







本文旨在探讨如何利用大型语言模型(LLMs)和金融领域特定的变体FinBERT进行金融情绪分析(FSA)。研究聚焦于新闻文章、财务报告和公司公告中的情绪分析,强调了零样本(zero-shot)和少样本(few-shot)策略下提示工程(prompt engineering)在提升情绪分类准确性方面的优势。实验结果表明,经过金融文本少样本示例微调的GPT-4o在这一专业领域的表现可以与经过良好微调的FinBERT相媲美。
1. 引言
情绪分析在多个领域内用于从文本数据中提取观点和情感,对金融领域尤为重要。它能够提供市场动态、投资者情绪以及新闻事件对金融市场潜在影响的洞察,从而辅助做出明智的决策。然而,FSA面临需要领域特定知识、处理歧义和管理不确定性等挑战。最近,自然语言处理(NLP)领域的进步,特别是LLMs的发展,为克服这些挑战提供了可能。
2. 相关工作
金融情绪分析涉及多种技术和应用。文献综述将其分为三个主要领域:金融中的情绪分析、使用预训练语言模型的文本分类、以及大型语言模型的自监督学习目标。
- 金融中的情绪分析:传统方法包括机器学习,如基于“词袋”模型或词典的方法,以及深度学习方法,如基于嵌入序列的表示。深度学习方法虽然在捕捉特定词序的语义信息方面更为有效,但常因需要大量参数而受到批评。
- 使用预训练语言模型的文本分类:语言模型通过预测文本序列中的下一个词来进行训练。预训练模型在大量语料库上训练后,通过添加适当的任务特定层对目标数据集进行微调,已证明在多种下游NLP任务中有效。
- 大型语言模型:自监督学习目标用于训练LLMs,使其能够掌握句法、语义和语用信息。与传统NLP模型相比,LLMs具有可扩展性、通用性、数据效率和可转移性等优势。
3. 方法论
数据收集和预处理
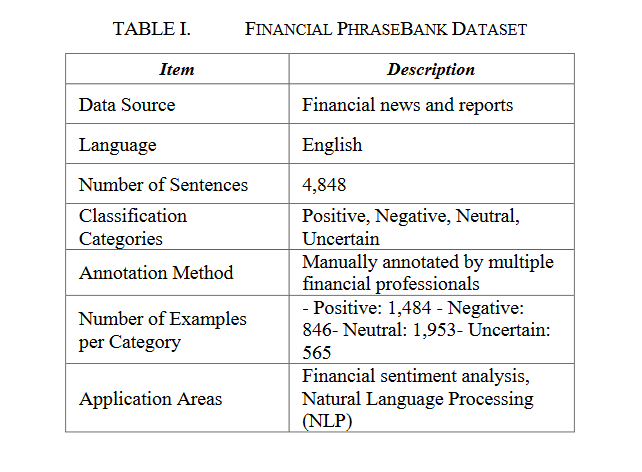
研究使用的主要数据集是Financial PhraseBank,这个数据集包含了4845个英文句子,这些句子是从LexisNexis数据库中的金融新闻中随机选取的。这些句子随后由16位具有财务和商业背景的专业人士进行标注。标注者根据他们认为句子中的信息可能如何影响所提及公司的股价来给出标签。
数据集还包括了标注者之间对句子的一致性水平信息。一致性水平和情绪标签的分布可以在表1中看到。为了创建一个健壮的训练集,研究者将所有句子的20%留作测试集,另外20%的剩余句子用作验证集。最终,训练集包括了3101个示例。在某些实验中,还使用了10折交叉验证。
Financial PhraseBank的标注过程确保了句子的高质量情绪标签,反映了多个标注者之间的共识和个体差异。这种多样性和一致性使得数据集在情绪分析研究中非常可靠和实用。
提示设计
考虑到提示设计的原则,研究创建了零样本和少样本提示。LLMs的任务是使用自然语言指定的。
零样本学习:在零样本学习中,没有提供先前的例子;模型必须根据查询本身推断情绪。

少样本学习:在少样本学习中,提供了多个训练示例以帮助LLMs更好地理解任务。具体来说,包括了九个分类良好的示例——包括三个正面、三个负面和三个中性的新闻和报告及其真实的标签——在提示设计中。

在少样本设置中,对问题进行了微小的调整,以给LLMs提供更详细的指导和规则。零样本和少样本的提示设计分别在图1和图2中说明。
LLMs选择和比较方法
通常,LLMs的选择是基于它们的规模、可用性和任务适用性。在这项实验中,选择了两个最常用且公开可用的LLMs:OpenAI ChatGPT(GPT 3.5)和OpenAI GPT 4。这些对话AI工具会定期更新,因此结果可能会随着未来版本而有所不同。
在Financial PhraseBank数据集上微调的BERT
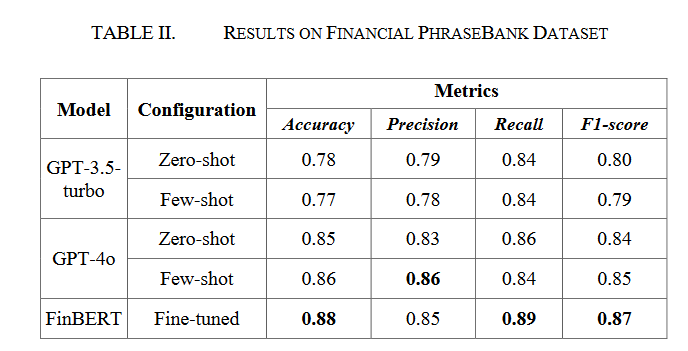
研究还使用了在Financial PhraseBank数据集上微调的BERT,以0.88的准确率返回结果,以便与LLMs进行比较。在FinBERT中,通过在金融语料库上进一步预训练并在情绪分析(FinBERT)上微调,实现了BERT在金融领域的应用。这项工作据作者所知是首次将BERT应用于金融领域,并且是少数几个实验性地在特定领域语料库上进一步预训练的研究之一。FinBERT的结果在表2中给出。
4. 实验和结果
实验部分详细说明了金融情绪分析分类实验的设置和结果。使用了GPT-3.5turbo、GPT-4o和FinBERT等不同配置的模型。
实验设置
实验使用了Financial PhraseBank数据集,包含4848个从金融新闻文章中提取的句子,每个句子都被标注了四个情绪类别之一:正面、负面、中性或不确定。数据被划分为训练集、验证集和测试集,以确保评估的稳健性。具体来说,20%的句子被留作测试集,另外20%的剩余句子用于验证,其余的3101个句子用于训练。
实验涉及了几种不同的模型配置:
GPT-3.5-turbo 和 GPT-4o:这些模型在零样本和少样本的设置中被测试。在零样本设置中,模型没有提供先前的例子,必须基于查询本身推断情绪。在少样本设置中,提供了少量的例子来帮助模型更好地理解任务。
FinBERT:这是一个在金融领域特定语料库上预训练并进一步在Financial PhraseBank数据集上微调的模型,专门用于情绪分类。
结果分析
每个模型配置的性能通过以下四个指标进行评估:
准确率(Accuracy):模型正确分类的样本占总样本的比例。精确度(Precision):模型正确预测为特定类别的样本占模型预测为该类别的所有样本的比例。召回率(Recall):模型正确预测为特定类别的样本占实际为该类别的所有样本的比例。F1分数(F1-Score):精确度和召回率的调和平均值,是一个综合考虑了精确度和召回率的性能指标。
比较分析
实验结果表明,针对特定领域语料库进行微调的FinBERT在金融情绪分析中表现最佳,这归功于其领域特定的预训练,使其能够更好地理解金融语言的细微差别。GPT-4o,凭借其先进的能力,在少样本设置中也表现良好,尤其是在经过金融文本示例微调后,其性能可与经过良好微调的FinBERT相媲美。
实验结果强调了提示工程技术在提升大型语言模型性能方面的潜力,尤其是在少样本设置中。少样本提示为模型提供了更好的上下文,从而实现了更准确和细致的情绪分类。相比之下,零样本设置虽然在一定程度上有效,但由于缺乏必要的上下文,常常无法精确提取情绪,这突显了仅依赖于通用语言模型而不进行微调的局限性。
5. 结论
研究表明,LLMs和FinBERT可以有效地应用于金融新闻文章和报告的金融情绪分析。尽管GPT-3.5turbo和GPT-4o在提示工程技术的帮助下表现有所提升,但经过Financial PhraseBank数据集微调的FinBERT在准确性、精确度、召回率和F1分数方面均优于通用LLMs。这强调了领域特定预训练对于金融情绪分析的重要性。
研究还发现,少样本提示为LLMs提供了更好的上下文,从而实现了更准确和细致的情绪分类。零样本设置虽然在一定程度上有效,但由于缺乏必要的上下文,常常无法精确提取情绪,这突显了仅依赖于通用语言模型而不进行微调的局限性。
尽管领域特定的模型如FinBERT由于其定制的预训练而保持优越,但像GPT-3.5turbo和GPT-4o这样的通用LLMs在金融情绪分析中也显示出潜力。有效的提示工程技术可以显著提高LLMs的性能,使其成为现实世界金融情绪分析应用中的可行工具。未来的工作应继续改进这些模型,并探索创新方法以进一步提高它们的准确性和上下文理解能力。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









