







前言
CARLA没有直接的方法给使用者查找地图坐标点来生成车辆,这里推荐两种实用的方法在特定的地方生成车辆。
一、通过Spectator获取坐标
1、Spectator(观察者),我们通过键盘的W A S D按键以及鼠标的左键可以移动Carla Client的画面,实际移动的是Spectator的位置。
2、假设我们将Spectator通过W A S D按键以及鼠标移动到当前的位置,按键调整的是(x,y,z)位置,鼠标调整的是(pitch,yaw,roll)。

3、执行下述代码,通过API获取当前Spectator位置,再将车辆生成到当前位置。
import carla
client = carla.Client('localhost', 2000)
carla_world = client.get_world()
#获取CARLA世界中的spectator
spectator = carla_world.get_spectator()
transform = spectator.get_transform()
print(transform)
#打印:Transform(Location(x=115.515007, y=-16.447723, z=1.146989), Rotation(pitch=10.587230, yaw=-3.618074, roll=0.000049))
#生成车辆
blueprint = carla_world.get_blueprint_library().filter('vehicle.*')[0]
ego = carla_world.spawn_actor(blueprint, transform)

二、通过道路ID获取坐标
1、假设你有roadrunner,打开carla的xodr地图,选中任意车道,你会发现右侧有road id = 17和lane id = -5,有了这两个参数就好办了。xodr地图路径在 D:\CARLA_0.9.14\WindowsNoEditor\CarlaUE4\Content\Carla\Maps\OpenDrive)
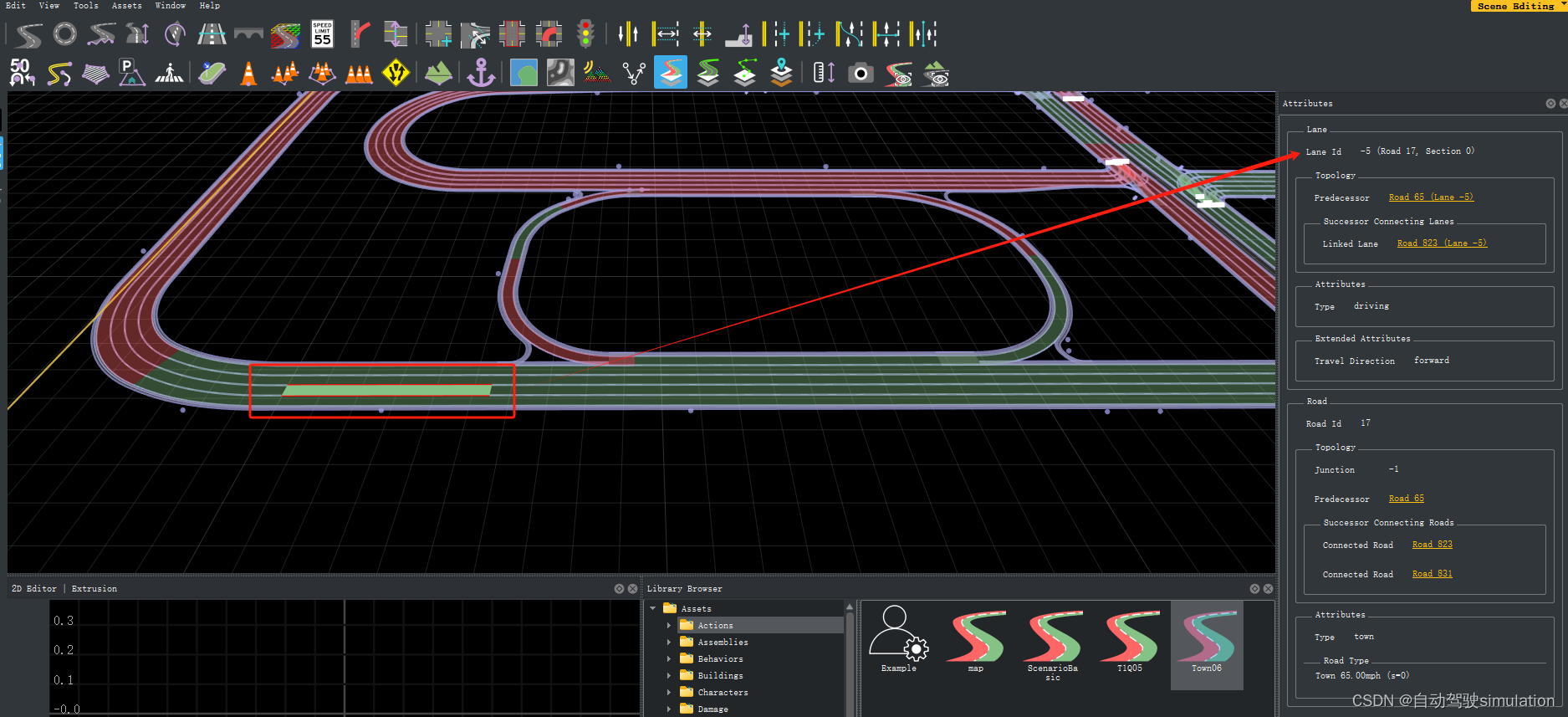
2、通过代码直接生成到目的道路和车道。
import carla
client = carla.Client('localhost', 2000)
carla_world = client.get_world()
target_road_id = 17
target_lane_id = -5
#获取carla地图
map = carla_world.get_map()
# 每隔2m生成1个waypoint
waypoints = map.generate_waypoints(2.0)
# 遍历路点
ego = None
for waypoint in waypoints:
if waypoint.road_id == target_road_id:
lane_id = waypoint.lane_id
# 检查是否已经找到了特定车道ID的路点
if lane_id == target_lane_id:
location = waypoint.transform.location
#稍微设置一下z坐标,如果z为0的话,车会掉下去。
location.z = 1
ego_spawn_point = carla.Transform(location, waypoint.transform.rotation)
print(ego_spawn_point)
#生成车辆
blueprint = carla_world.get_blueprint_library().filter('vehicle.*')[0]
ego = carla_world.spawn_actor(blueprint, ego_spawn_point)
break
#这里补充观察者代码
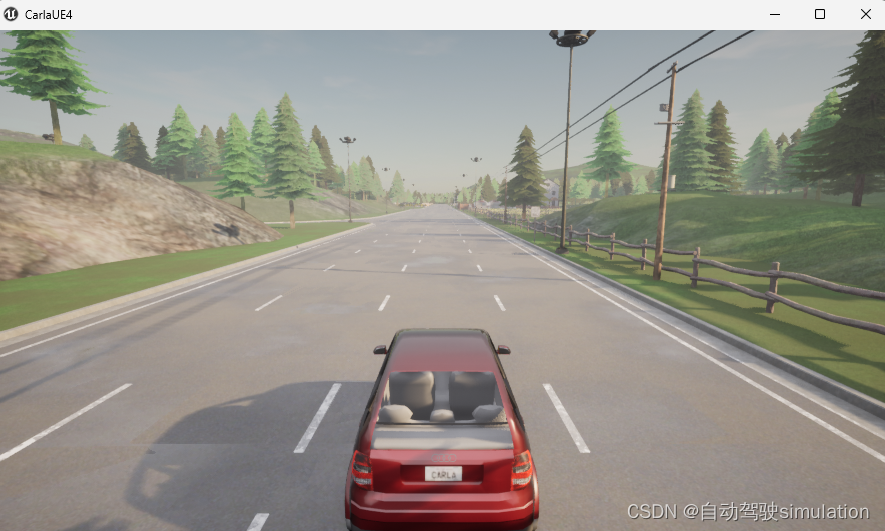
3、上面的代码已经生成了车辆到指定的road id 和 lane id的位置,我们现在可以设置一个spectator看看车辆有没有在目的地,这部分代码和上面的代码一起执行。
# 顺便搞个观察者安装到车辆,看看车到了目标点没有
camera_bp = carla_world.get_blueprint_library().find('sensor.camera.rgb')
# 设置生成Camera的附加类型为Rigid
Atment_SpringArmGhost = carla.libcarla.AttachmentType.Rigid
# 设置Camera的安装坐标系
Camera_transform = carla.Transform(carla.Location(x=-5, y=0, z=2),
carla.Rotation(pitch=-10, yaw=0, roll=0))
# 生成Camera
camera = carla_world.spawn_actor(camera_bp, Camera_transform, attach_to=ego,
attachment_type=Atment_SpringArmGhost)
#设置spectator坐标
carla_world.get_spectator().set_transform(camera.get_transform())

总结
roadrunner网上比较多资源,也比较容易安装,可以绘制日常仿真使用的地图,有时间的可以安装学习一下。


















 254
254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











