








Lecture 3:Model-free Prediction and Control
前节回顾
在已知模型的时候,我们可以利用贝尔曼方程,和贝尔曼最优方程通过策略迭代和价值迭代进行更新。但是我们都需要知道概率和奖励,不需要与环境交互就可以更新。
Model-free Prediction
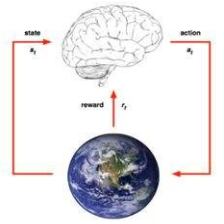
现在我们不知道MDP的模型 ,通过与环境交互,采集轨迹数据
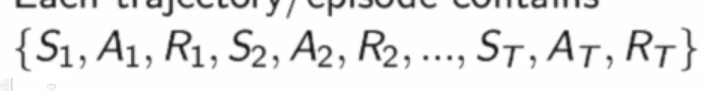
两种方法:MC,TD
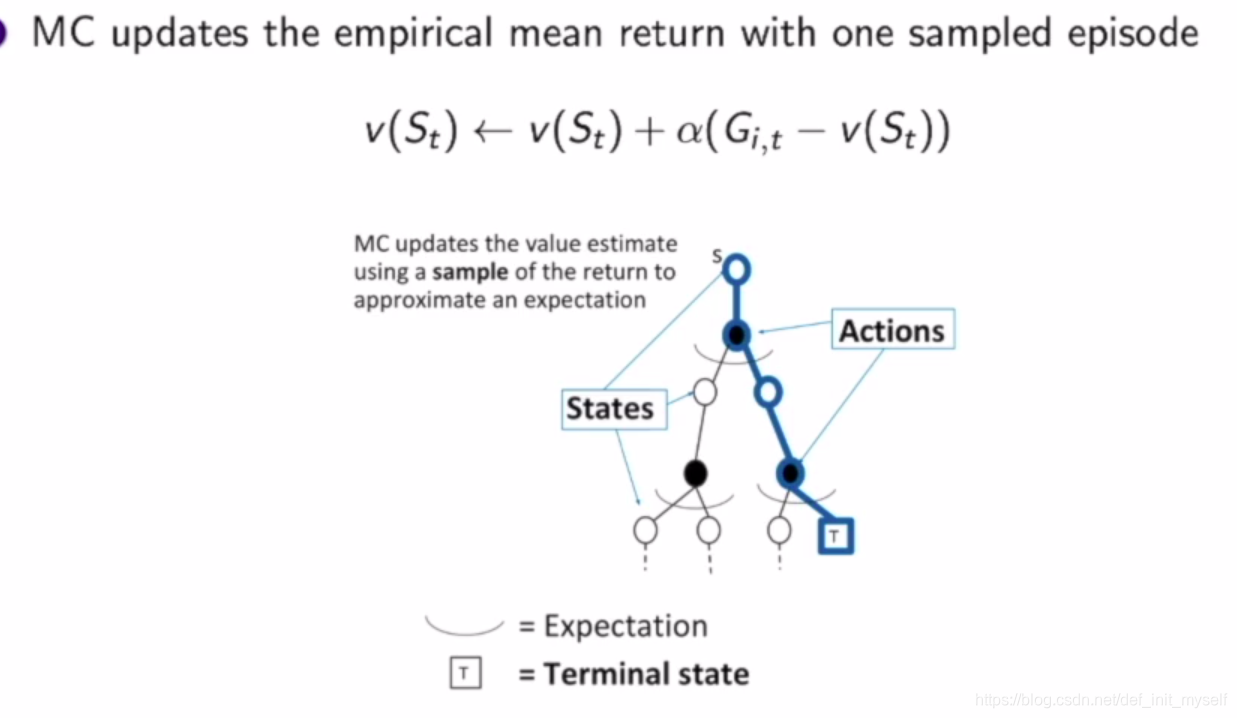
基于蒙特卡洛采样(MC)
通过与环境交互,获取实际的回报取平均,可以得到每个状态的价值。但是只能用在可以终止的MDP过程。
采取增量式平均
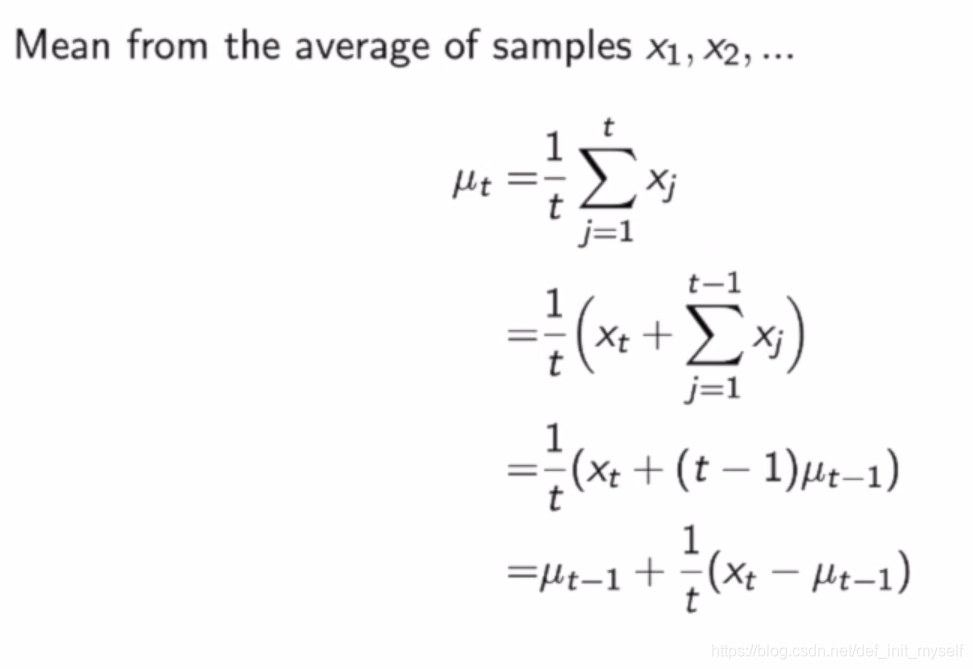
用在MC中:

a可以看作更新速率。
动态规划是利用自举的方式不停迭代,收敛。对于MC方法,通过实际收益更新,类似于蓝色的轨迹,每个时刻什么行为,到达什么状态都是确定的。所以只更新得到的状态,减小了更新成本,这也是与DP的区别。
基于时间差分(TD)
是动态规划和采样的结合,并且可以工作于没有终止的环节。

最简单的是TD(0),每走一步更新。由两部分组成,一部是分实际奖励,另一部分利用类似动态规划的方法,利用之前的估计更新。
其中的TD误差,就是TD target-V(s)
与蒙塔卡罗区别是,target一个时需要全部结束才能获得,一个只走一步就可以更新。
区别的表格:

需要注意的是:
TD可以是在线的,同时在Markov环境下由更高的效率。
MC没有这种要求
TD推广,n步TD
自举和采样

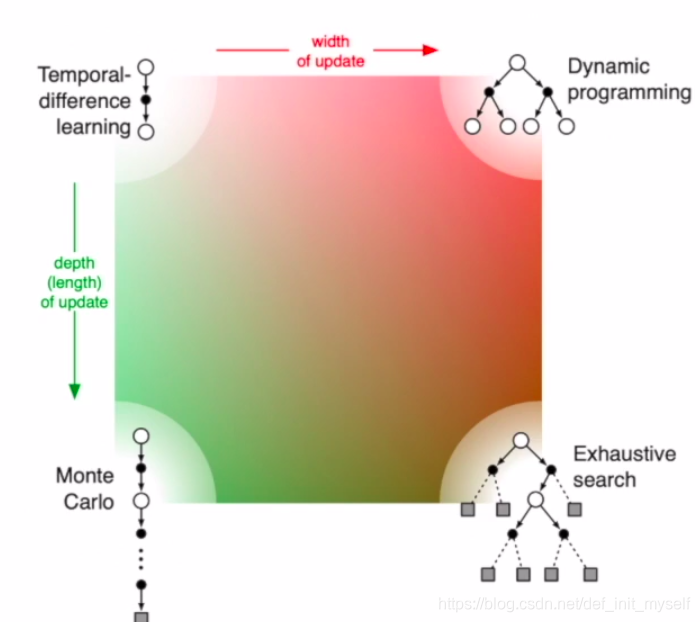
Model-free Control
策略迭代复习

这里面临的问题是在不知道奖励函数和转移概率的情况下如何进行策略优化
广义策略更新
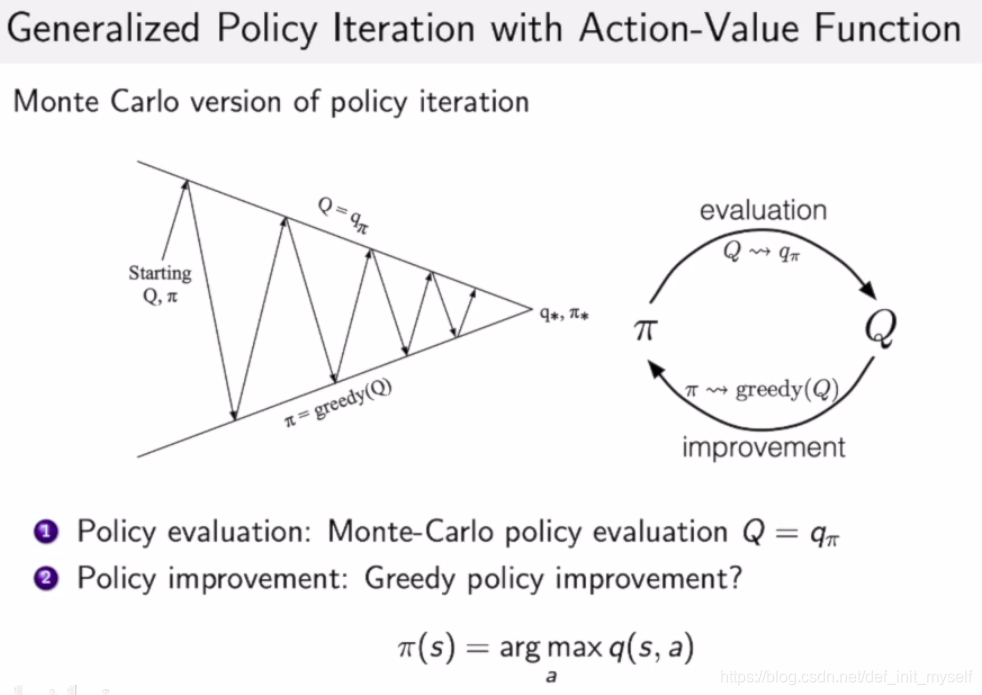
MC
用MC更新,需要试探每一个开始,最后进行平均。然后再根据表格选动作。
 更新策略的时候:探索和收益之间的Trade-off
更新策略的时候:探索和收益之间的Trade-off

可以证明,这样的策略也是比之前的好的,见强化学习导论。
算法表示:

TD
低方差,可以处理不完整序列。
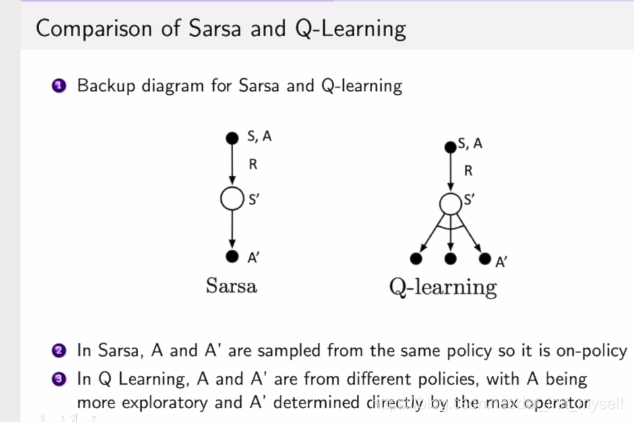
SARSA
下一步也是通过策略pi采样。

也可以有n步sarsa。
离线学习Q-Learning
可以学到最优策略
同时可以学习其他agent的,比如模仿人的
第三可以利用以前的经验去学习

ε可以随时间减小,到最后两者会相近。
 与sarsa不同的是第二步不需要采样动作,而是取max。
与sarsa不同的是第二步不需要采样动作,而是取max。
代码地址
https://github.com/cuhkrlcourse/RLexample/tree/master/modelfree















 4081
4081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









