









24年2月上海交大、上海AI实验室、CMU和清华的论文“Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents”。
自动驾驶中的场景模拟因其生成定制数据的巨大潜力而受到极大关注。然而,现有的可编辑场景模拟方法在用户交互效率、多相机照片真实感渲染和外部数字资产集成方面面临限制。为了应对这些挑战,本文介绍ChatSim,通过自然语言命令和外部数字资产实现可编辑照片逼真3D驾驶场景模拟。为了实现具有高命令灵活性的编辑,ChatSim利用一个大语言模型(LLM)智体协同框架。为了生成照片逼真的结果,ChatSim采用了一种多相机神经辐射场NeRF方法。此外,为了释放广泛的高质量数字资产的潜力,ChatSim采用一种多摄像机光照估计方法来实现场景一致资产的渲染。在Waymo开放数据集上的实验表明,ChatSim可以处理复杂的语言命令,并生成相应的照片逼真的场景视频。代码可访问:GitHub - yifanlu0227/ChatSim
如图所示:通过语言命令编辑照片逼真的3D驾驶场景模拟。
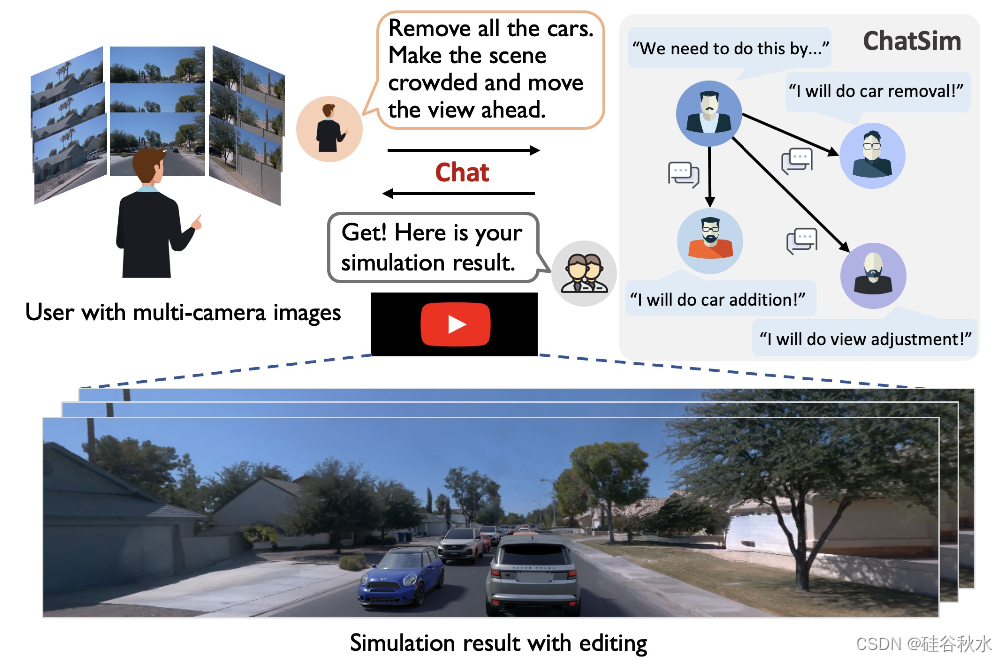
下表是自动驾驶仿真方法的比较:
ChatSim系统分析特定的用户命令,并返回满足定制需求的视频;如图所示。由于用户命令可能是抽象和复杂的,因此要求系统具有灵活的任务处理能力。直接应用单个LLM智体很难进行多步骤推理和交叉引用。为了解决这个问题,设计了一系列协作LLM智体,其中每个智体负责编辑任务的一个独特方面。
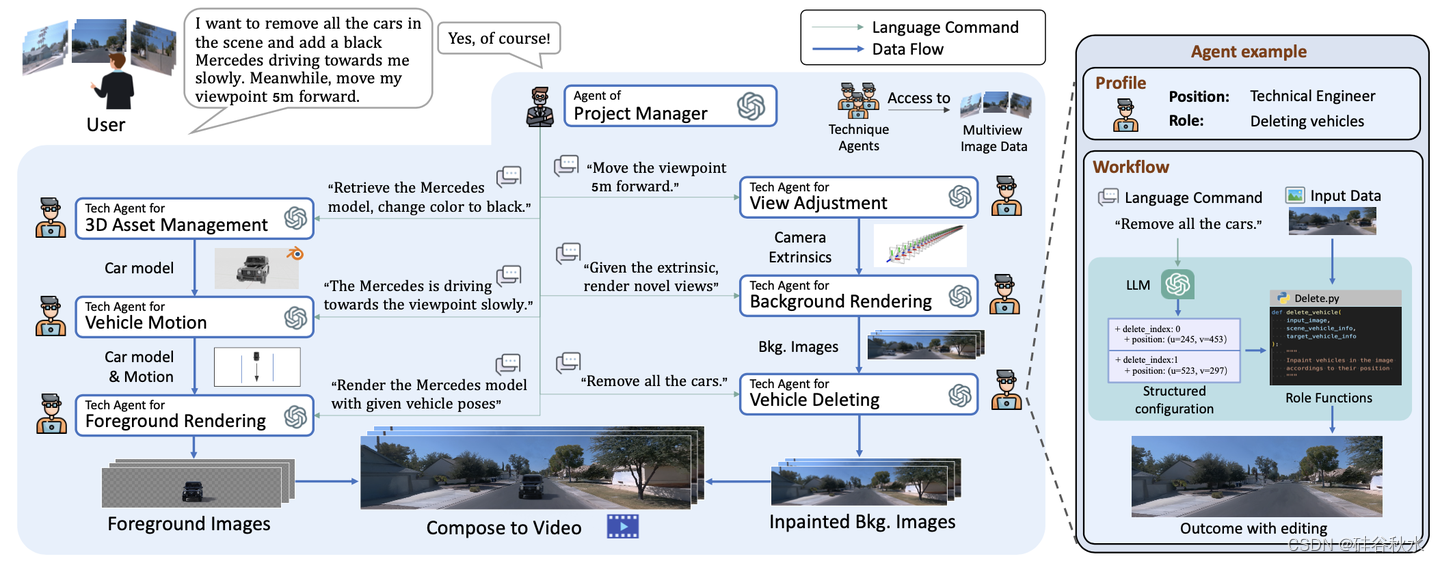
ChatSim中的智体包括两个关键组件:大语言模型(LLM)和相应的角色功能。LLM负责在角色功能处理接收数据时理解接收命令。每个智体都配备了独特的LLM提示和角色功能,以适应其在系统中的特定职责。为了完成任务,智体首先在提示的帮助下使用LLM将接收到的命令转换为结构化配置。然后,角色函数利用结构化配置作为参数来处理接收到的数据并产生期望的结果;请参见图右的智体示例。此工作流同时具有语言解释功能和精确执行功能。
LLM智体由其LLM(大语言模型)组件和相应的功能组成。所有实验都使用GPT-4 API来实现LLM部分。在每个智体的提示中,都有一些元素涉及智体的功能、智体需要执行的动作的定义、输入到智体的信息的定义以及智体所需输出的定义。为了便于Python代码的集成并确保稳定的调用,LLM部分需要以JSON字典的格式返回信息。此外,每个LLM部分的提示都包括一些示例,其中包含某些场景的输入和相应的预期输出。如果输入命令不包含输出JSON字典的键的信息,则字典中将填充默认的键。与GPT-4 API相关的参数均设置为官方默认值。
注意,为了支持多轮命令期间的修改操作,3D资产管理智体、车辆运动智体和车辆删除智体具有修改已经添加或删除的车辆的信息的能力。
项目经理智体。项目经理智体将直接命令分解为发送给其他编辑智体的清晰自然语言指令。为了使项目经理智体具有命令分解的能力,为其LLM设计了一系列提示。提示的核心思想是描述动作集,给出总体目标,并用示例定义输出形式;角色函数将分解后的指令发送给其他智体进行编辑。项目经理智体的存在增强了系统在解释各种输入时的稳健性,并简化了操作,以获得清晰和精细的粒度。
视图调整的技术智体。视图调整智体生成合适的外部摄像头参数。智体中的LLM,将用于视点调整的自然语言指令翻译成目标视点的位置和角度的运动参数。在角色函数中,这些运动参数被转换为外部参数所需的变换矩阵,然后将其乘以原参数以产生新的视点。
如图是智体LLM提示例子:

背景渲染的技术智体。背景渲染智体基于多摄像机图像渲染场景背景。LLM接收渲染命令,然后操作角色函数进行渲染。值得注意的是,在角色函数中,专门集成了一种多摄像头神经辐射场方法(McNeRF),该方法采用多相机输入并考虑曝光时间,解决了多摄像头渲染中的模糊和亮度不一致问题。
删除车辆的技术智体。车辆删除智体从背景删除指定的车辆。它首先从给定的场景信息或场景感知模型(如[43])的结果中识别当前的车辆属性,如3D边框和颜色。LLM收集车辆的属性并执行与用户请求的匹配。在确认目标车辆后,它采用每帧修复模型作为角色函数,如latent diffusion方法[52],有效地将其从场景中删除。
3D资产管理的技术智体。3D资产管理智体根据用户规范选择和修改3D数字资产。它构建并维护一个3D数字资产库。为了便于添加各种目标,智体首先使用LLM通过与需求匹配的关键属性(如颜色和类型)来选择最合适的资产。如果匹配不完美,智体可以通过其角色功能(如更改颜色)来修改资产。
车辆运动的技术智体。车辆运动智体根据请求创建车辆的初始位置和随后的运动。现有的车辆运动生成方法不能直接从文本和场景地图生成运动。为了解决这个问题,提出一种文本到运动的方法。关键思想是将位置和规划模块作为角色函数与LLM联系起来,提取运动属性并将其转化为坐标。运动属性包括位置属性(如距离、方向)和运动属性(如速度、动作)。对于放置模块,为车道线地图中的每个车道线节点赋予其属性,与位置属性相匹配。规划模块规划车辆的近似目标车道线节点,然后通过拟合贝塞尔曲线来规划中间轨迹。还添加了轨迹跟踪,适应车辆动力学。
前景渲染的技术智体。前景渲染智体集成相机外部信息、3D资产和运动信息,以渲染场景中的前景目标。值得注意的是,为了将外部资产与当前场景无缝集成,将多摄像机照明估计方法(McLight)与McNeRF相结合,设计到角色函数中。然后,Blender API利用估计的照明来生成前景图像。
具有定制功能的智体协同工作,根据用户命令进行编辑。项目经理智体协调并向编辑智体发送指令。编辑智体组成两个团队:背景生成和前景生成。对于背景生成,背景渲染智体使用来自视图调整智体的外部参数生成渲染图像,然后由车辆删除智体进行修复。对于前景生成,前景渲染智体使用来自视图调整智体的外部参数、来自3D资产管理智体选定的3D资产以及来自车辆运动智体生成的运动来渲染图像。最后,合成前景和背景图像创建视频并将其传递给用户。每个智体配置中的编辑信息由项目经理智体记录,用于可能的多轮编辑。
基于协作LLM智体框架,采取两种渲染技术,增强模拟中的照片真实性。为了解决多个摄像头引起的渲染挑战,提出了多摄像头神经辐射场(McNeRF),考虑了不同的摄像头曝光时间以实现视觉一致性。为了使用特定位置的照明和精确的阴影渲染逼真的外部数字资产,提出了McLight,这是一种与McNeRF相结合的混合照明估计方法。请注意,背景渲染智体和前景渲染智体分别利用McNeRF和McLight。
如图为渲染框架示意图。主要组件包括McNeRF和McLight。背景渲染使用McNeRF来预测HDR像素值,并使用sRGB OETF将其转换为LDR。McLight包括一个天穹照明估计网络,并采用McNeRF来生成周围的照明。
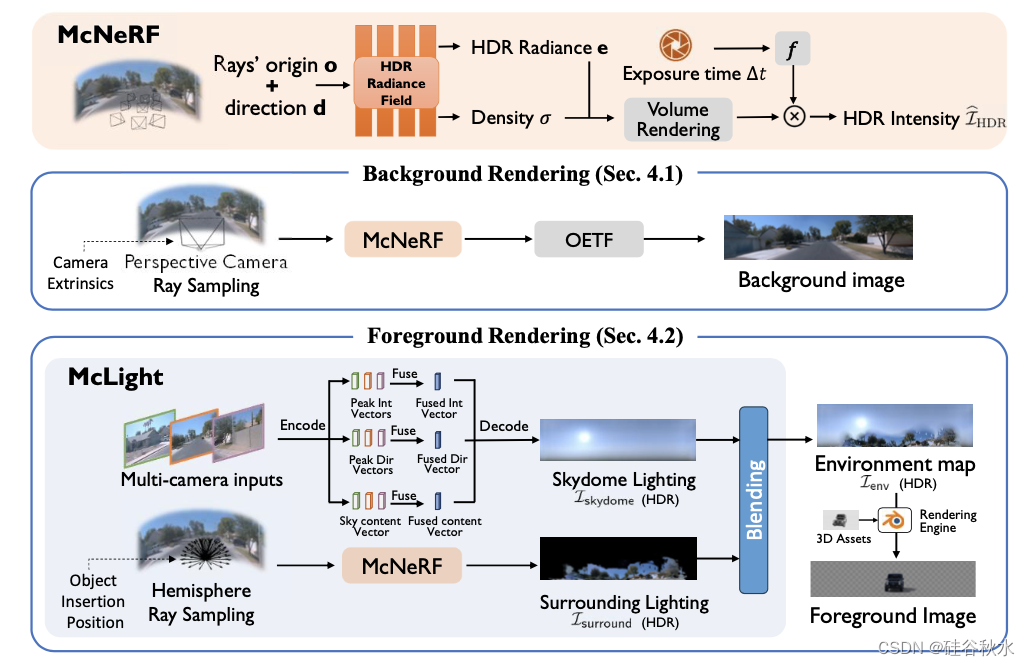
McNeRF模型利用CVPR‘23 论文“F2- nerf: Fast neural radiance field training with free camera trajectories”的主干网络。
McLight是一种混合照明估计,由天穹照明和周围照明组成。
天穹亮度估计采用两步的过程。在第一步,训练自动编码器从LDR全景重建相应的HDR全景。在McLight模型中天穹光照估计采用了ECCV‘22论文“Neural light field estimation for street scenes with differentiable virtual object insertion”的方法,编码器将LDR(低动态范围)天穹全景图转换为三个中间矢量,包括峰值方向矢量、亮度矢量和天空内容矢量。然而,由于HDR(高动态范围)亮度在其峰值位置表现得像脉冲响应,像素值比其邻域高数千倍,解码器很难恢复这种模式。为了解决这个问题,设计了一个残差连接,将亮度矢量注入到具有球面高斯波瓣衰减的解码HDR全景中。这明确地恢复了重建的HDR全景中太阳的峰值亮度,能够为虚拟目标渲染强烈的阴影。 在第二步,在第一步预训练解码器的基础上训练图像编码器和多摄像机融合模块。
McNeRF能够存储精确的3D场景信息,能够捕捉周围场景对照明的影响。这种方法有助于实现随空间变化的照明估计。通过McNeRF的最终采样点透射率来混合来自天穹和周围照明的HDR强度值。想法是,辐射场外发射的光线肯定会击中天穹。
如图是LDR到HDR重建网络。添加了一个显式的球面高斯波瓣编码衰减来克服解码HDR全景中的过平滑。它可以有效地确保太阳的亮度大大超过周围像素的强度,从而为插入的目标渲染强烈的阴影效果。
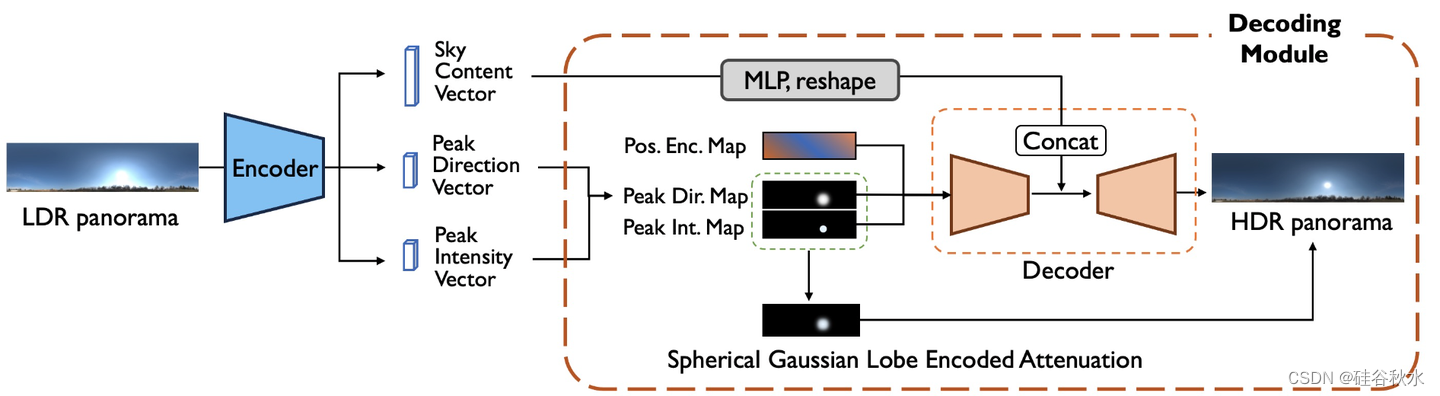
如图所示是从多摄像头图像重建HDR天穹框架图,模型在HoliCity数据集进行训练。


















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









