






面向量产的3D目标与车道线检测
:::

附赠自动驾驶学习资料和量产经验:链接
:::
Part 1 背景介绍
1. 1 团队介绍

商汤科技自动驾驶团队依托公司为背景,以 SenseParrots 作为基础平台,进行超大规模的网络学习;在自动驾驶的核心技术方面,从视觉感知、激光雷达感知、多传感器融合等多方面持续发力;在产品应用的层面上,团队在车路协同、V2X 等方面都有不同级别和维度的项目在持续推进当中。团队的研究分为两个维度:L4 级别自动驾驶的落地和从 L0 到 L2 级别辅助驾驶的落地。
1.2 自动驾驶算法流程概述
Source from Apollo; revised
TTC为Time to Contact 或 Time to Collision,为自车与前车发生碰撞的时间,定义为自车与障碍物之间的距离除以相对速度。而在单目系统中,测距和测速并不是一个简单的任务。而基于单目视觉的TTC估计是在不需要计算实际距离和速度的前提下,算得自车与前车的碰撞时间。(一文读懂TTC碰撞时间算法_放牛娃子的博客-CSDN博客_ttc碰撞时间)
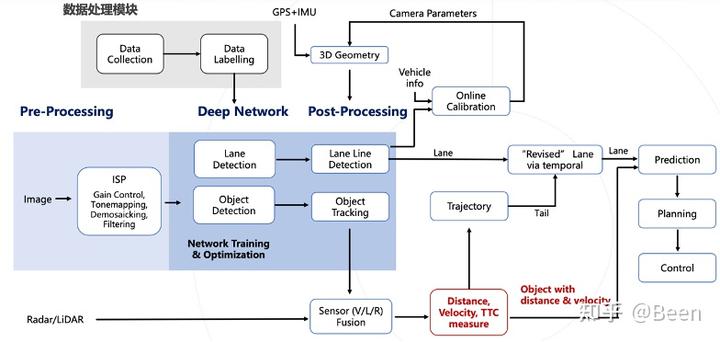
首先介绍自动驾驶在感知算法层面的流程图,数据处理模块是非常重要和关键的模块,其中包括大规模数据采集,车道线上传以及自动标注等过程。Image signal Processing(ISP)模块用于调节性噪比、白平衡、颜色通道等成像质量方面的内容。Network training & Optimization 用于 Object detection 、Lane detection 相关的工作。自动驾驶是一个非常复杂的系统,需要多传感器的融合,比如需要结合车道线的检测结果与自车信息进行在线标定,再结合车辆自身的 GPS、惯导等信息,动态地来输出车身位姿等 3D Geometry。随后将最终的车道线与目标检测结果输入到决策规划控制模块。
本次课程主要介绍 Object Detection 和 Lane Detection,包括在单目和 3D 两个 setting 下的工作的介绍。
Part 2 3D 物体检测
2.1 背景介绍
3D 目标检测在整个自动驾驶的 Pipeline 里是非常重要的一环,轨迹预测、意图判断、报警、规划控制等环节需要有 3D 信息作为输入源。其中一种检测方案,是直接使用 Lidar、Radar 等带有 3D 信息的传感器,或者使用 Camera,通过网络学习 2D 到 3D 的映射关系。Camera 所需的配置比较简单,成本低;在实际的工程化落地的过程当中,在雨雪或雾霾天气下,Camera 的鲁棒性要更高,且检测距离更远,30 fov 的相机可以达到 300 米。
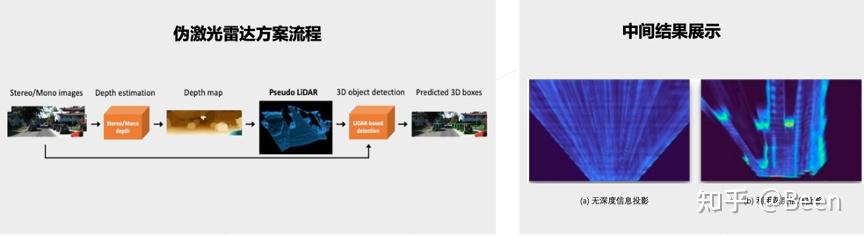
有关 3D 检测任务的 paper 大致可以分成两类。第一类是 Pseudo-Lidar 的方法,通过 image 的 depth map 和对应的 image 的信息,投影到世界坐标系下,再套一个 3D 点云检测的 Pipeline,就可以进行预测。这种方法的优势是受内外参影响比较小,在 BEV 视角检测可以缓解目标远近尺寸不一致的问题,且朝向回归更加直观。第二类是直接通过 image 进行回归,对图片做预处理和 feature 提取后得到中间结果,利用这些结果做网络的 forward,得到最终的 3D 结果。此种方案更加受欢迎,且耗时较小。
在实际应用中,3D 检测任务存在一些问题,例如 Mono3D 模型对内外参依赖严重,截断、遮挡目标的检测性能下降明显、远距离小目标检测性能下降明显等。
从这些问题出发,下面将介绍本团队的一些研究工作。
2.2 Exploring Intermediate Representation for Monocular Vehicle Pose Estimation
本工作的出发点在于,目前 3D 物体检测对朝向的预测不太准确,希望能够做一些额外的优化。其次希望不直接去回归 3D 检测框,而是利用中间的结果,对中间结果做一些约束,再通过 Geometry 的变化得到 3D 信息。
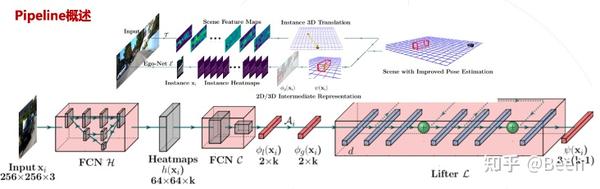
本工作的方案分成两部分。上支路预测定位信息,即 location;下支路对单个目标预测关键点的 heatmap,location,输出局部朝向信息 。将局部预测结果投回到全局空间,输出最终的 3D 检测结果。
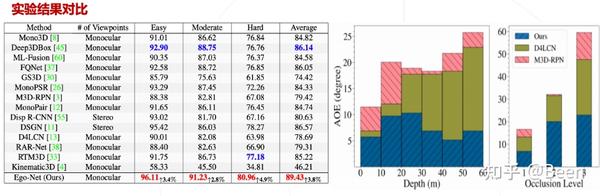
实验结果表明,性能得到了明显的提高,并且可以较好地嵌入 M3D-RPN 网络。且不同距离下的误差较为稳定。
2.3 Monocular 3D Object Detection: An Extrinsic Parameter Free Approach
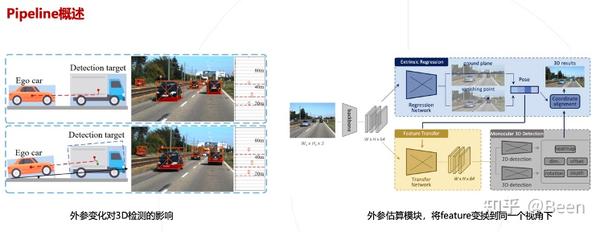
这项工作主要解决外参变化的影响。车辆行驶中的颠簸会引起外参的变化,导致 3D 检测的深度预测不太准。这种任务需要额外的分支去预测外参,利用估算出来的相机外参把 Backbone 提出来的 feature 变化到同一个视角下,对同一视角的 feature 做 2D 检测和 3D 检测回归。
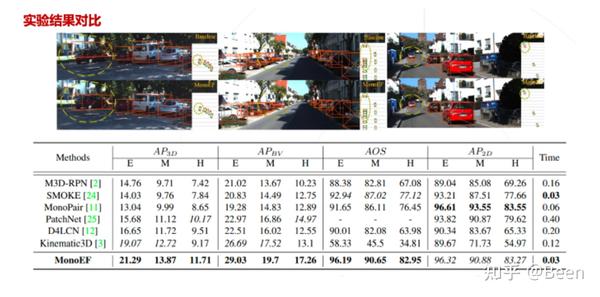
实验结果表明,在不同视角下获得的效果比较明显,尤其在颠簸路段,可以使稳定性获得较大提升。
2.4 总结
● 增加多种图像平面的检测点,用于辅助提升 3D 检测的性能
● 增加 2D 和 3D 的一致性约束,有助于模型性能提升
●深度信息对 3D 目标检测性能提升明显,对截断目标也有一定帮助
● BEV 视角下的 3D 检测能将任务简化,对远近目标不一致问题又较大的优化
●利用模型估算相机外参数,可以提升模型的泛化性能
Part 3 3D车道线检测
3.1 问题介绍与动机
车道线检测是从图像分割开始的,但由于在实际控制规划等后续模块中,需要在世界坐标系下,所以车道线检测有以下几个步骤:图像平面的车道线检测、投影到 (水平) 地面 (IPM, inverse perspective mapping)、根据车道线模型进行拟合等后处理。
但是这种方法存在一定的问题。如果用单目去做车道线检测,不依托别的模块,比如说在线标定等,车道线会在 BEV 下出现非常严重的抖动,且水平路面假设在复杂场景 (上下坡等) 不成立。学术数据集 (CULane/TuSimple等) 在线型/路沿等 attribute 上的缺失,与量产应用存在差异 。
3.2 现有工作介绍
AAAI 2018 https://arxiv.org/abs/2103.12040
In ArXiv https://arxiv.org/abs/1712.06080
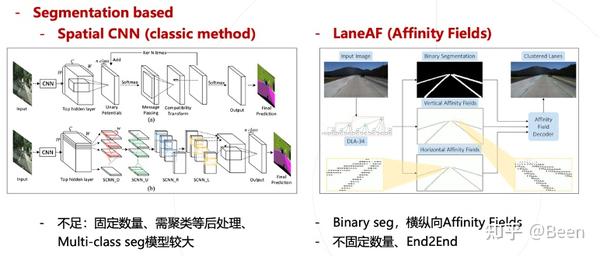
从 2D 的经典的方法,例如 Special CNN 开始考虑,基于分割的任务去做 multi class 的分割,预测四条车道线。这个方法非常经典,但也有些不足,如固定的数量多车道线、需要聚类等后处理、模型比较大等。
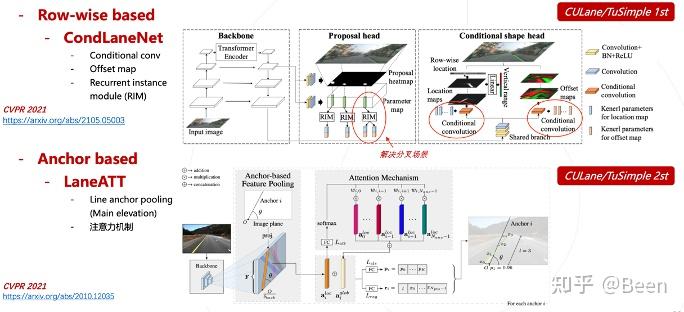
一些 SOTA 的方法,如 LaneAF 引入了 Affinity Fields 的概念,打破了固定数量的限制。另外还有一些 Row-wise 的方法,其中比较代表性的是 CondLaneNet,这是阿里的一个工作,利用 conditional convolution,实现了更精细的车道线检测,并且引入了 Recurrent instance module 用于解决车道线分叉场景。
在 Anchor based 的 LaneATT 中,用一条线作为 anchor,并且在整个图片的左右、下面设置了上千个 anchor,对车道线关于 anchor 的 offset 进行回归,在车道线检测方面提升了很多点。
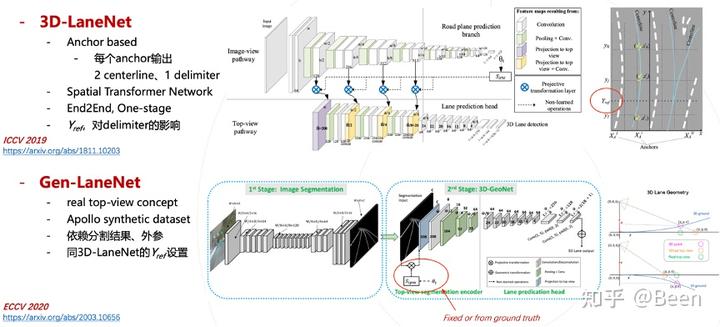
在3D车道线检测中具有代表性的是 3D-LaneNet 和 Gen-LaneNet。
3D-LaneNet 是一个一阶段模型,采用了 Anchor Based 的方法;Gen-LaneNet 是基于 3D-LaneNet 的提升,它是一个二阶段模型。第一阶段首先对 2D 层面进行图像分割,然后利用外参的真值将分割的图像投影到 virtual top view,最终预测得到 3D 下的结果。
3.3 未来可延伸方向讨论
在模型方面:
● Learning-based Online Calibration
● Incorporating Temporal Info
● Take-aways from 2D Lane Detection
● Take-aways from Depth Estimation, Object Detection, Multi-task learning
在数据集方面:
● Real world 3D Evaluation Metrics
● AP/F1 in different x/y
● Category/type:虚/实/黄/白
● Others:路沿/Stopline等
Part 4 实际量产方面对感知模块的需求和思考
在学术界中,以自动驾驶为例,需要检测图像里面所有的物体,mAP 越高越好,但在工业界,我们只关心 CIPO(危险目标),且泛化能力一定要强,并且需要考虑算力与性能的 trade off。
从纯学术技术到量产落地:工业界考量因素
● Philosophy 1: 相对自车,更关心前方物体和左右车道线,要求性能 maximize in all circumstances
● Philosophy 2: 相比bounding box,更关心3D空间下(x,y,z)的 物体间位置关系,即物体位置(深度)、速度、 加速度、轨迹
● Philosophy 3: 性能很重要,同时关心模型在某款芯片上部署时的 效率问题;希望多任务学习,最大化利用芯片资源
● Philosophy 4: 大规模数据采集、处理、部署
Part 5 Q&A
1. 请问多任务方案是怎么做的?
多任务方案大致有两个派别,一个是从 optimization 的角度算 loss,另一个是改网络的 architecture。多任务学习最重要的就是 task A 和 task B,同时学的时候能不能互相帮助,甚至带来提升。前提是这两个任务要比较像,例如 tracking 和 detection 是前后模块,有高度绑定的关系,可以互相来提升。或者引入一个额外的任务,其中包含 feature 或者 domain knowledge,帮助 task A 和 task B 同时提升。
2. 前向运动 co-image 是不是会退化?
激光雷达是一圈采集,转一圈只打一个点。在自车有运动的情况下,确实会有一些畸变。自车相对其他静止目标的畸变可以靠自车的运动信息做补偿。如果自车和其他目标之间有相对运动,只靠自车信息补偿是不够的。在数据出真值的时候,根据多帧的信息去判断,做一个运动模型,根据这个运动模型,对目标车上的激光雷达点云做补偿。
3. 深度信息如何获得?
深度信息可以直接通过激光点云获得。















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









