






1. 前言
自主导航是移动机器人领域的核心任务之一,传统路径规划方法(如 Dijkstra、A* 和 DWA)虽然在静态环境中表现良好,但在动态环境中往往难以适应变化。强化学习(Reinforcement Learning, RL)为机器人导航提供了一种新的思路,使机器人可以通过与环境的交互不断优化策略,从而实现高效自主导航。
本文使用 Stable-Baselines3 (SB3) 训练 ROS2 机器人自主导航,利用深度强化学习算法 Proximal Policy Optimization (PPO) 来训练机器人在 Gazebo 仿真环境中自主避障和路径规划。本文内容包括:
-
强化学习原理及 PPO 算法
-
机器人导航强化学习环境的构建
-
ROS2 与 Gazebo 的整合
-
训练过程、策略优化及仿真验证
-
实验结果分析
2. 原理介绍
2.1 强化学习基础
强化学习 (Reinforcement Learning, RL) 通过智能体(Agent)在环境(Environment)中采取行动(Action),获取奖励(Reward),并不断优化策略(Policy),以最大化累积奖励。
强化学习的基本框架如下:
-
状态 sts_t : 机器人当前感知到的环境信息,例如激光雷达数据。
-
动作 ata_t : 机器人可采取的操作,如前进、左转、右转。
-
奖励 RtR_t : 机器人根据动作获得的反馈,例如避免碰撞或接近目标。
-
策略 π(a∣s): 在状态 s 下采取动作 a的概率分布。
强化学习的目标是找到最优策略 π∗ 使得期望累计奖励最大:
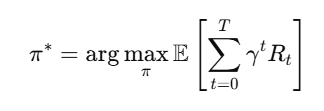
其中:
-
γ 为折扣因子,控制未来奖励的重要性,通常取 γ=0.99。
-
T 为最终时间步数。
2.2 PPO 算法
Proximal Policy Optimization (PPO) 是强化学习中最常用的策略优化方法之一,它通过对策略更新的限制,提高训练稳定性。
PPO 目标函数:
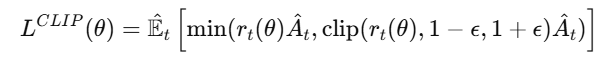
其中:
-
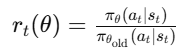
是新旧策略的比值。
-
A^t是优势估计(Advantage Estimation)。
-
ϵ控制策略更新幅度,避免过大更新导致训练不稳定。
PPO 采用 截断策略比值 (Clipped Surrogate Objective) 来避免策略更新过大,保证训练稳定性。
2.3 机器人自主导航的强化学习流程
机器人自主导航强化学习流程如下:
-
构建 ROS2 环境:搭建机器人模型,并集成 Gazebo 进行仿真。
-
定义强化学习环境:将机器人传感器数据转换为状态,定义动作空间和奖励函数。
-
使用 Stable-Baselines3 训练 PPO 策略:智能体通过不断交互学习最优导航策略。
-
评估和优化模型:调整超参数,提高导航成功率。
-
部署到真实机器人:将训练好的模型部署到真实机器人上进行测试。
3. 部署环境介绍
3.1 软硬件环境
-
操作系统:Ubuntu 20.04
-
ROS2 版本:Foxy
-
仿真环境:Gazebo 11
-
Python 版本:3.8
-
强化学习框架:Stable-Baselines3
-
硬件:NVIDIA GPU (可选, 用于加速训练)
3.2 依赖安装
sudo apt update && sudo apt upgrade -y sudo apt install ros-foxy-gazebo-ros ros-foxy-nav2-bringup pip install stable-baselines3 gym torch numpy
4. 部署流程
4.1 启动 Gazebo 仿真
export TURTLEBOT3_MODEL=waffle ros2 launch turtlebot3_gazebo turtlebot3_world.launch.py
4.2 训练机器人
python3 train.py
4.3 部署训练策略
python3 deploy.py
5. 代码示例
5.1 强化学习环境
创建 robot_env.py,定义 RL 训练环境:
import gym
import numpy as np
import rclpy
from rclpy.node import Node
from sensor_msgs.msg import LaserScan
from geometry_msgs.msg import Twist
class RobotEnv(gym.Env):
def __init__(self):
super(RobotEnv, self).__init__()
self.node = rclpy.create_node('robot_env')
self.laser_sub = self.node.create_subscription(LaserScan, '/scan', self.laser_callback, 10)
self.vel_pub = self.node.create_publisher(Twist, '/cmd_vel', 10)
self.action_space = gym.spaces.Discrete(3)
self.observation_space = gym.spaces.Box(low=0.0, high=10.0, shape=(360,), dtype=np.float32)
def laser_callback(self, msg):
self.laser_data = np.array(msg.ranges)
def step(self, action):
twist = Twist()
if action == 0:
twist.linear.x = 0.2
elif action == 1:
twist.angular.z = 0.5
elif action == 2:
twist.angular.z = -0.5
self.vel_pub.publish(twist)
reward = -1.0 if min(self.laser_data) < 0.5 else 1.0
return self.laser_data, reward, False, {}
def reset(self):
return np.zeros(360)
6. 训练 PPO 代理
创建 train.py:

















 8539
8539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









