






航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——注意力机制+傅里叶变换
近年来,注意力机制与傅里叶变换的交叉融合已成为深度学习与信号处理领域的前沿研究方向。注意力机制通过动态权重分配显著提升了模型对关键特征的捕获能力,而傅里叶变换则从频域视角为信号建模提供了全局性分析框架。两者的结合不仅克服了传统卷积操作的局部性限制,更在长程依赖建模、计算效率优化以及多尺度特征提取等方面展现出理论优势。
我整理了一些【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文精选
论文1:
Fourier Position Embedding: Enhancing Attention's Periodic Extension for Length Generalization
傅里叶位置嵌入:增强注意力的周期扩展以实现长度泛化
方法
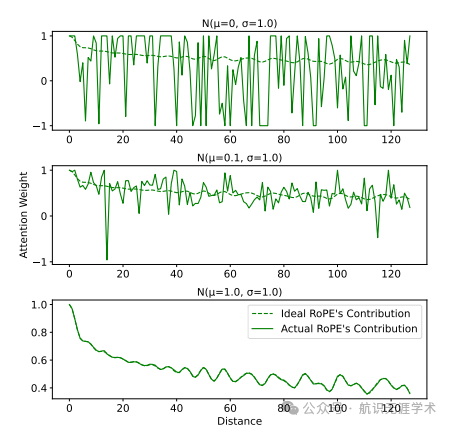
傅里叶位置嵌入(FoPE):提出了一种新的位置嵌入方法,通过将每个维度建模为傅里叶级数来增强注意力机制的频率域特性。
零化未充分训练的频率成分:通过零化低频成分来减少对周期扩展有害的频率成分。
非均匀离散傅里叶变换(NUDFT):分析了旋转位置嵌入(RoPE)如何通过隐式实现NUDFT来实现周期性注意力。
频谱损伤分析:通过分析线性层和激活函数对频谱的破坏,揭示了RoPE在长度泛化中的局限性。
创新点
傅里叶级数建模:将每个维度建模为傅里叶级数,能够更好地分离不同波长的信息,缓解频谱损伤的影响。
零化低频成分:通过零化未充分训练的低频成分,显著提高了模型在长序列任务中的性能。
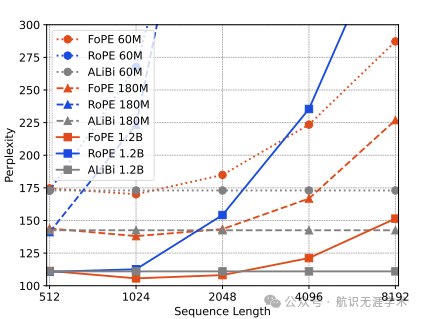
性能提升:在长序列任务中,FoPE相比于RoPE和ALiBi,在困惑度和准确率上表现出更高的稳定性,特别是在“针在草堆”任务中,FoPE的准确率显著高于RoPE和ALiBi。
理论支持:从离散信号处理理论出发,提供了对RoPE和FoPE的频率域分析,揭示了频谱损伤对长度泛化的负面影响。
论文2:
Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers
自适应傅里叶神经算子:高效的Transformer令牌混合器
方法
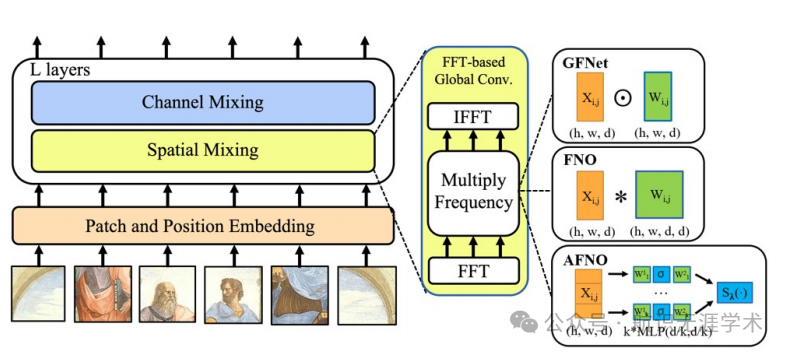
适应傅里叶神经算子(AFNO):提出了一种基于傅里叶域的高效令牌混合器,通过学习全局卷积来混合令牌。
块对角结构:在通道混合权重上施加块对角结构,以减少参数数量并提高计算效率。
自适应权重共享:通过多层感知机(MLP)实现权重的自适应共享,增强模型的泛化能力。
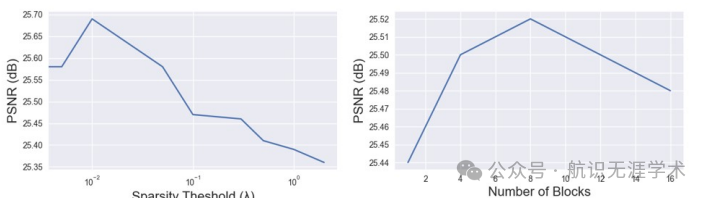
软阈值化和稀疏化:通过软阈值化操作对频率模式进行稀疏化,减少高频成分的干扰。
创新点
高效混合:AFNO通过傅里叶变换实现了高效的全局卷积,计算复杂度为O(N log N),显著低于自注意力的O(N^2)。
稀疏化处理:通过软阈值化和稀疏化,减少了不必要的频率成分,提高了模型的泛化能力和计算效率。
性能提升:在Cityscapes语义分割任务中,AFNO在处理65k序列大小时,比其他自注意力机制的性能提升了2%以上的mIoU。
内存优化:AFNO在内存使用上具有线性复杂度,与序列长度成正比,相比自注意力机制大幅减少了内存需求。
论文3:
FNet: Mixing Tokens with Fourier Transforms
FNet:用傅里叶变换混合令牌
方法
傅里叶变换混合:用标准的傅里叶变换替换Transformer编码器中的自注意力子层,实现令牌混合。
线性变换:实验了使用参数化的线性变换来混合输入令牌,发现简单的线性混合方案也能取得良好的效果。
混合机制:在FNet模型中,通过傅里叶变换将输入令牌混合,然后通过非线性的前馈层进一步处理。
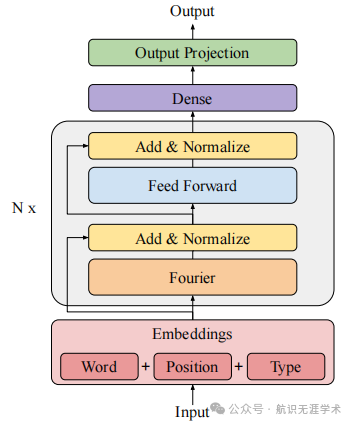
创新点
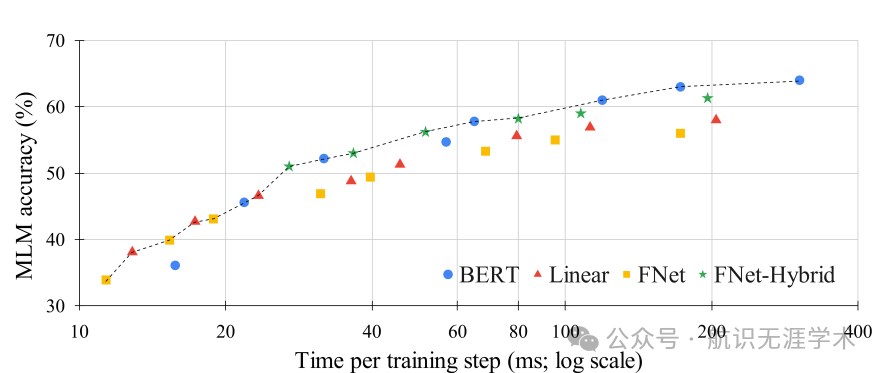
高效混合机制:傅里叶变换作为一种无参数的混合机制,训练速度比BERT快80%(GPU)和70%(TPU),同时在GLUE基准测试中达到了92-97%的BERT准确率。
长序列处理:在长序列任务中,FNet的训练和推理速度显著优于其他高效的Transformer模型,尤其是在GPU上。
性能提升:在长序列任务中,FNet的准确率与最准确的高效Transformer模型相当,但速度更快,内存占用更小。
轻量级模型:FNet在小模型尺寸下表现优异,对于资源受限的环境(如边缘设备)具有潜在的应用价值。

















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









