提升模型效率和质量,但共享底层模型参数可能会受到任务冲突的影响。
- 子网络集成和专家混合:集成模型和子网络集成已被证明可以提升模型精度。MoE layer可以根据输入选择不同的子网络(专家),并通过引入稀疏性降低计算成本。
- 多任务学习应用:多任务学习已被成功应用于推荐系统等大规模实际应用中。
3. MMoE模型
MMoE模型的核心是将Mixture-of-Experts结构引入到多任务学习中。它由以下几个关键部分组成:
- 专家子模型(Experts):一组共享的底层网络,每个专家都是一个前馈网络。
- 门控网络(Gating Networks):每个任务都有一个门控网络,它接受输入特征并输出Softmax门控,以不同的权重组合专家的输出。
- 任务特定塔网络(Task-Specific Tower Networks):组合的专家输出被传入特定任务的塔网络,进行最终预测。
MMoE模型允许门控网络学习不同任务的专家组合模式,从而捕获任务之间的关系。
4. 实验
- 合成数据集:作者构建了一个合成实验,通过控制任务之间的相关性,来验证MMoE方法在不同任务关联程度上的效果。结果表明,当任务之间相关性低时,MMoE模型优于其他方法。
- UCI Census-income数据集:在二分类基准测试中,MMoE模型展示了其优越的性能。
- 大规模内容推荐系统:在Google的内容推荐系统上,MMoE模型也表现出了良好的效果。
5. 结论
MMoE模型通过引入多门控混合专家结构,有效地建模了任务之间的关系,并在多任务学习中取得了显著的性能提升。它不仅适用于任务相关性低的场景,而且在训练过程中也显示出更好的稳定性和收敛性。
贡献
- 提出了一种新的多任务学习方法MMoE,能够直接对任务关系建模。
- 在合成数据集上进行实验,展示了任务之间相关性如何影响多任务学习,并解释了MMoE如何提高模型性能和训练稳定性。
- 在真实数据集上进行实验,验证了MMoE模型的有效性。
这篇论文为多任务学习领域提供了一种新的视角和方法,特别是在处理任务之间相关性较弱的情况时,MMoE模型展现出了其独特的优势。

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









