







1.背景
2024年,J Lian等人受到鹦鹉学习行为启发,提出了鹦鹉优化算法(Parrot Optimizer, PO)。


2.算法原理
2.1算法思想
PO灵感来自于在驯养的鹦鹉中观察到的觅食、停留、交流和对陌生人的恐惧行为。

2.2算法过程
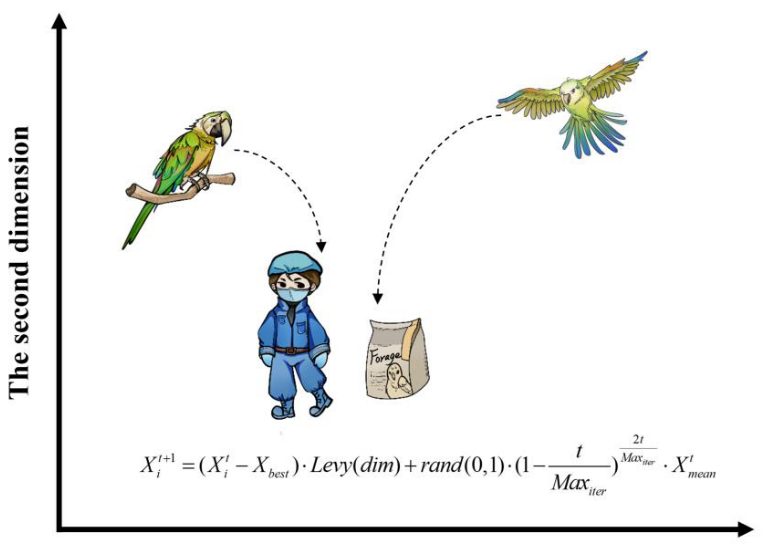
觅食行为
在觅食行为中,它们主要通过观察食物的位置或考虑主人的位置来估计食物的大致位置,然后向各自的位置飞去:
X
i
t
+
1
=
(
X
i
t
−
X
b
e
s
t
)
⋅
L
e
v
y
(
d
i
m
)
+
r
a
n
d
(
0
,
1
)
⋅
(
1
−
t
M
a
x
i
t
e
r
)
2
t
M
a
x
i
t
e
r
⋅
X
m
e
a
n
t
(1)
X_i^{t+1}=(X_i^t-X_{best})\cdot Levy(dim)+rand(0,1)\cdot(1-\frac t{Max_{iter}})^{\frac{2t}{Max_{iter}}}\cdot X_{mean}^t\tag{1}
Xit+1=(Xit−Xbest)⋅Levy(dim)+rand(0,1)⋅(1−Maxitert)Maxiter2t⋅Xmeant(1)
Xbest最优鹦鹉位置,Xmean种群鹦鹉平均位置。
Levy飞行表述为:
{
L
e
v
y
(
d
i
m
)
=
μ
⋅
σ
∣
v
∣
1
γ
μ
∼
N
(
0
,
d
i
m
)
v
∼
N
(
0
,
d
i
m
)
σ
=
(
Γ
(
1
+
γ
)
⋅
sin
(
π
γ
2
)
Γ
(
1
+
γ
2
)
⋅
γ
⋅
2
1
+
γ
2
)
γ
+
1
(2)
\begin{cases}Levy(dim)=\frac{\mu\cdot\sigma}{|v|^{\frac1\gamma}}\\\mu\thicksim N(0,dim)\\v\thicksim N(0,dim)\\\sigma=(\frac{\Gamma(1+\gamma)\cdot\sin(\frac{\pi\gamma}2)}{\Gamma(\frac{1+\gamma}2)\cdot\gamma\cdot2^{\frac{1+\gamma}2}})^{\gamma+1}\end{cases}\tag{2}
⎩
⎨
⎧Levy(dim)=∣v∣γ1μ⋅σμ∼N(0,dim)v∼N(0,dim)σ=(Γ(21+γ)⋅γ⋅221+γΓ(1+γ)⋅sin(2πγ))γ+1(2)
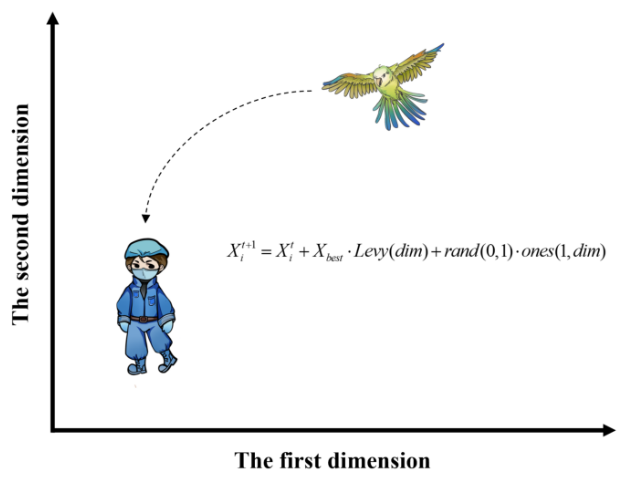
停留行为
鹦鹉是一种高度社会化的生物,它的停留行为主要包括突然飞到主人身体的任何部位,在那里静止一段时间:
X
i
t
+
1
=
X
i
t
+
X
b
e
s
t
⋅
L
e
v
y
(
d
i
m
)
+
r
a
n
d
(
0
,
1
)
⋅
o
n
e
s
(
1
,
d
i
m
)
(3)
X_i^{t+1}=X_i^t+X_{best}\cdot Levy(dim)+rand(0,1)\cdot ones(1,dim)\tag{3}
Xit+1=Xit+Xbest⋅Levy(dim)+rand(0,1)⋅ones(1,dim)(3)
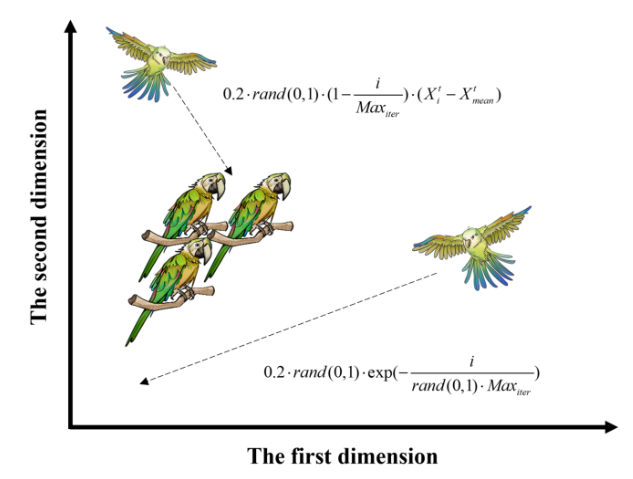
交流行为
鹦鹉特点是群体内的密切交流,包括飞向鸟群和不飞向鸟群的沟通。假设这两种行为发生的概率相等,并使用当前种群的平均位置来象征群体的中心:
X
i
t
+
1
=
{
0.2
⋅
r
a
n
d
(
0
,
1
)
⋅
(
1
−
t
M
a
x
i
t
e
r
)
⋅
(
X
i
t
−
X
m
e
a
n
t
)
,
P
≤
0.5
0.2
⋅
r
a
n
d
(
0
,
1
)
⋅
e
x
p
(
−
t
r
a
n
d
(
0
,
1
)
⋅
M
a
x
i
t
e
r
)
,
P
>
0.5
(4)
X_i^{t+1}=\begin{cases}0.2\cdot rand(0,1)\cdot(1-\frac{t}{Max_{iter}})\cdot(X_i^t-X_{mean}^t),P\leq0.5\\0.2\cdot rand(0,1)\cdot exp(-\frac{t}{rand(0,1)\cdot Max_{iter}}),P>0.5\end{cases}\tag{4}
Xit+1={0.2⋅rand(0,1)⋅(1−Maxitert)⋅(Xit−Xmeant),P≤0.50.2⋅rand(0,1)⋅exp(−rand(0,1)⋅Maxitert),P>0.5(4)
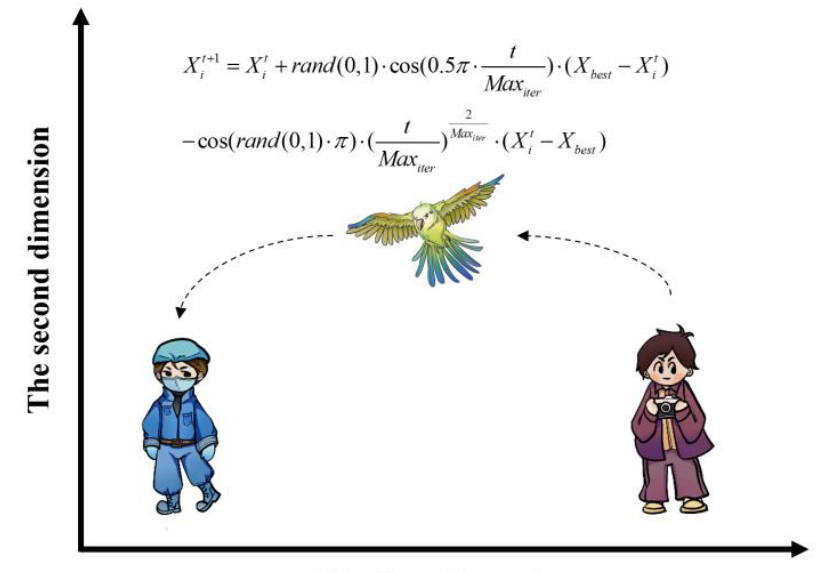
恐惧行为
鹦鹉对陌生人表现出天然的恐惧,它们与不熟悉的个体保持距离并与主人一起寻找安全环境:
X
i
t
+
1
=
X
i
t
+
r
a
n
d
(
0
,
1
)
⋅
c
o
s
(
0.5
π
⋅
t
M
a
x
i
t
e
r
)
⋅
(
X
b
e
s
t
−
X
i
t
)
−
c
o
s
(
r
a
n
d
(
0
,
1
)
⋅
π
)
⋅
(
t
M
a
x
i
t
e
r
)
2
M
a
x
i
t
e
r
⋅
(
X
i
t
−
X
b
e
s
t
)
(5)
X_{i}^{t+1}=X_{i}^{t}+rand(0,1)\cdot cos(0.5\pi\cdot\frac{t}{Max_{iter}})\cdot(X_{best}-X_{i}^{t})-cos(rand(0,1)\cdot\pi)\cdot(\frac{t}{Max_{iter}})^{\frac{2}{Max_{iter}}}\cdot(X_{i}^{t}-X_{best})\tag{5}
Xit+1=Xit+rand(0,1)⋅cos(0.5π⋅Maxitert)⋅(Xbest−Xit)−cos(rand(0,1)⋅π)⋅(Maxitert)Maxiter2⋅(Xit−Xbest)(5)
流程图
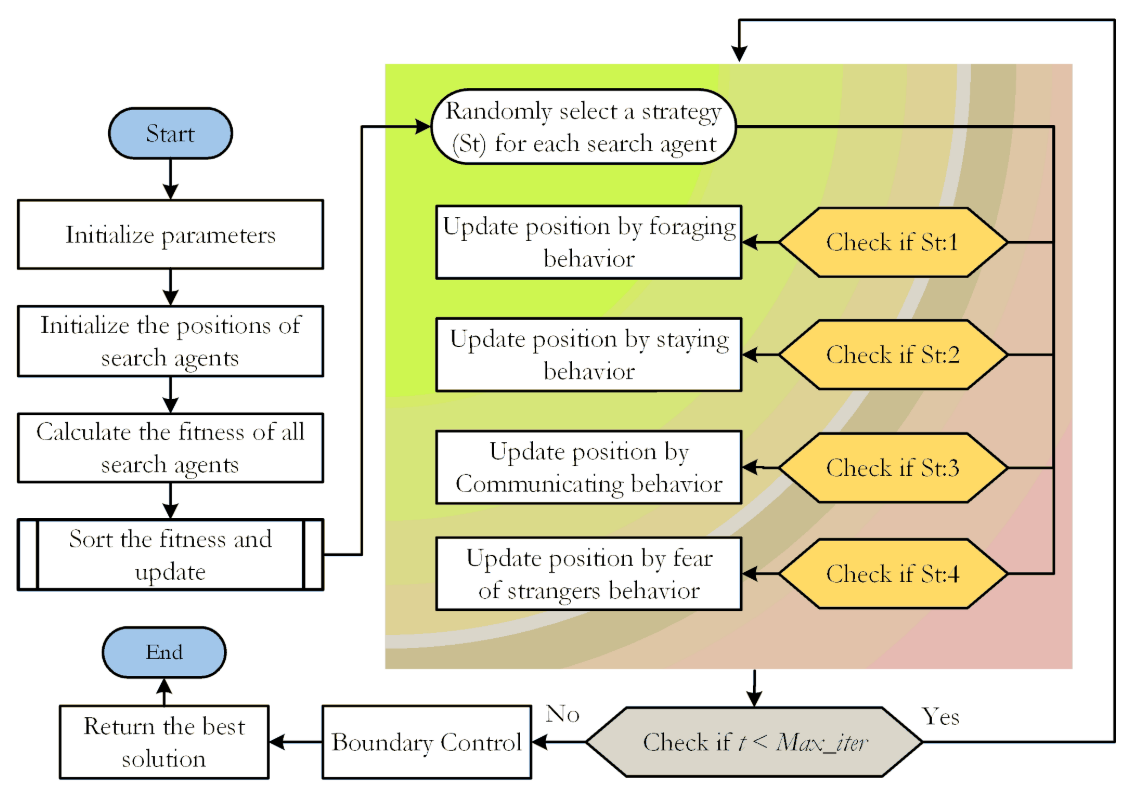
伪代码

3.结果展示
使用测试框架,测试PO性能 一键run.m
CEC2005-F9
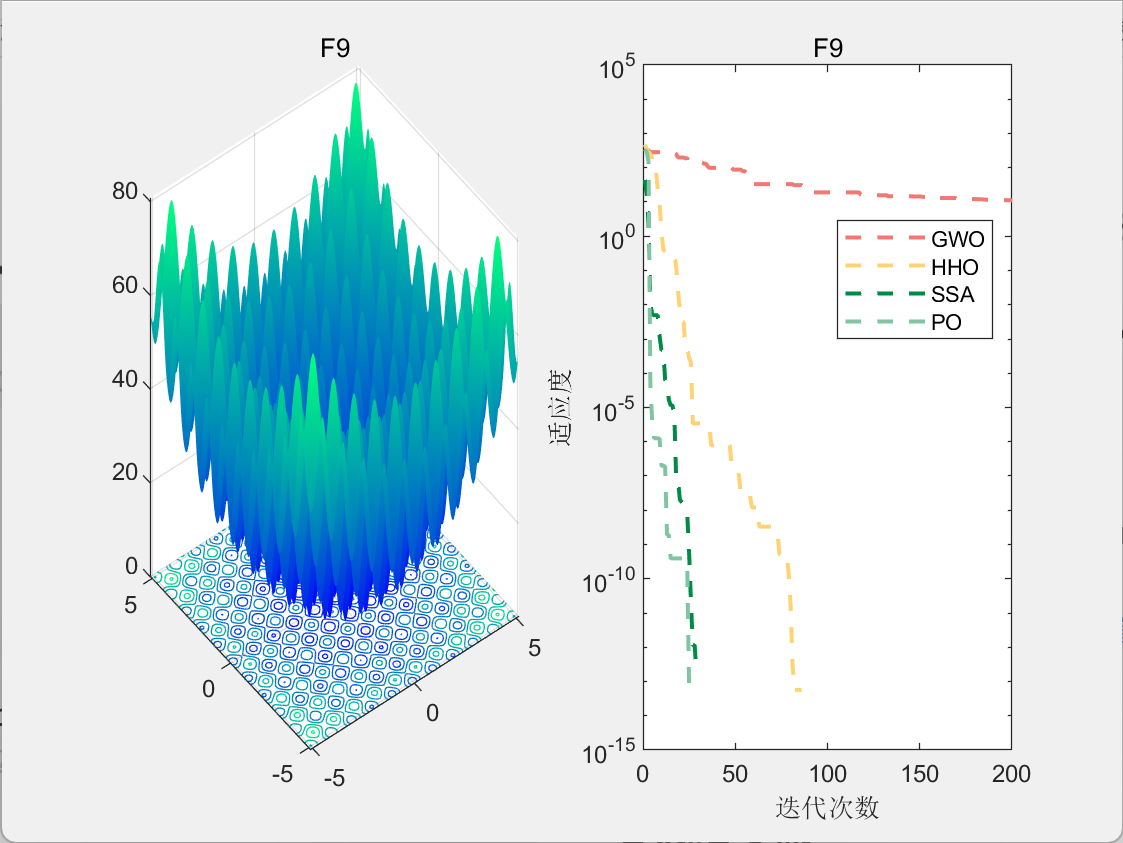
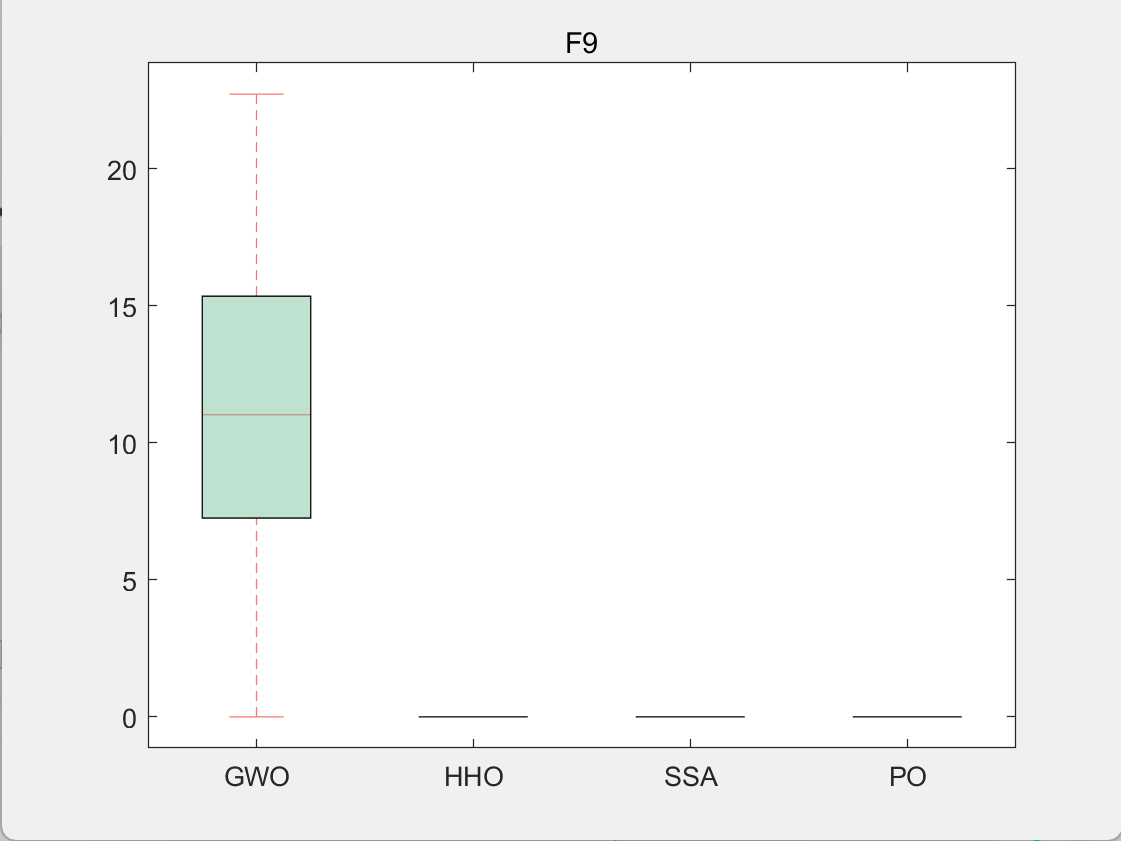
4.参考文献
[1] Lian J, Hui G, Ma L, et al. Parrot optimizer: Algorithm and applications to medical problems[J]. Computers in Biology and Medicine, 2024: 108064.
















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











