






2025深度学习发论文&模型涨点之——ResNet+Transformer
ResNet和Transformer是深度学习领域中的两个非常重要的架构。ResNet(残差网络)以其深层架构和残差连接而闻名,能够有效提取图像的局部特征。而Transformer则以其自注意力机制为核心,能够捕捉序列中的长距离依赖关系,尤其在自然语言处理领域取得了巨大成功。将这两种架构结合起来,旨在充分利用CNN的局部特征提取能力和Transformer的全局建模能力,以期在复杂视觉任务中取得更好的性能。
ResNet和Transformer的结合可以在多个领域提供强大的性能,尤其是在图像分类、目标检测、语义分割等任务中。通过结合这两种架构,模型不仅能够提取图像的局部细节特征,而且能够从全局角度理解图像的语义信息,从而更准确地进行分类和识别。
论文精选
论文1:
A Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Classification of Chest Diseases
CNN、ResNet和视觉变换器在胸部疾病多分类中的比较研究
方法
-
Convolutional Neural Networks (CNNs):使用Keras Sequential模型构建,包含多个卷积层、最大池化层、Flatten层、Dense层,用于从胸部X光图像中提取特征。
-
Residual Networks (ResNet):使用跳跃连接来训练非常深的网络,解决传统深度CNNs中可能出现的梯度消失问题。
-
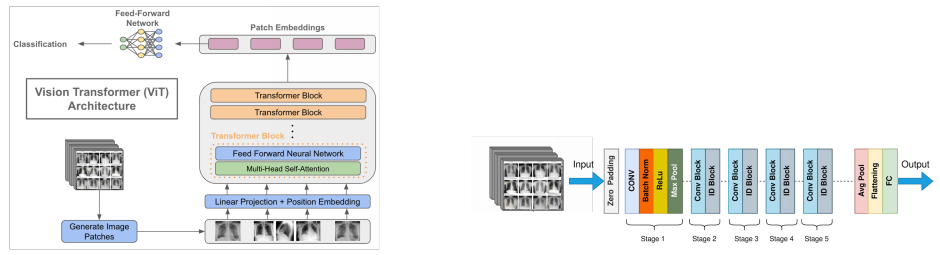
Vision Transformers (ViTs):利用变换器架构处理224×224像素的图像,将图像分割成32×32的patches作为tokens,然后通过多头注意力机制和多层感知器进行分类。
创新点
-
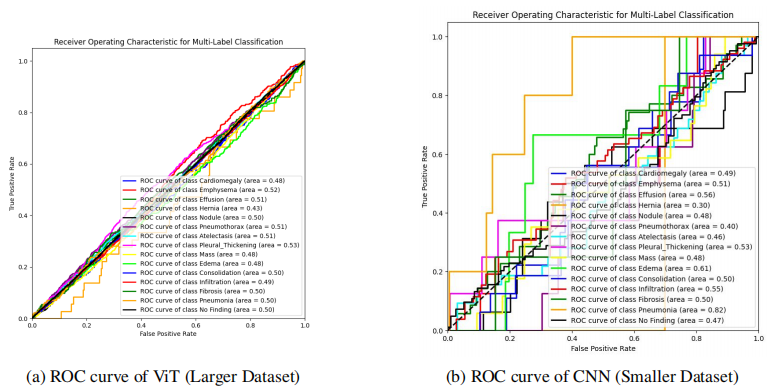
预训练ViT模型:通过在ImageNet上预训练的ViT模型在多标签分类任务中超越了CNN和ResNet,突出了其在胸部X光图像中诊断各种肺部疾病潜力。
-
多标签分类:研究评估了这些模型在14种不同疾病上的多标签分类性能,这对于医学图像分析中的疾病分类具有重要意义。
-
模型比较:提供了CNN、ResNet和ViT在胸部疾病多分类任务中的性能比较,为未来的研究和应用提供了参考。
论文2:
A Three-Dimensional ResNet and Transformer-Based Approach to Anomaly Detection in Multivariate Temporal–Spatial Data
基于三维ResNet和变换器的多变量时空间数据异常检测方法
方法
-
三维映射:将多变量时间序列数据映射到三维空间,以捕获时间序列数据的时间-空间相关性。
-
时间序列嵌入:通过四个堆叠的三维卷积层来学习时间序列的低维嵌入,捕获时间序列的顺序信息和时间序列维度之间的关系。
-
注意力学习:使用变换器编码器来学习时间序列的注意力权重,以识别异常行为。
创新点
-
同时考虑时间序列的顺序信息和维度间关系:提出了一种新的方法,可以同时提取时间序列的时间和空间特征,而不是分开处理。
-
应用注意力机制到三维卷积神经网络:提出了一种新的方法将注意力机制应用于三维卷积神经网络,提高了异常检测的准确性。
-
自动选择时间窗口大小:提出了一种自动选择时间窗口大小的方法,称为TDRT变体,这在不同数据集上提供了显著的性能优势。
论文3:
Combining ResNet and Transformer for Chinese Grammatical Error Diagnosis
结合ResNet和Transformer进行中文语法错误诊断
方法
-
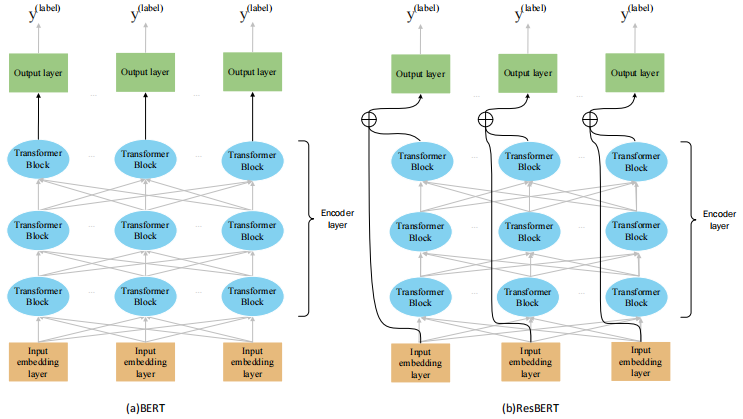
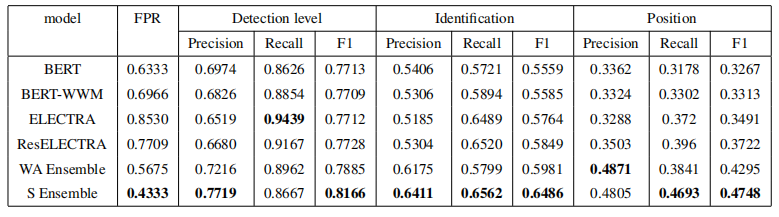
错误检测:系统基于多层双向Transformer编码器构建,并将ResNet集成到编码器中以提高性能。
-
逐步集成选择:探索从模型库中逐步集成选择,以提高单一模型的性能。
-
错误纠正:设计了两个模型分别推荐S型(词选择错误)和M型(遗漏词错误)错误的纠正。
-
RoBERTa和n-gram语言模型:用于S型错误的纠正,结合了预训练的RoBERTa模型和n-gram语言模型。
-
预训练掩码语言模型和统计语言模型:用于M型错误的纠正,结合了预训练的掩码语言模型和统计语言模型。
创新点
-
ResNet与Transformer的结合:通过将ResNet集成到Transformer编码器中,提高了错误检测的性能。
-
逐步集成选择:提出了一种从模型库中逐步选择模型的方法,以提高模型在错误检测中的性能。
-
针对性的错误纠正模型:为S型和M型错误分别设计了纠正模型,提高了纠正的准确性和效率。
-
RoBERTa和n-gram的结合使用:在S型错误的纠正中,结合了RoBERTa模型和n-gram语言模型,提高了纠正的准确性。
-
预训练模型的创新应用:在M型错误的纠正中,创新性地结合了预训练掩码语言模型和统计语言模型,以生成可能的纠正结果。
论文4:
Comparing the Robustness of ResNet, Swin-Transformer, and MLP-Mixer under Unique Distribution Shifts in Fundus Images
比较ResNet、Swin-Transformer和MLP-Mixer在眼底图像独特分布偏移下的鲁棒性
方法
-
EyePACS数据集的使用:使用EyePACS数据集进行糖尿病视网膜病变(DR)诊断。
-
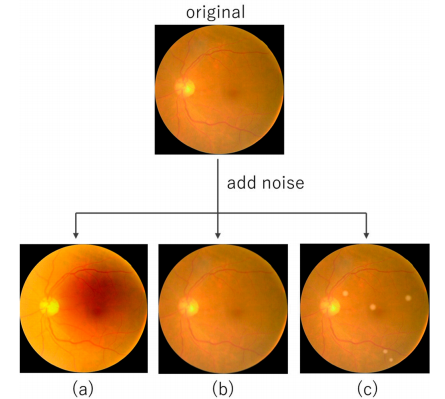
引入眼底图像特定噪声:在数据集中引入眼底图像特有的噪声,评估模型在分布偏移下的性能。
-
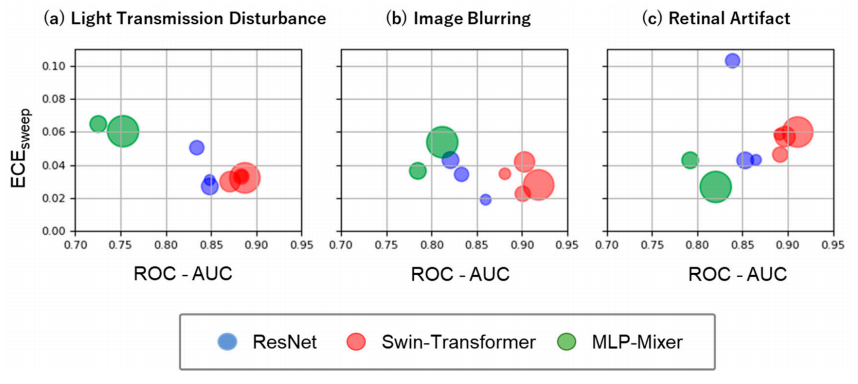
ROC-AUC和ECE sweep评估:使用ROC-AUC评估模型的判别能力,使用ECE sweep评估模型的校准能力。
-
分布偏移的模拟:通过引入三种类型的噪声模拟现实世界中的分布偏移。
创新点
-
针对医学图像的数据集研究:专注于使用医学图像数据集(EyePACS)来研究模型在分布偏移下的性能,填补了自然图像数据集研究的空白。
-
模型鲁棒性的比较:比较了ResNet、Swin-Transformer和MLP-Mixer在眼底图像独特分布偏移下的鲁棒性,为医学图像诊断提供了重要的参考。
-
特定噪声的引入:引入了特定于眼底图像的噪声,更真实地模拟了现实世界中的分布偏移情况。
-
校准能力的评估:使用ECE sweep而不是传统的ECE来评估模型的校准能力,提供了更低偏差的校准误差估计。

















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









