







总结
GraspGAN 并非端到端的抓取方法。GraspGAN 是一个用于域自适应(domain adaptation)的模型,其主要目的是通过对抓取任务的模拟数据进行适应,使其更适用于真实世界的数据。具体而言,GraspGAN 通过对合成图像进行领域自适应,使其更接近真实图像,从而提高了抓取方法在真实世界中的性能。
GraspGAN 的工作流程如下:
-
Generator(生成器): GraspGAN 中的生成器采用 U-Net 结构,用于将原始的合成图像转换为外观更真实的图像。这个过程是通过卷积神经网络完成的,其中使用了 average pooling 进行降采样,bilinear upsampling 进行上采样,concatenation 和 1x1 卷积进行 U-Net 的跳跃连接,以及实例归一化进行图像标准化。
-
Discriminator(判别器): GraspGAN 中的判别器是一个基于补丁的卷积神经网络(CNN),用于评估生成的图像的真实性。它在多个尺度上操作,对两个输入图像进行评估,以计算联合判别器损失。这个设计允许判别器学习评估生成图像的全局一致性和局部纹理的真实性。
-
Loss Terms(损失项): 为了确保生成的图像在外观上更真实的同时保留合成输入的语义信息,GraspGAN 引入了多个损失项。这些包括 PMSE 损失(图像外观损失),语义分割损失,以及通过对比两个图像的最终卷积层激活的损失项。这些损失项的目标是保持生成的图像的语义信息,确保它们在抓取任务中的有效性。
总体来说,GraspGAN 通过生成器和判别器的协同工作,对合成图像进行领域自适应,使其更适用于真实世界数据。生成的图像用于改善抓取方法在真实世界中的性能,但 GraspGAN 本身并没有直接执行抓取动作,而是专注于图像的领域适应。
摘要
为训练现代机器学习算法而建立和收集有注释的视觉分析数据集,可能会非常耗时和昂贵。一个有吸引力的替代方法是使用现成的模拟器来渲染合成数据,并自动生成地面实况注释,但不幸的是,纯粹在模拟数据上训练的模型往往不能推广到真实世界。我们研究了如何将随机模拟环境和领域适应方法扩展到训练抓取系统,以便从原始单目 RGB 图像中抓取新物体。我们利用总共超过 25,000 个物理测试抓取对我们的方法进行了广泛评估,研究了一系列模拟条件和域适应方法,包括我们称之为 GraspGAN 的像素级域适应的新扩展。我们还表明,通过仅使用未标记的真实世界数据和我们的 GraspGAN 方法,我们在没有任何真实世界标签的情况下获得的真实世界抓取性能,与使用 939,777 个标记的真实世界样本所获得的性能相似。


1. 介绍
2.相关工作
Robotic grasping
Simulation-to-real-world transfer in robotics
Domain adaptation
3.背景
A. Deep Vision-Based Robotic Grasping
B. Domain Adaptation
4.我们的方法
A. Grasping in Simulation
这段文字描述了在构建机器学习算法的模拟器时面临的主要困难,即确保具有足够多样性以有效推广到真实世界的设置。为了评估从模拟到真实世界的转移,作者使用了一个真实世界抓取尝试的数据集以及在模拟中使用多个类似数据集。以下是实现的主要步骤:
真实世界数据集: 使用了一个包含真实世界抓取尝试的数据集,该数据集用于评估算法在真实硬件环境中的表现。该数据集可能包含机器人试图在真实世界场景中抓取物体的记录。
虚拟环境和模拟器: 基于 Bullet 物理模拟器和其附带的简单渲染器构建了一个基本的虚拟环境。该环境模拟了 Kuka 硬件设置,通过模拟抓取的物理过程以及渲染从 Kuka 肩膀上方看到的图像,包括机械臂、包含物体的箱子以及类似于真实世界中机器人遇到的场景中的待抓取物体。
模型的多样性: 在虚拟环境中评估了两种不同来源的物体模型的真实性。一种是通过随机生成几何形状的方式得到的,另一种是使用公开可用的 ShapeNet 3D 模型库获取的真实物体模型。对于随机生成的物体,作者生成了 1000 个对象,通过在随机位置和方向附加矩形棱柱来模拟几何形状。这些物体随后被转换为网格,并应用了随机水平的平滑。每个物体都被赋予了UV纹理坐标和随机颜色。对于基于 ShapeNet 的数据集,使用了 ShapeNetCore.v2 集合,其中包含了55个类别的51,300个逼真物体模型。
物体的尺寸和质量: 对于所有物体,进行了尺寸和质量的随机设置,以模拟真实抓取场景。物体的最大尺寸在12cm和23cm之间,质量在10g和500g之间。
通过这些步骤,作者在虚拟环境中创建了具有多样性的模拟数据集,以用于训练机器学习算法,并评估其在真实世界场景中的泛化性能。这种方法旨在克服模拟到真实世界转移时常见的困难。
这段文字描述了在将模型导入模拟器后,如何通过与真实世界类似的流程收集模拟数据集。以下是主要步骤:
真实世界数据集收集过程: 在真实世界中,作者使用逐渐改进的夹持预测网络来收集数据集。这些网络会定期手动更换,但更换频率相对较低。使用了6台物理 Kuka IWA 机器人在真实世界中收集数据,通过逐步提高的夹持预测网络来实现。
模拟数据集收集过程: 在模拟环境中,与真实世界类似,通过使用模拟机器人进行抓取动作来收集数据集。不同之处在于,模拟环境中使用了1,000到2,000个模拟机械臂同时工作,用于收集合成数据。与真实世界不同,这些模拟机械臂的模型是由一个自动化流程不断更新的,因此收集的数据集受到夹持预测网络性能不同而产生的多样性影响。
模型的更新: 模拟环境中的模型是通过自动化过程不断更新的,这使得在收集数据时使用的夹持预测网络的性能会有所不同。这种不断更新的过程增加了收集样本的多样性。
抓取成功率: 在模拟环境中,经过训练的夹持方法在70%到90%的模拟抓取尝试中取得了成功。这表明在模拟环境中进行训练后,模拟机器人相对成功地执行了抓取动作。
总体而言,作者通过在模拟环境中使用多个模拟机械臂并不断更新它们的模型,以及使用逐步改进的夹持预测网络,收集了具有多样性的模拟数据集。这些数据集后来被用于训练夹持方法,并评估其在真实世界中的性能。
B. Virtual Scene Randomization
C. Domain Adaptation for Vision-Based Grasping
这段文字描述了两种主要用于域自适应的方法:特征级别和像素级别。作者提出了一种特征级别的自适应方法和一种新颖的像素级方法,称为GraspGAN。以下是算法的主要步骤:
特征级别自适应: 提出了一种特征级别的自适应方法,其中使用了领域自适应损失(DANN loss)在抓取成功预测模型的最后一个卷积层上。该方法的目标是通过适应原始合成图像的特征,使其看起来更真实。
GraspGAN像素级自适应: 引入了一种新颖的像素级域适应方法,称为GraspGAN。该方法通过给定原始合成图像生成适应的图像,使其外观更真实。GraspGAN的训练生成器被用作固定模块,用于调整合成视觉输入。
训练生成器: 使用GraspGAN生成器对合成图像进行训练,将其调整为更逼真的外观,然后将其用作适应合成视觉输入的固定模块。
特征提取和适应: 在特征级别上进行域适应,考虑了转移图像和合成运动命令输入的提取特征。对于特征级别自适应,使用了DANN损失,该损失在抓取成功预测模型的最后一个卷积层上应用。
批次规范化(Batch Normalization): 在模型中的每一层都使用了批次规范化。在两个领域的数据混合中,作者考虑了批次规范化与DANN损失的交互,提出了一种称为领域特定批次规范化(DBN)混合的训练方式。这种方法考虑了来自模拟和真实世界数据的不同统计信息,并使用相同的参数进行培训,证明了它在域自适应中的实用性。
总体而言,该算法通过在特征级别和像素级别上应用域适应方法,实现了从合成图像到真实世界的抓取系统训练。GraspGAN的引入为合成数据的外观逼真性提供了提升,而领域自适应方法通过调整特征级别的模型参数,使其能够在真实世界中更好地泛化。
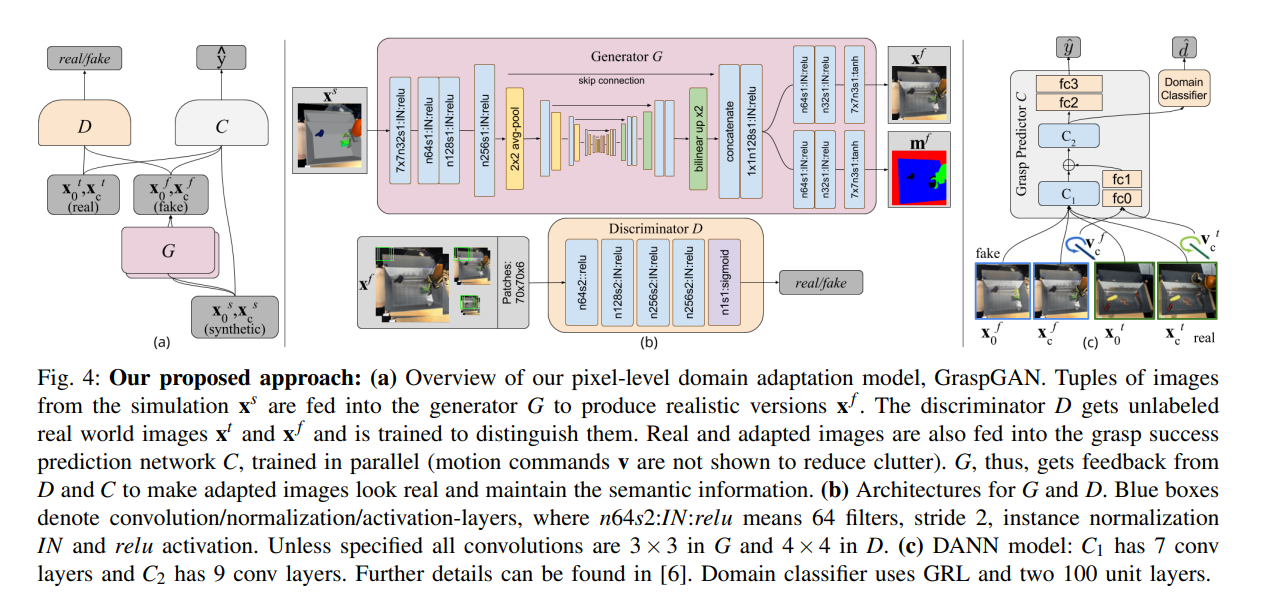
这段文字描述了像素级域自适应模型 GraspGAN 的结构,以及其中所使用的神经网络架构和组件。以下是实现抓取的关键步骤:
生成器 G: GraspGAN 中的生成器 G 是一个卷积神经网络,采用 U-Net 架构,具有下采样的平均池化、上采样的双线性插值、U-Net 跳跃连接的串联和 1x1 卷积,以及实例归一化。该生成器负责将原始合成图像调整为更逼真的图像。
判别器 D: GraspGAN 中的判别器 D 是基于图像块的卷积神经网络,采用了具有 5 个卷积层的架构,有效输入尺寸为 70 x 70。判别器在两个输入图像 xg 和 x(堆叠成 6 通道输入)的三个尺度上都是全卷积的(472 x 472、236 x 236 和 118 x 118)。它为所有图像块生成域估计,然后将它们组合以计算联合判别器损失。这种多尺度基于图像块的判别器设计使其能够学习评估生成图像的全局一致性以及局部纹理的真实性。
任务模型 C: 任务模型 C 是来自先前研究的抓取成功预测卷积神经网络(CNN)。这个模型用于评估生成的抓取图像的成功与否。
总体而言,GraspGAN 模型通过生成器 G 调整合成图像,使其更逼真,并通过判别器 D 来评估生成图像的真实性。任务模型 C 用于评估生成的抓取图像的成功。这个系统通过在生成器和判别器之间进行对抗训练,从而实现像素级域自适应,提高生成的合成数据在真实世界中的泛化性。


这段文字描述了在 GraspGAN 模型中引入的几个附加损失项,这些损失项旨在确保生成的图像在外观上类似于真实场景,同时保持模拟输入的语义信息。以下是实现抓取的关键步骤:
PMSE 损失: PMSE(Pixel Mean Squared Error)损失是用于限制生成图像与输入图像之间差异的一种损失。通过最小化生成图像与输入图像的像素均方误差,确保生成的图像在外观上不发生明显的变化。
语义分割掩码: 利用语义分割掩码,对合成图像的每个像素进行语义级别的标注,包括背景、托盘、机器人手臂和物体等。生成器 G 进行训练,使其额外输出语义分割掩码 mf,并使用标准的 L2 重建损失,强制生成器提取场景中所有物体的语义信息,并将其编码为中间潜在表示。
密集反馈: 引入一种提供比仅关于抓取成功的单一位信息更为密集的反馈的损失项。通过惩罚任务网络 C 最终卷积层的激活之间的差异,鼓励生成的图像向任务网络提供与相应模拟图像相同的语义信息。这与感知损失原理相似,后者使用 ImageNet 预训练的 VGG 模型的激活作为对输入图像进行重新风格化的一种方式。
总体而言,这些损失项有助于确保 GraspGAN 生成的图像在外观上保持与真实场景相似,同时保留了模拟输入的语义信息,以确保模型在训练任务网络时能够提供有效的信息。这些损失项的使用旨在防止生成图像发生不良变化,以保持其在语义上的一致性。
















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









