






2025深度学习发论文&模型涨点之——深度聚类
-
聚类分析:是一种无监督学习方法,目的是将数据划分为若干个簇(或类别),使得同一簇内的数据相似度较高,而不同簇之间的数据相似度较低。常见的聚类算法有K-Means、层次聚类、DBSCAN等。
-
深度学习:通过构建多层的神经网络结构,自动从数据中学习特征表示,能够处理复杂的非线性关系。例如卷积神经网络(CNN)在图像处理领域表现出色,循环神经网络(RNN)及其变体长短期记忆网络(LSTM)在处理序列数据方面有独特优势。
小编整理了一些深度聚类【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“ 深度聚类”即可全部领取
论文精选
论文1:
Gene-SGAN: discovering disease subtypes with imaging and genetic signatures via multi-view weakly-supervised deep clustering
通过多视角弱监督深度聚类发现具有影像和遗传特征的疾病亚型
方法
-
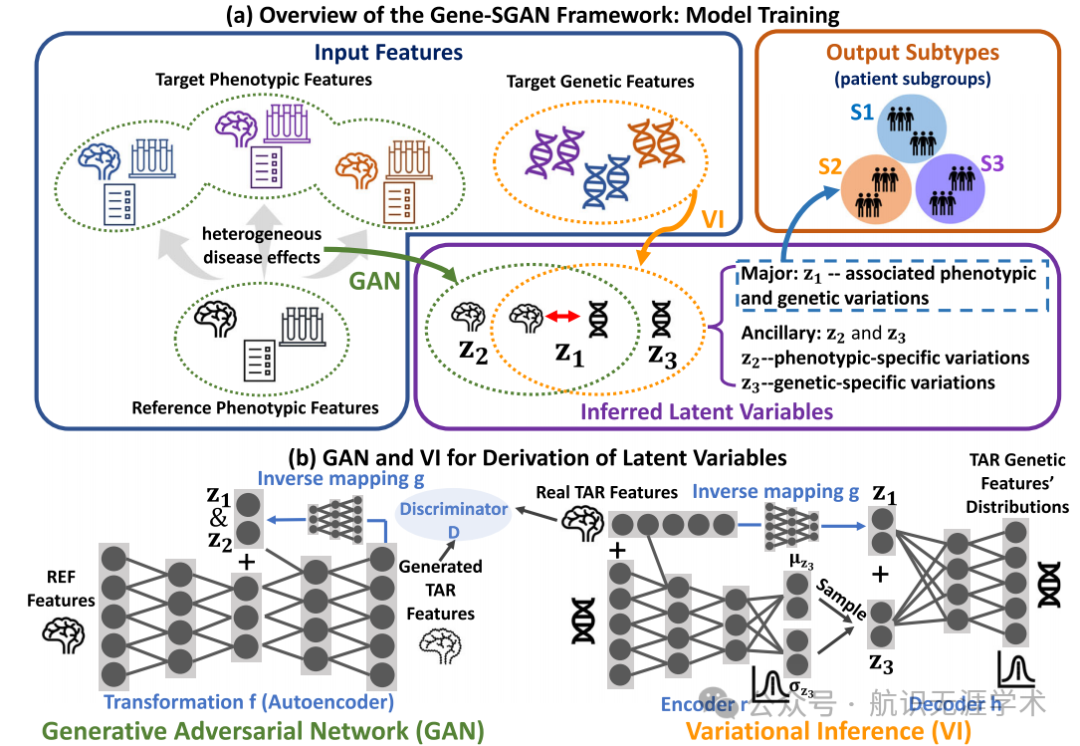
多视角弱监督深度聚类框架:Gene-SGAN结合了影像和遗传数据,通过深度生成对抗网络(GAN)和变分推断(VI)来识别疾病亚型。
生成对抗网络(GAN):用于从健康对照组到患者组的多对一映射,捕捉疾病相关的脑部变化模式。
变分推断(VI):通过解码神经网络将遗传特征与潜在变量关联起来,确保疾病亚型与遗传特征相关。
创新点
-
多视角建模:Gene-SGAN是首个将影像和遗传数据联合建模的多视角深度聚类方法,能够识别与遗传特征相关的疾病亚型。
疾病亚型识别:通过联合考虑影像和遗传数据,Gene-SGAN能够识别出具有不同神经解剖模式和遗传决定因素的疾病亚型,显著提高了疾病亚型的生物学解释性和临床相关性。
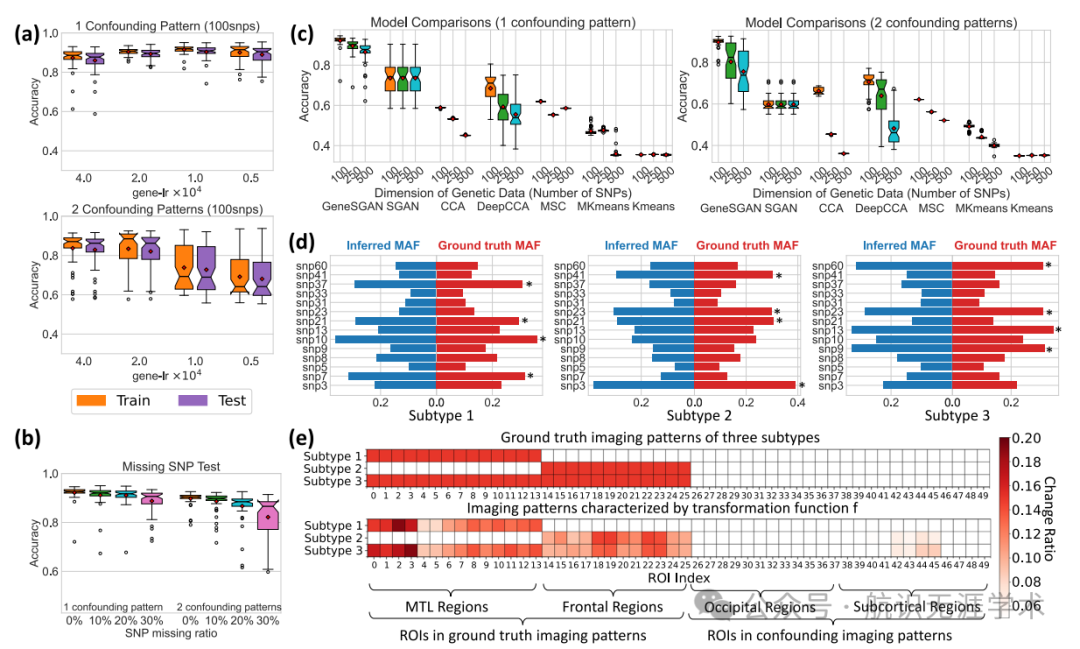
性能提升:在半合成实验中,Gene-SGAN在训练集和测试集上均表现出良好的聚类准确性,且在不同超参数设置下均能保持稳定性能。与六种现有方法相比,Gene-SGAN在所有情况下均表现出更高的聚类准确性。
论文2:
DivClust: Controlling Diversity in Deep Clustering
DivClust:在深度聚类中控制多样性
方法
-
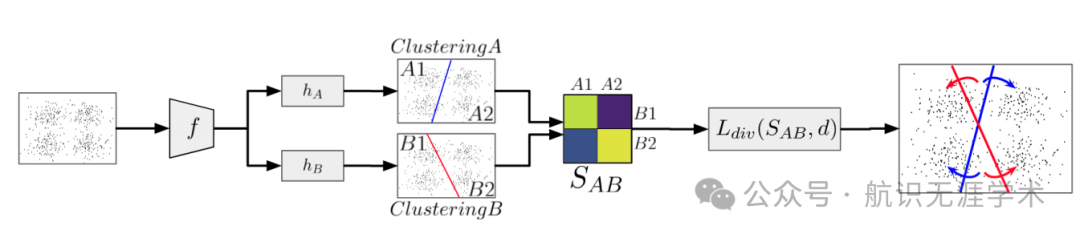
多样性控制损失函数:DivClust通过引入一个新颖的损失函数,控制深度聚类框架中多个聚类结果的多样性。
多投影头架构:使用单个特征提取器后接多个投影头,每个投影头生成一个聚类结果。
动态相似性阈值:通过动态调整相似性阈值,确保聚类结果的多样性符合用户定义的目标。
创新点
-
多样性控制:DivClust是首个能够显式控制深度聚类框架中聚类结果多样性的方法,能够根据用户定义的目标调整多样性。
性能提升:在多个数据集和深度聚类框架上,DivClust生成的聚类结果在多样性控制的同时,保持了高质量的聚类性能。
共识聚类改进:通过共识聚类,DivClust能够生成比单一聚类方法更鲁棒的聚类结果,显著提高了聚类的准确性和鲁棒性。
论文3:
Multi-Class Cell Detection Using Spatial Context Representation
基于空间上下文表示的多类细胞检测
方法
-
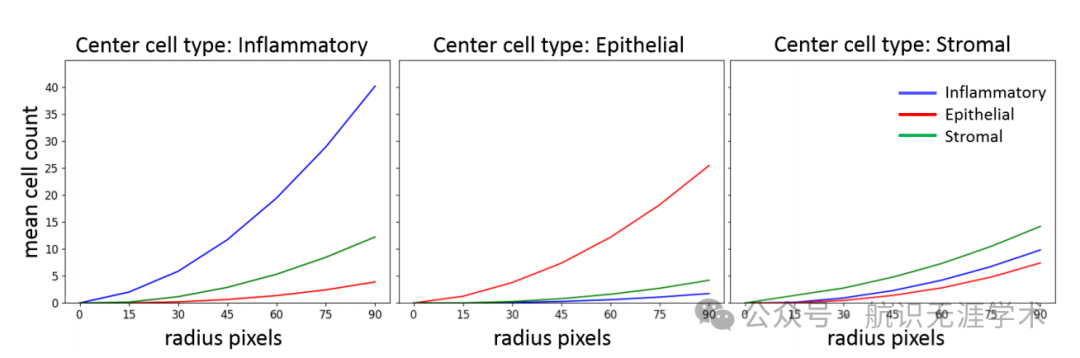
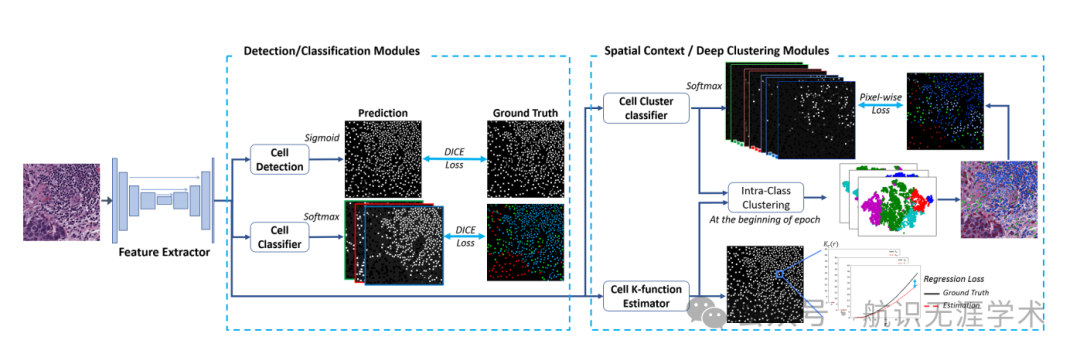
空间统计函数(K-function):引入Ripley's K-function来描述细胞的空间上下文,捕捉细胞在多类和多尺度下的空间分布。
多任务学习框架:通过多任务学习框架,联合训练细胞检测、分类和空间上下文预测模块,学习包含空间上下文的细胞表示。
深度聚类模块:引入深度聚类模块,通过聚类学习伪标签,进一步融合细胞的外观特征和空间上下文特征。
创新点
-
空间上下文建模:首次将空间上下文信息显式引入细胞检测和分类任务中,显著提高了分类性能。
性能提升:在三个不同的癌症数据集(乳腺癌、肺癌和结直肠癌)上,MCSpatNet在细胞检测和分类任务上均优于现有的最先进方法。
多任务学习:通过多任务学习框架,MCSpatNet能够同时学习细胞的外观特征和空间上下文特征,提高了模型的泛化能力和鲁棒性。

论文4:
Unsupervised Domain Adaptation via Structurally Regularized Deep Clustering
通过结构化正则化深度聚类实现无监督领域适应
方法
-
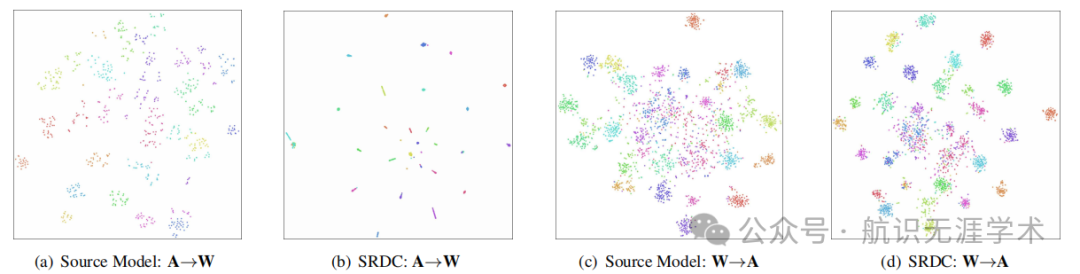
结构化正则化深度聚类(SRDC):提出了一种新的无监督领域适应方法,通过深度聚类直接揭示目标数据的内在判别结构。
KL散度最小化:通过最小化网络预测标签分布与辅助分布之间的KL散度,实现目标数据的判别聚类。
结构化源正则化:通过将辅助分布替换为源数据的真实标签分布,实现结构化源正则化。
创新点
-
直接揭示目标判别结构:SRDC直接通过目标数据的判别聚类揭示其内在判别结构,避免了传统领域适应方法中可能损害目标数据内在结构的风险。
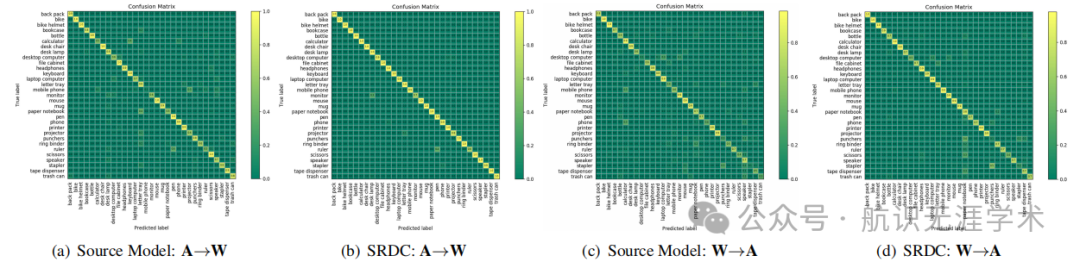
性能提升:在多个基准数据集上,SRDC在所有转移任务中均优于现有的最先进方法,特别是在源域和目标域差异较大的任务中,性能提升更为显著。
结构化正则化:通过结构化源正则化,SRDC能够更好地利用源数据的结构信息,提高目标数据的判别能力。
小编整理了深度聚类论文代码合集
需要的同学
回复“深度聚类”即可全部领取

















 3648
3648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









