







一、流关卡streaming level
流关卡顾名思义,即关卡数据可以以数据流的形式加载到游戏中,这个过程就像加载其他的角色数据一样,非常平稳,对当前的关卡没有影响。具体的表现效果就是,当你在场景A中向场景B行走的时候,B场景会在你事先指定好的地点(或者其他条件)加载进来,而你感觉不到B场景的加载过程,好像原来B场景就存在一样,这样玩家就会觉得仿佛置身于一个大场景一样。
在UE4里面,每一个World里面至少有一个PersistentLevel以及0-N个StreamingLevels。在编辑器里面通过Windows—Levels窗口即可查看。点击Levels按钮,可以创建新的level或者是添加已经存在的level。
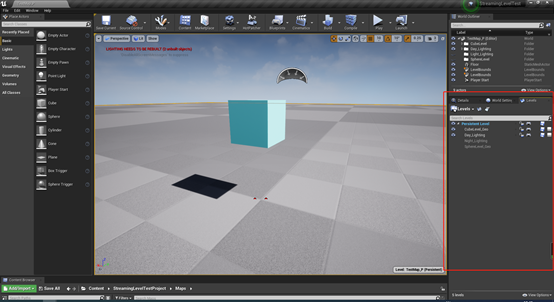
关卡名字颜色不同代表不同的状态:蓝色代表当前关卡,白色代表已经加载进来的关卡,灰色代表未加载的关卡。
控制流关卡的加载总体上来说有两种方式,一种是通过关卡流体积控制(LevelStreamingVolume),另一种是通过脚本(代码)逻辑控制。简单描述一下两个方法,第一种,LevelStreamingVolume相当于一个定制的触发器,当玩家摄像机(注意是玩家摄像机)进入LevelStreamingVolume体积内的时候,对应的流关卡就会加载(对应关系是通过下图操作设置的点击levels旁边的按钮打开leveldetails窗口 inspectlevel找到需要加载的流关卡添加对应的LevelStreamingVolume)。第二种,可以随意调用加载,最简单的方式就是设一个触发器在玩家进入触发器的时候调用LoadStreamLevel。
二、世界构成器World Composition
流关卡给我们提供了一个大世界的解决方案,但是实际操作上由于每个level关卡都可能非常大,我们在编辑器里面一点点调整流关卡里面的Actor位置实在是过于麻烦,所以UE提供了世界构成器功能,简单来说就是帮你把N个关卡用拼图的形式拼接成一个大世界地图。
想使用这个功能,首先你需要在当前的WorldSetting里面勾选 Enable World Composition (如果当前你的world里面已经添加了子关卡,那么是无法开启该功能的)。当你开启该功能的时候他会弹出一个界面提示你将会把同一个文件夹内的所有level作为当前persistent level的流关卡,点击OK即可。
这时候新加入的流关卡并没有激活,所以是灰色的。右键该地图选择Load选项,就会把NewMap加入当前的level里面,此时在编辑器里面你就可以看到子关卡的物件了。
这时候有一个问题,你发现无论怎么设置,运行游戏的时候NewMap都会和Persistent Level一同加载到当前的Level里面。因为世界构成器默认的加载逻辑就是当玩家距离要加载的关卡满足一定数值时就会加载对应的子关卡。而由于你刚把NewMap加载到当前的World里面,他被默认放到了默认分组的下面,NewMap的默认位置就是当前世界的原点位置,满足默认距离50000(500米),所以一开始运行的时候就会加载进来。
可以点击下图按钮进入分组设置,也就是层的编辑。
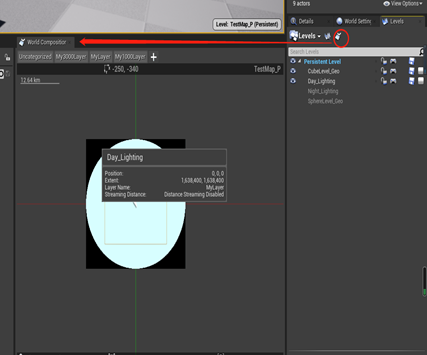
在worldCompositior界面可以设置自定义层,设置层的名称,距离(CM)和层里所包含的关卡。将关卡分配给自定义层的方法如下:
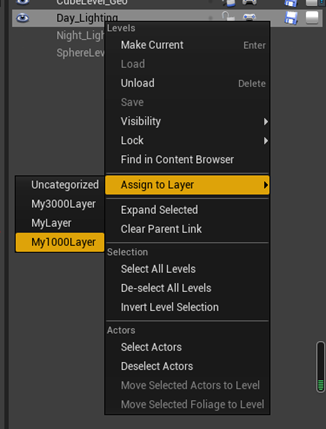
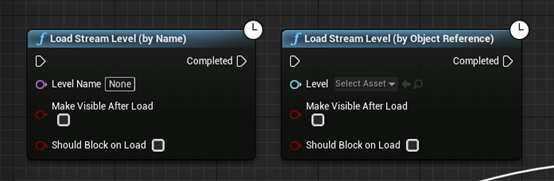
重点是可以取消距离设置,这样就可以用第一部分介绍的StreamingLevel的加载方式来加载用其他条件进行加载与卸载的场景;加载函数如下:
三、注意事项
1. 当在WorldSettings里面勾选EnableWorldComposition的时候,引擎会帮助我们在World里面创建一个新的Actor,这个Actor的默认名字是LevelBounds,通过去掉AutoUpdateBounds属性并重新设置Scale大小,就可以自定义level的大小了。
2.世界构成器的层初始创建后就无法被编辑和删除,需要将弃用层里的场景清出去之后重启,才可以将层自动删除。


















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









