









前言:
画图挺好:深度学习进阶之路-从迁移学习到强化学习
固定知识系统:专家系统给出了知识节点和规则。专家系统一次性构建成型。运行方式为基于知识的推理。
专家系统使用粒度描述准确性,依靠分解粒度解决矛盾,并反馈知识和推理规则更新。专家系统与机器学习有本质区别,但从机器学习的角度看,专家系统是一个给出了规则/函数又给了函数参数的学习模型,是一个推理系统,其直接影响是泛化性能极差,容易导致矛盾。这样,每一个专家系统的更新都涉及到知识节点(规则参数)的分解重构,形式上等价于函数复合化。
专家系统的此时最先进代表方向为知识图谱,知识图谱包含了特定领域的知识图和基于知识图的推理机制。专家系统的推理机制基于归纳法,而知识思想为遍历。机器学习则对知识进行归纳到假设空间,并称之为模型。
固定框架系统:机器学习系统把知识系统映射到一个函数空间,由专家设置函数集形式-依据假设空间(框架)。机器学习系统基于定义域内数据使用优化方法进行参数学习。运行方式为数学计算。
机器学习系统设计也遵循了模式识别的一般构架与过程。一般在特定或者广泛的应用领域,先给出目标/评价函数,以期待完成预期的结果。再依据目标/评价函数设计满足目标函数的规则系统/数学模型,以期待能完成目标函数所要求的功能。而应对与每个领域,由实体到数学模型的转化,产生了一个特征描述的专家过程,把领域实体表示为学习系统可以接受的输入数据。
监督与非监督:机器学习划分出的非监督学习与监督学习,在于是否使用了示例来指导数学模型的优化过程。监督学习给出了形式化的目标函数,形式化的数学模型,形式化的特征提取过程,并且给出了同伦映射空间模型参数的一些阈值确界,学习过程是通过阈值确界通过目标函数约束来优化数学模型的过程。非监督学习没有给出模型参数阈值,但依然有形式化的目标函数,形式化的数学模型和形式化的特征提取过程,主要通过目标函数和数学模型精细结构调整来达到预期目标。
传统的机器学习系统是一个模型逐渐优化的学习系统,学习的终极目标是收敛到一个最优解,期待是确定的数学模型。传统的ML系统方法期待模型直接学习到模式的空间结构,并得到空间结构的等价模型映射,相对于任意模型,学习到的模型是e精度最优的,即是e精度最接近的,这就意味着最大的准确率和最大的泛化性能。
固定数据集-环境-空间假设:专家系统和机器学习模型依赖于人类专家的固定环境-数据定义域假设。都是一个运行时固定系统,即离线学习系统,是完全的经验模型。专家系统通过专家构建成型,而机器学习系统通过专家构建假设空间映射到函数模型再经过数据训练调优成型,运行时都不再修改。
在线学习系统:以模型作为Agent,有时需要面对新的环境,或者在固有环境中存在未被专家所归纳的因素,或者定义域界限产生了扩延,离线模型可能产生新的构架错误、经验错误。截断错误。因此,需要模型有一定的可修正能力,产生在线模型。跨越到连接主义的范畴,强化学习是一个反馈式学习系统,其期待是一个不断根据反馈进行优化的模型,是在线学习模型。
专家系统由专家构建明确的推理规则和知识节点,模型约束为逻辑约束;监督学习构建明确的函数模型和模型参数,模型约束为拓扑约束;非监督学习形式与监督学习不同而结果相同。强化学习系统附加了一个强化规则/函数,用于实时更新模型。
专家系统、机器学习系统可以构建一个反馈系统的外围,构建一个强化学习系统,以应对交互和反馈、以及时序输入和在线模型更新。
关于探索:作为可在线学习的主动强化学习与被动强化学习,区别在于是否采用了“策略探索”方法。参考小品文:强化学习的分类。被动强化学习使用价值评价,通过在线更新模型参数修改最优解;主动强化学习使用策略评价,对行为策略进行寻优,相当于直接修改了函数空间,因此不再是标准归纳学习。
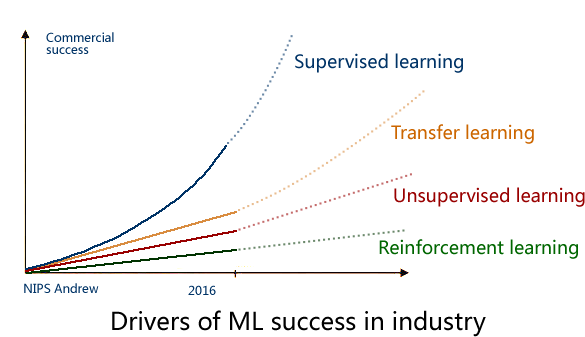
2016年的 NIPS 会议上,吴恩达 给出了一个未来 AI方向的技术发展图
被动强化学习:
直接抄书.....
摘抄于:AI:A Modern approach 第三版
reinforcement learning-RL又称为评价学习,在传统ML领域不存在此种概念,接近于在线弱监督学习。在连接主义学习中,ML划分为监督学习、非监督学习、强化学习RL。
本章主要讲Agent如何从成功与失败中、回报与惩罚中进行学习。
reinforcement learning的任务是利用观察到的回报来学习针对每个环境的最优或者接近最优策略。在此,Agent没有完整的环境模型或者回报函数 两者的先验知识。RL囊括了人工智能的全部,一个Agent被置于一个环境中,并学会在其间游刃有余。
强化学习,致使Agent面临一个未知的马尔科夫过程。
被动强化学习:
在完全可观察环境的状态下使用基于状态表示的被动学习。在被动学习中,Agent的策略是Pi是固定的:在状态s中,它总是执行行动Pi(s)。
其目标只是简单的学习:该策略有多好,即是学习效用函数U(s).
被动学习的任务类似于 策略评价 任务。
1、直接效用估计
由widrow和hoff在1950s末末期在自适应控制理论里面提出的 直接效用估计。思想为:认为一个状态的效用是从该状态开始往后的期望总回报,二每次实验对于每个被访问状态提供了该值的一个样本。
直接效用估计使RL成为监督学习的一个实例,其中每一个学习都以状态为输入,以观察得到的未来回报为输出。此时,RL已经被简化为 标准归纳学习问题。
后记:作为作准归纳学习的直接效用估计,是稳定的且收敛的。
2、自适用动态规划
直接效用估计DUE.(direct utility estimatation )将RL简化为归纳学习问题(决策树?),基于它忽略了一个重要的信息来源:状态的效用并非相互独立的。每个状态的回报等于它自己的回报加上其后记状态的期望效用,即是,效用值服从固定策略的贝尔曼方程:

动态规划方程
忽略了状态之间的联系,直接效用估计错失了学习的机会。并且,直接效用估计可视为在比实际大得多的假设空间中搜索U,其中包括了违反Berman方程组的函数,因此DUE.算法收敛的非常慢。
自适应动态规划ADP.(Adaptive Dynamic program),Agent通过学习连接状态的转移模型,并使用动态规划方法来求解Markov过程,来利用状态效用之间的约束。
后记:作为规划过程的自适应动态规划,整个过程是不稳定的,且收敛性更不确定。
3、时序差分学习
时序差分学习TD.(Timporal-difference)
求解前一节内在的MDP并不是让Berman方程来承担学习问题的唯一方法。另外一种方法是:使用观察到的转移来调整观察到的状态的效用,使得它满足约束方程。
................................
ADP方法和TD方法实际上是紧密相关的。二者都试图对效用估计进行局部调整,以使每一状态都与其后继状态相“一致”。一个差异在于 TD调整一个状态使其与所有已观察的后继状态相一致,而ADP则调整该状态使其与所有可能出现的后继状态相一致,根据概率进行加权。.......
..................
演化出的近似ADP算法可以提高几个数量级的运算速度,然后......
后记:
时序差分学习的学习对象是所有已观察状态,所以预计的结果是有偏的。















 2444
2444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









