











1.摘要
无人机的自主导航在灾难场景中具有重要意义。为了解决无人机路径规划问题,本文提出了一种基于灰狼优化算法(GWO)和差分进化算法(DE)的混合算法(HGWODE)。HGWODE算法通过有效的协作,平衡了局部开发与全局探索的能力,其改进了GWO的位置更新公式,使得alpha、beta和delta狼围绕alpha狼进行搜索,而omega狼则围绕前三名狼进行搜索,从而增强了开发能力。DE算法中采用了基于排名的变异策略,进一步促进了局部开发的同时保持了全局探索能力。
2.灰狼算法GWO原理
3.改进策略
改进GWO位置更新
在灰狼优化算法(GWO)中,狼群的前三名狼具有不同的社会地位。Alpha狼是群体中的主导者,负责管理整个狼群;Beta狼尊重Alpha狼,并指挥其他狼;Delta狼则服从于Alpha和Beta狼。为了充分利用领导狼的信息,Beta狼和Delta狼围绕Alpha狼进行搜索,而Alpha狼则进行独立探索。这种社会层次结构帮助优化算法在搜索过程中更好地平衡局部开发与全局探索:
{
X
→
α
=
X
→
α
+
2
×
a
→
×
r
a
n
d
×
(
X
→
r
1
−
X
→
r
2
)
X
→
β
=
X
→
β
+
2
×
a
→
×
r
a
n
d
×
(
X
→
α
−
X
→
β
)
X
→
δ
=
X
→
δ
+
2
×
a
→
×
r
a
n
d
×
(
X
→
α
−
X
→
δ
)
\left\{ \begin{array} {c}\overrightarrow{X}_\alpha=\overrightarrow{X}_\alpha+2\times\overrightarrow{a}\times rand\times\left(\overrightarrow{X}_{r_1}-\overrightarrow{X}_{r_2}\right) \\ \overrightarrow{X}_\beta=\overrightarrow{X}_\beta+2\times\overrightarrow{a}\times rand\times\left(\overrightarrow{X}_\alpha-\overrightarrow{X}_\beta\right) \\ \overrightarrow{X}_\delta=\overrightarrow{X}_\delta+2\times\overrightarrow{a}\times rand\times\left(\overrightarrow{X}_\alpha-\overrightarrow{X}_\delta\right) \end{array}\right.
⎩
⎨
⎧Xα=Xα+2×a×rand×(Xr1−Xr2)Xβ=Xβ+2×a×rand×(Xα−Xβ)Xδ=Xδ+2×a×rand×(Xα−Xδ)
适应度越好的狼所拥有的信息就越好,因此根据适应度进行归一化分配权重比例:
(
w
α
,
w
β
,
w
δ
)
=
(
f
(
X
→
α
)
+
f
(
X
→
β
)
+
f
(
X
→
δ
)
)
×
(
1
f
(
X
→
α
)
,
1
f
(
X
→
β
)
,
1
f
(
X
→
δ
)
)
(w_{\alpha,}w_{\beta},w_{\delta})=\left(f\left(\overrightarrow{X}_{\alpha}\right)+f\left(\overrightarrow{X}_{\beta}\right)+f\left(\overrightarrow{X}_{\delta}\right)\right)\times(\frac{1}{f\left(\overrightarrow{X}_{\alpha}\right)},\frac{1}{f\left(\overrightarrow{X}_{\beta}\right)},\frac{1}{f\left(\overrightarrow{X}_{\delta}\right)})
(wα,wβ,wδ)=(f(Xα)+f(Xβ)+f(Xδ))×(f(Xα)1,f(Xβ)1,f(Xδ)1)
灰狼位置更新:
X
′
→
(
t
+
1
)
=
w
α
×
X
→
1
+
w
β
×
X
→
2
+
w
δ
×
X
→
3
w
α
+
w
β
+
w
δ
\overrightarrow{X^{\prime}}(t+1)=\frac{w_\alpha\times\overrightarrow{X}_1+w_\beta\times\overrightarrow{X}_2+w_\delta\times\overrightarrow{X}_3}{w_\alpha+w_\beta+w_\delta}
X′(t+1)=wα+wβ+wδwα×X1+wβ×X2+wδ×X3
DE增强开发
差分进化(DE)算法采用rand/1变异算子,具有优越的探索能力:
v
i
=
x
r
1
+
F
×
(
x
r
2
−
x
r
3
)
v_i=x_{r_1}+F\times(x_{r_2}-x_{r_3})
vi=xr1+F×(xr2−xr3)
采用GWO参数
A
A
A代替
F
F
F:
v
i
=
x
r
1
+
2
×
r
a
n
d
×
a
→
×
(
x
r
2
−
x
r
3
)
v_i=x_{r_1}+2\times rand\times\overrightarrow{a}\times(x_{r_2}-x_{r_3})
vi=xr1+2×rand×a×(xr2−xr3)
然而,rand/1变异算子在处理候选解时常常会导致探索效率的降低,因为它进行随机搜索而未考虑候选解的当前状态。在自然界中,适应环境的物种通常更有可能繁衍后代。在这种方法中,解决方案根据其适应度值被排序,并赋予一个排名指数
i
i
i。每个解决方案的选择概率随后根据其排名来计算:
P
(
i
)
=
(
N
P
−
i
)
/
N
P
P(i)=(NP-i)/NP
P(i)=(NP−i)/NP

伪代码

4.结果展示
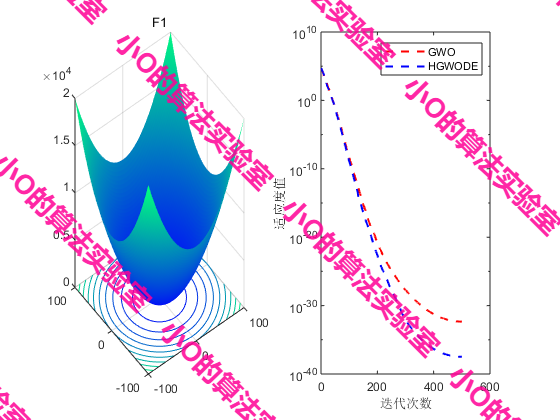
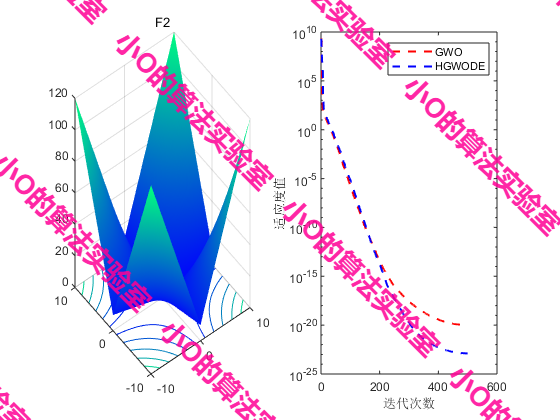
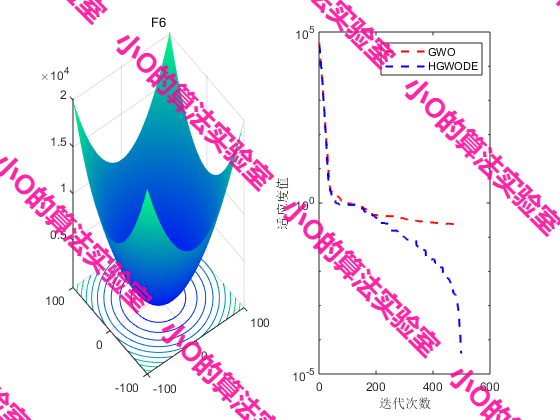
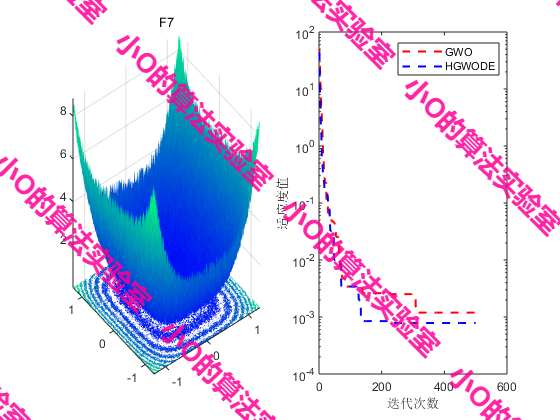
5.参考文献
[1] Yu X, Jiang N, Wang X, et al. A hybrid algorithm based on grey wolf optimizer and differential evolution for UAV path planning[J]. Expert Systems with Applications, 2023, 215: 119327.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











