






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

2025年4月30日,阿里巴巴Qwen团队发布了新一代多模态模型Qwen2.5-Omni-3B,专为在消费级GPU上部署多模态AI任务而设计。此版本在大幅降低显存占用的同时,保留了接近7B模型的性能,解决了多模态基础模型部署中的关键难题——硬件门槛过高、资源消耗过大,为开发者和研究者提供了更具实用性与普及性的AI工具。
多模态模型部署的瓶颈与现实需求
尽管当前多模态基础模型已在文本、图像、音频与视频推理中展现出强大潜力,但其部署普遍依赖高端GPU与大规模计算资源,这对教育机构、中小型企业及个人开发者构成明显壁垒。尤其在边缘部署、实时交互系统与长上下文处理场景中,传统模型往往因显存溢出或推理延迟而难以胜任。因此,构建具备多模态能力与资源效率兼备的轻量级模型架构成为当前AI技术落地的关键方向。
Qwen2.5-Omni-3B发布:高效架构推动多模态普及
作为Qwen2.5-Omni家族的新成员,Qwen2.5-Omni-3B具备30亿参数规模,面向具备24GB显存的消费级GPU(如NVIDIA RTX 4090)进行深度优化,提供一套低资源门槛下运行多模态系统的现实解决方案。模型现已在GitHub、Hugging Face与ModelScope等平台开放获取,支持语言、视觉与音频统一输入接口,可处理长文本、多轮对话与实时语音视频互动任务。
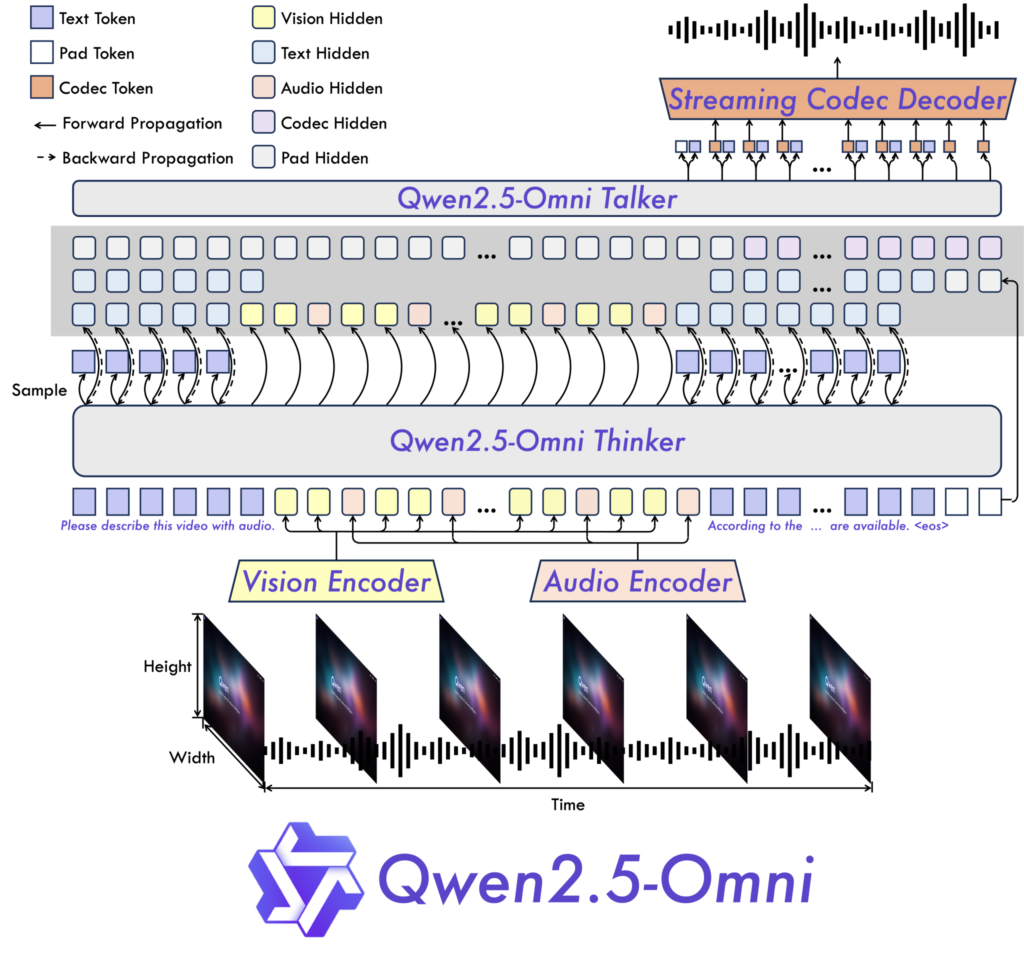
技术架构亮点与关键特性
Qwen2.5-Omni-3B基于Transformer架构,采用模块化设计思路,不同模态通过专属编码器统一接入共享主干网络。其在性能压缩的同时最大限度保留了7B版本的多模态理解能力,尤其在显存优化方面表现突出:
- 显存占用降低超50%:在处理长序列(约25K tokens)时,显存负载显著低于主流7B模型,实现大规模上下文处理的轻量部署;
- 支持长上下文输入:适合处理长文档推理、视频字幕理解、跨时间轴语义分析等任务;
- 多模态实时流处理:支持最长30秒的语音与视频对话输入,在交互场景下保持稳定响应、低延迟与语义一致性;
- 多语言与自然语音生成支持:具备自然语言输出能力,语音清晰度与语调控制接近7B模型,适用于语音助手与人机接口。
评估表现与实际应用反馈
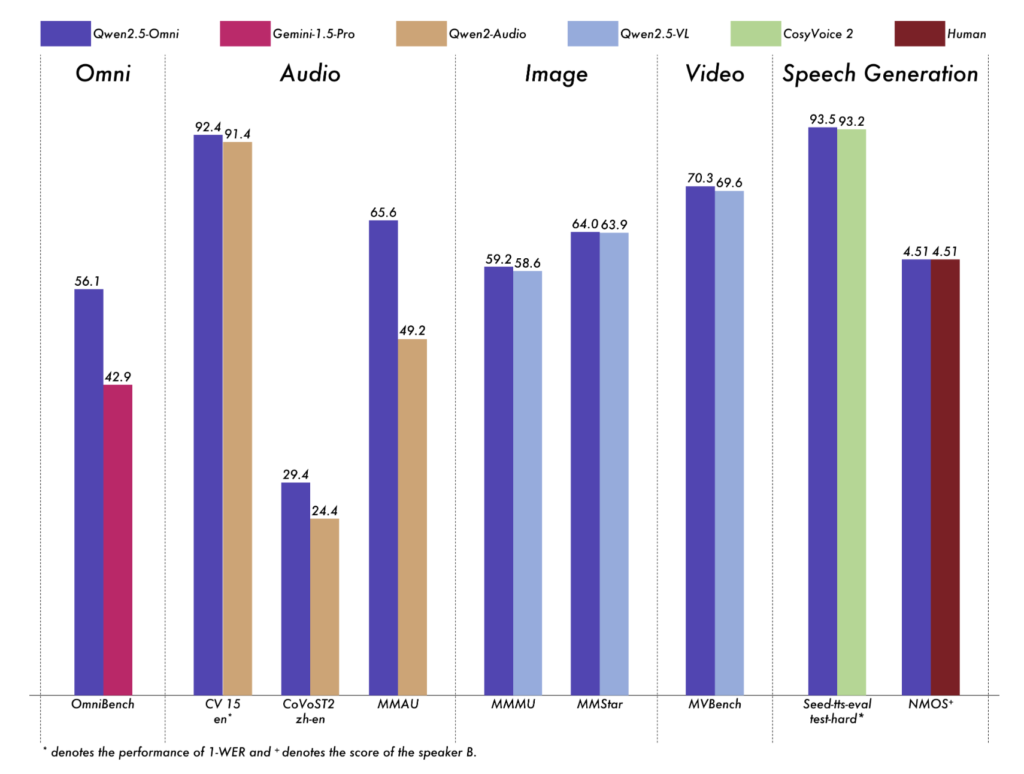
根据ModelScope与Hugging Face平台公布的评估结果,Qwen2.5-Omni-3B在多模态任务中的理解性能可达7B模型的90%以上。在视觉问答(VQA)、音频描述生成、视频理解等任务中,其表现与7B版本高度接近,同时推理效率显著提升。
在长文本处理方面,Qwen2.5-Omni-3B在25K token长度下依然保持稳定,适用于法律文档、技术手册及多轮对话摘要等高上下文需求场景。在语音对话方面,模型可连续处理30秒输入,生成逻辑连贯、语调自然的语音输出,适应智能客服、语音助手等实时系统。
虽然3B参数在生成丰富度与高精度任务上略逊于7B模型,但在计算资源受限的开发环境中,其性能/资源比极具竞争力。对开发者而言,这意味着更低的部署门槛、更高的实验灵活性,以及更多样的场景适配能力。
结语:推动高效多模态AI走向大众
Qwen2.5-Omni-3B代表了当前多模态AI技术发展的重要方向——在保持多模态能力的基础上,优化每单位资源的性能输出,为开发者、学生及中小企业提供了具备“实用性、开放性与可部署性”的AI工具。
在边缘计算、教育辅助、人机交互、法律分析等场景中,对低资源、高精度多模态模型的需求正快速增长。Qwen2.5-Omni-3B的推出,不仅解决了GPU可及性限制,也为未来构建高性价比的多模态AI系统提供了新范式。随着多模态交互与长上下文对话需求不断扩展,此类紧凑型模型将在实际应用中扮演愈发关键的角色。

















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









