








1.背景
2023年,M Dehghani等人受到长鼻浣熊自然行为启发,提出了长鼻浣熊优化算法(Coati Optimization Algorithm,COA)。
2.算法原理
2.1算法思想
COA模拟浣熊的两种自然行为:攻击和捕猎鬣蜥和逃离捕食者,COA在两个不同的阶段进行更新。

2.2算法过程
阶段1:猎捕和攻击鬣蜥策略(探索阶段)
长鼻浣熊种群在搜索空间中更新的第一阶段,模拟了它们攻击鬣蜥的策略。在这个策略中,一群长鼻浣熊爬上树接近鬣蜥并吓唬它,其他长鼻浣熊在树下等待。当鬣蜥倒地后,长鼻浣熊攻击并猎杀它。这一策略使得长鼻浣熊在搜索空间中移动到不同位置,展现了它们在全局搜索中的探索能力:
X
i
P
1
:
x
i
,
j
P
1
=
x
i
,
j
+
r
⋅
(
I
g
u
a
n
a
j
−
I
⋅
x
i
,
j
)
,
f
o
r
i
=
1
,
2
,
…
,
⌊
N
2
⌋
(1)
X_i^{P1}: x_{i,j}^{P1}=x_{i,j}+r\cdot\left(Iguana_j-I\cdot x_{i,j}\right), \mathrm{for} i=1,2, \ldots,\left\lfloor\frac N2\right\rfloor \tag{1}
XiP1:xi,jP1=xi,j+r⋅(Iguanaj−I⋅xi,j),fori=1,2,…,⌊2N⌋(1)
在鬣蜥落地后,将其放置在搜索空间的任意位置,地面上的浣熊在搜索空间中移动:
l
g
u
a
n
a
G
:
l
g
u
a
n
a
j
G
=
l
b
j
+
r
⋅
(
u
b
j
−
l
b
j
)
,
j
=
1
,
2
,
…
,
m
,
X
i
P
1
:
x
i
,
j
P
1
=
{
x
i
,
j
+
r
⋅
(
l
g
u
a
n
a
j
C
−
l
⋅
x
i
,
j
)
,
F
l
g
u
a
n
a
G
<
F
i
,
x
i
,
j
+
r
⋅
(
x
i
,
j
−
l
g
u
a
n
a
j
G
)
,
e
l
s
e
,
(2)
lguana^G: lguana_j^G= lb_j+r\cdot\left(ub_j-lb_j\right), j= 1, 2, \ldots, m,\\X_i^{P1}:x_{i,j}^{P1}=\begin{cases}x_{i,j}+r\cdot\left(lguana_j^C-l\cdot x_{i,j}\right),&F_{lguana^G}<F_i,\\\quad x_{i,j}+r\cdot\left(x_{i,j}-lguana_j^G\right),&else,\end{cases}\tag{2}
lguanaG:lguanajG=lbj+r⋅(ubj−lbj),j=1,2,…,m,XiP1:xi,jP1={xi,j+r⋅(lguanajC−l⋅xi,j),xi,j+r⋅(xi,j−lguanajG),FlguanaG<Fi,else,(2)
根据适应度更新位置:
X
i
=
{
X
i
P
1
,
F
i
P
1
<
F
i
,
X
i
,
e
l
s
e
.
(3)
X_i=\begin{cases}X_i^{P1},&\quad F_i^{P1}<F_i,\\\quad X_i,&\quad else.\end{cases}\tag{3}
Xi={XiP1,Xi,FiP1<Fi,else.(3)

阶段2:逃离捕食者的过程(开发阶段)
当捕食者攻击浣熊时,浣熊会逃离它的位置:
l
b
j
l
o
c
a
l
=
l
b
j
t
,
u
b
j
l
o
c
a
l
=
u
b
j
t
,
w
h
e
r
e
t
=
1
,
2
,
…
,
T
.
X
i
P
2
:
x
i
,
j
P
2
=
x
i
,
j
+
(
1
−
2
r
)
⋅
(
l
b
j
l
o
c
a
l
+
r
⋅
(
u
b
j
l
o
c
a
l
−
l
b
j
l
o
c
a
l
)
)
,
(4)
lb_{j}^{local}=\frac{lb_{j}}{t},ub_{j}^{local}=\frac{ub_{j}}{t}, \mathrm{where} t=1, 2, \ldots, T.\\X_{i}^{P2}: x_{i,j}^{P2}=x_{i,j}+(1-2r)\cdot\left(lb_{j}^{local}+r\cdot\left(ub_{j}^{local}-lb_{j}^{local}\right)\right),\tag{4}
lbjlocal=tlbj,ubjlocal=tubj,wheret=1,2,…,T.XiP2:xi,jP2=xi,j+(1−2r)⋅(lbjlocal+r⋅(ubjlocal−lbjlocal)),(4)
根据适应度更新位置:
X
i
=
{
X
i
P
2
,
F
i
P
2
<
F
i
,
X
i
,
e
l
s
e
,
(5)
X_i=\begin{cases}X_i^{P2},&\quad F_i^{P2}<F_i,\\\quad X_i,&\quad else,\end{cases}\tag{5}
Xi={XiP2,Xi,FiP2<Fi,else,(5)
流程图

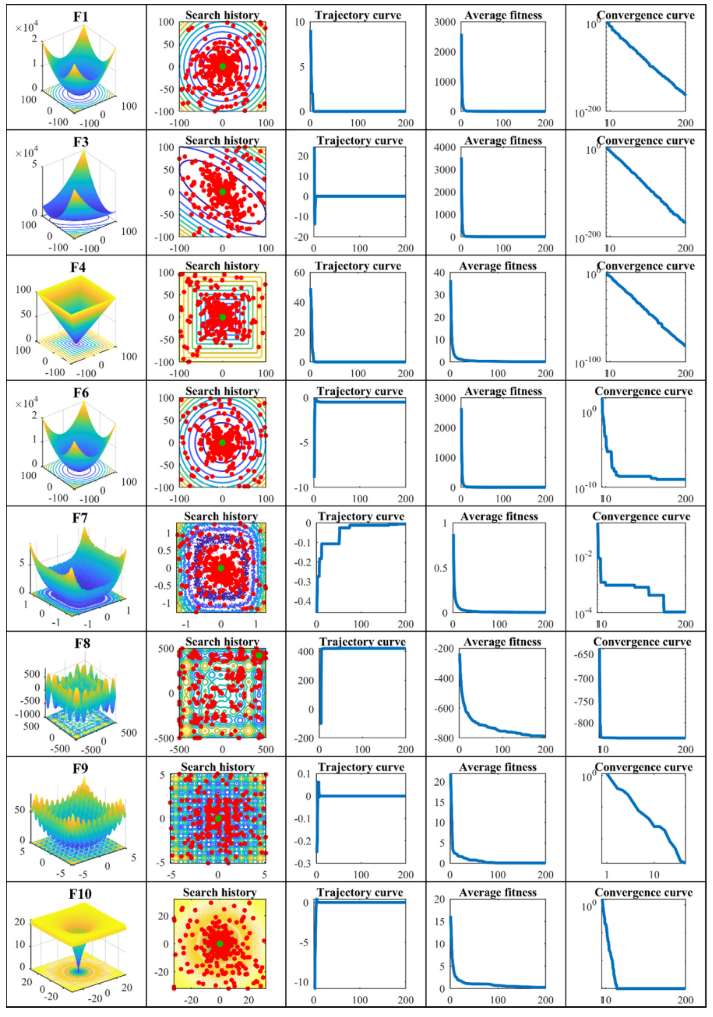
3.结果展示
4.参考文献
[1] Dehghani M, Montazeri Z, Trojovská E, et al. Coati Optimization Algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems[J]. Knowledge-Based Systems, 2023, 259: 110011.
















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











