







 本文介绍了Kiran提出的树种优化算法(TSA),一种受自然界树种繁衍启发的搜索算法。文章详细阐述了算法原理,包括基于种子繁衍的思想和过程,并提供了对应的代码实现,以CEC2005测试函数为例展示其在优化问题中的应用。
本文介绍了Kiran提出的树种优化算法(TSA),一种受自然界树种繁衍启发的搜索算法。文章详细阐述了算法原理,包括基于种子繁衍的思想和过程,并提供了对应的代码实现,以CEC2005测试函数为例展示其在优化问题中的应用。

1.背景
2015年,Kiran受到树通过种子进行繁衍自然行为启发,提出了树种优化算法(Tree Seed Algorithm,TSA)。
2.算法原理
2.1算法思想
树种优化算法基于种子繁衍,算法中需要设定种子的数量范围,处于最优位置的树自然资源最好,因此种群更倾向与靠近最优位置。
2.2算法过程
群体位置初始化:
T
=
L
+
r
a
n
d
∗
(
H
−
L
)
T=L+rand*(H-L)
T=L+rand∗(H−L)
其中,
T
,
H
,
L
T,H,L
T,H,L分别代表树的位置,搜索边界。
种子繁衍:
首先,在随机生成的树种群中,寻找位置最好的树(根据适应度函数度量):
[
B
e
s
t
,
B
e
s
t
I
d
x
]
=
m
i
n
(
f
i
t
n
e
s
s
(
T
)
)
[Best,BestIdx]=min(fitness(T))
[Best,BestIdx]=min(fitness(T))
种子生成位置:
S
i
=
{
T
i
+
α
i
∗
(
T
i
−
T
r
)
,
r
a
n
d
<
S
T
T
i
+
α
i
∗
(
B
e
s
t
−
T
r
)
,
o
t
h
e
r
w
i
s
e
S_i=\begin{cases}T_i+\alpha_i*(T_i-T_r),rand<ST \\ T_i+\alpha_i*(Best-T_r),otherwise \end{cases}
Si={Ti+αi∗(Ti−Tr),rand<STTi+αi∗(Best−Tr),otherwise
其中,
S
T
ST
ST代表搜索阈值,控制是否进行全局搜索还是局部搜索。当
r
a
n
d
<
S
T
rand<ST
rand<ST时,全局搜索;当
r
a
n
d
≥
S
T
rand \geq ST
rand≥ST时,在最优位置产生新种子。
伪代码

3.代码实现
% 树种优化算法
function [Best_pos, Best_fitness, Iter_curve, History_pos, History_best] = TSA(pop, dim, ub, lb, fobj, maxIter)
%input
%pop 种群数量
%dim 问题维数
%ub 变量上边界
%lb 变量下边界
%fobj 适应度函数
%maxIter 最大迭代次数
%output
%Best_pos 最优位置
%Best_fitness 最优适应度值
%Iter_curve 每代最优适应度值
%History_pos 每代种群位置
%History_best 每代最优树种位置
%% 树种参数
low = ceil(0.1 * pop);
high = ceil(0.25 * pop);
ST = 0.1; %概率阈值
%% 初始化种群
trees = zeros(pop, dim);
for i = 1:pop
for j = 1:dim
trees(i,j) = (ub(j) - lb(j)) * rand() + lb(j);
end
end
%% 计算适应度值
fitness = zeros(1,pop);
for i = 1:pop
fitness(i) = fobj(trees(i,:));
end
%% 记录全局最优解
[SortFitness, indexSort] = sort(fitness);
gBestFitness = SortFitness(1);
gBest = trees(indexSort(1),:);
%% 迭代
for t = 1:maxIter
for i = 1:pop
seedNum = fix(low + (high - low) * rand) + 1;
%在种子数量范围内,随机生成产生种子的数量
seeds = zeros(seedNum, dim);
obj_seeds = zeros(1, seedNum);
%寻找最优树
[minimum, min_indis] = min(fitness);
bestParams = trees(min_indis, :);
%树产生种子
for j = 1:seedNum
komsu = fix(rand * pop) + 1; %随机选择一颗树
while(i == komsu) %保证komsu不等于i
komsu = fix(rand * pop) + 1;
end
seeds(j,:) = trees(j,:);
for d = 1:dim
if rand < ST
seeds(j,d) = trees(i,d) + (bestParams(d) - trees(komsu,d)) * (rand - 0.5) * 2;
else
seeds(j,d) = trees(i,d) + (trees(i,d) - trees(komsu,d)) * (rand - 0.5) * 2;
end
end
%边界检查
for k = 1:dim
if seeds(j, k) > ub(k)
seeds(j, k) = ub(k);
end
if seeds(j, k) < lb(k)
seeds(j, k) = lb(k);
end
end
obj_seeds(j) = fobj(seeds(j,:));
end
%寻找全局最优树
[mintohum, mintohum_indis] = min(obj_seeds);
if(mintohum < fitness(i))
trees(i,:) = seeds(mintohum_indis,:);
fitness(i) = mintohum;
end
end
%寻找最优树
[min_tree, min_tree_index] = min(fitness);
if(min_tree < gBestFitness)
gBestFitness = min_tree;
gBest = trees(min_tree_index,:);
end
History_pos{t} = trees;
History_best{t} = gBest;
Iter_curve(t) = gBestFitness;
end
Best_pos = gBest;
Best_fitness = gBestFitness;
end
优化问题:
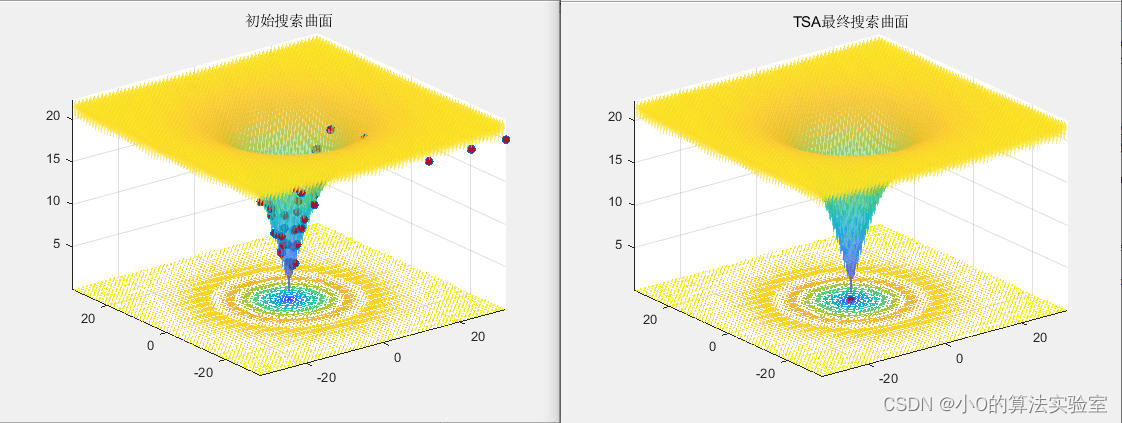
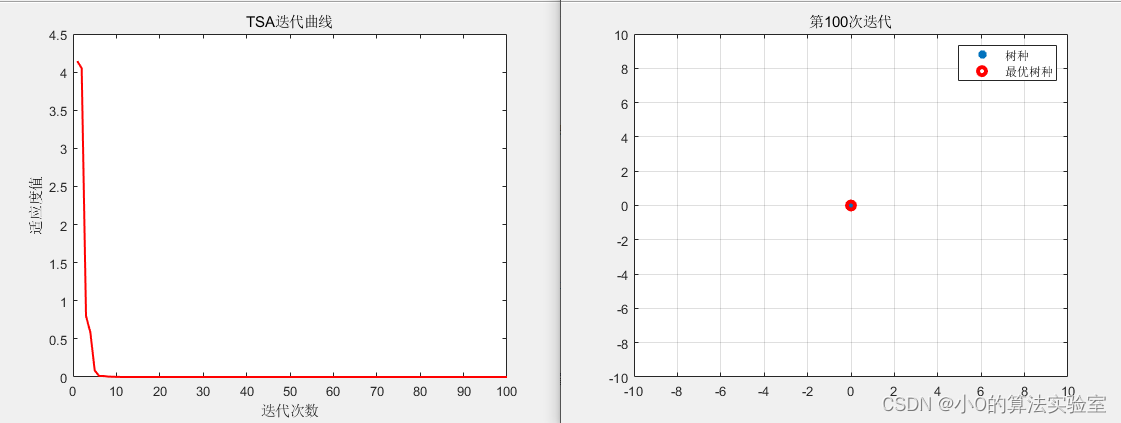
以CEC2005测试函数为例
clear,clc,close all
x = -32:0.5:32;
y = x;
L = length(x);
for i = 1:L
for j = 1:L
f(i,j) = fun([x(i) y(j)]);
end
end
surfc(x, y, f, 'LineStyle', 'none', 'FaceAlpha',0.5);
% 设定树种参数
pop = 50;
dim = 2;
ub = [32,32];
lb = [-32, -32];
maxIter = 100;
fobj = @(x) fun(x);
% 求解
[Best_pos, Best_fitness, Iter_curve, History_pos, History_best] = TSA(pop, dim, ub, lb, fobj, maxIter);
















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











