







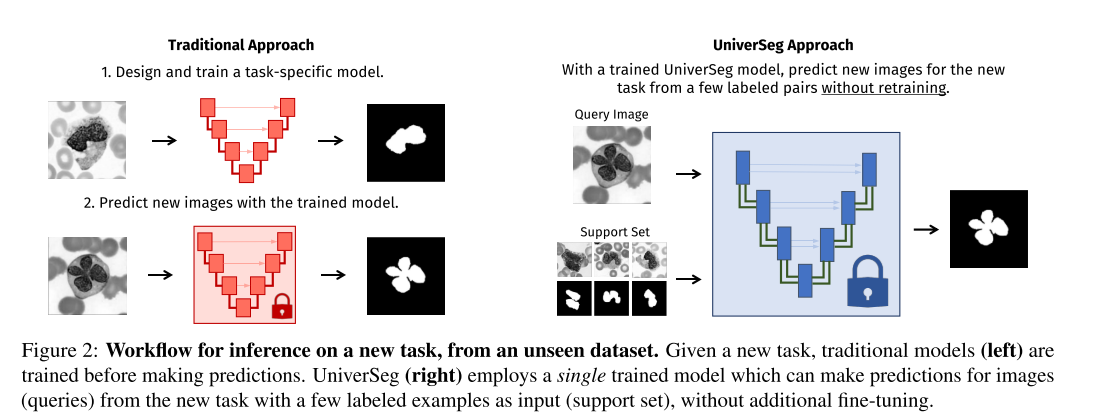
【小样本图像分割-2】UniverSeg: Universal Medical Image Segmentation

OK,今天我们来看另外一篇小样本医学图像分割的工作,在这里的这个工作中也使用了类似于元学习的方式,作者搜集了大量的医学图像数据集。在这个医学图像数据集中作者按照任务将数据集分为了支持集和查询集,按照任务的方式对模型进行训练,并在训练过程中采用了大量的数据增强的方式,推理的时候,只需要输入支持集的原始图像和mask图像以及等待预测的图像,就能得到对应的分割结果。
文章的地址:[[2304.06131] UniverSeg: Universal Medical Image Segmentation (arxiv.org)](https://openaccess.thecvf.com/content_ICCV_2019/papers/Wang_PANet_Few-Shot_Image_Semantic_Segmentation_With_Prototype_Alignment_ICCV_2019_paper.pdf)
代码的地址:https://github.com/JJGO/UniverSeg
摘要
虽然深度学习模型已经成为医学图像分割的主要方法,但它们通常无法推广到涉及新解剖结构、图像模式或标签的未知分割任务。对于新的分割任务,研究人员通常必须训练或微调模型,这既耗时又给临床研究人员带来了巨大的障碍,因为他们往往缺乏训练神经网络的资源和专业知识。我们提出了UniverSeg,一种无需额外训练即可解决看不见的医学分割任务的方法。给定一个查询图像和图像标签对的示例集来定义一个新的分割任务,UniverSeg采用一种新的CrossBlock机制来生成准确的分割映射,而不需要额外的训练。为了实现对新任务的泛化,我们收集并标准化了53个开放获取的医学分割数据集,其中包含超过22,000次扫描,我们将其称为MegaMedical。我们用这个集合来训练UniverSeg不同的解剖学和成像模式。我们证明了在看不见的任务上,UniverSeg大大优于几种相关的方法,并且对所提议的系统的重要方面进行了彻底的分析和得出见解。
作者提出的方法
首先作者给出了自己的方法和传统方法上的对比,传统的方法需要先在大规模的数据集上进行预训练,然后在小规模的数据集上进行微调,微调的效果实际上也取决于你数据集的实际规模大小。而作者提出的方法则可以在大批量的类似任务上进行学习,类似的任务指的是只需要少量的支持集图像和要预测的图像,进而通过支持集图像的特征推断出待预测图像的分割结果。
作者给出了自己的网络结构,网络结构上和平常的UNET一类的模型相比没有特别大的差异,只是在中间的层中添加了CrossBlock的模块用于支持集特征和查询集特征之间的交互。为了整合跨空间尺度的信息,我们将CrossBlock模块组合在具有残余连接的编码器-解码器结构中,类似于流行的UNet架构(图3)。该网络将查询图像xt和支持集St = {(xt i, yt i)}n i=1的图像和标签-映射对作为输入,每个图像和标签-映射对按通道连接,并输出分割预测图。编码器路径中的每个级别都由CrossBlock组成,然后是查询和支持集表示的空间下采样操作。扩展路径中的每个级别都包括对两个表示进行上采样,使其空间分辨率加倍,将它们与编码路径中同等大小的表示连接起来,然后是CrossBlock。我们执行单个1x1卷积来将最终查询表示映射到预测。任务增强(AugT(x, y, S))。与减少训练样本过拟合的标准数据增强类似,增强训练任务对于泛化到新任务很有用,特别是那些远离训练任务分布的任务。我们引入了任务增强——使用相同类型的任务更改转换来修改所有查询和支持图像,和/或所有分割映射。示例任务增强包括分割映射的边缘检测或对所有图像和标签的水平翻转。我们在补充部分C中提供了所有增强和参数的列表。
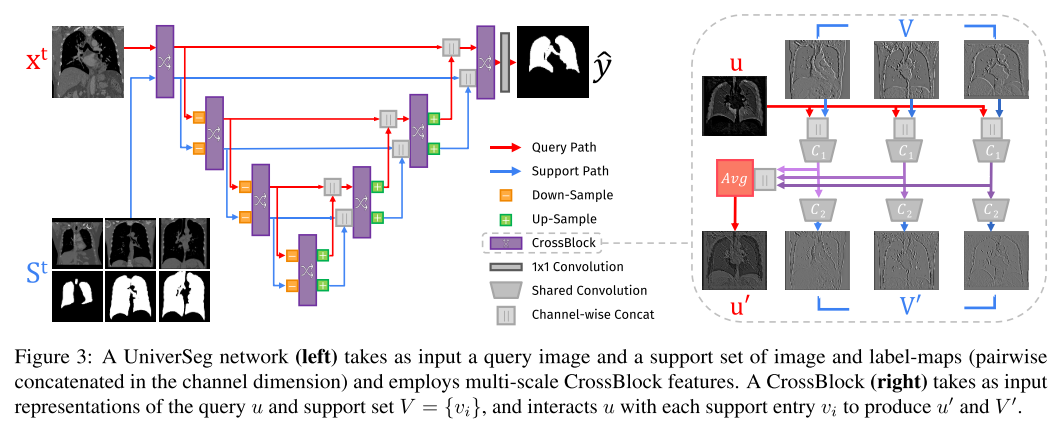
训练是以任务为基础的,每个任务由支持集和测试集构成,和平常的深度学习的语义分割任务相比,这样的元学习的结构输入的部分包含了两个,其中一个是输入的支持集的原始图像和标签,这个相当于是数据库,另外一个是需要进行查询的图像,通过这一系列图像的特征交互,让网络自己按照任务进行学习,并可以从中学习出支持集中原始图像和标签图像中的关联,进而可以对语义分割的结果进行推测。其中网络的关键在于图像中对于特征之间的交互,也就是文中提到的CrossBlock模块。
推理的过程中,相当于是一个特殊的单一的任务,通过训练好的模型,已经可以学习到支持集和查询集之间的结果,这个时候查询集的结果取决于支持集中的图像数据量,这是为什么在n-way k-shot问题中,k的数字越大,查询集的预测结果相对也越好。这里作者放了训练的公式,可以进行参考。

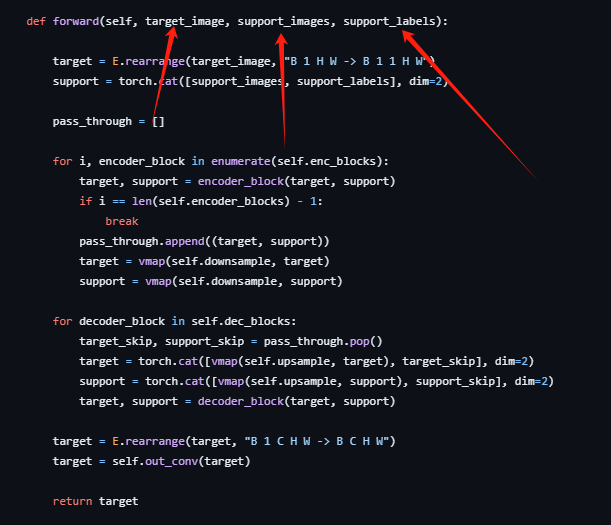
这里放一下这个的代码,从这里的代码也可以看出,输入的部分主要是分为了3个,分别是原始的要预测的图像,支持集的图像和支持集图像的标签。
其中作者自己实现了一个交叉的卷积的算子。大概内容是在x和y上进行特征的concat也就是连接。
class CrossConv2d(nn.Conv2d):
"""
Compute pairwise convolution between all element of x and all elements of y.
x, y are tensors of size B,_,C,H,W where _ could be different number of elements in x and y
essentially, we do a meshgrid of the elements to get B,Sx,Sy,C,H,W tensors, and then
pairwise conv.
Args:
x (tensor): B,Sx,Cx,H,W
y (tensor): B,Sy,Cy,H,W
Returns:
tensor: B,Sx,Sy,Cout,H,W
"""
"""
CrossConv2d is a convolutional layer that performs pairwise convolutions between elements of two input tensor 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3058
3058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











