






前言:
好久没有写开源项目推荐了,因为这块的流量一直很低。
我暂时还不太喜欢标题党,所以很多同学刷到了,基本上也不会点击,看了也不会点赞,点关注~
但近一周出现了好几个非常有用的项目,我自己试了一下,相比之前同类的产品,基本上都有了本质的突破,几乎可以达到实用的地步。
这让我不得不花点时间,和大家共享一下这些信息。
感恩开源社区的贡献,也呼吁大家,能够对帮助到自己的项目,点点star。
Parler:高质量-高可控英文TTS模型+数据集
代码(如果对大家有帮助,记得star一下):https://github.com/huggingface/parler-tts
演示(大家可以实测玩玩):https://huggingface.co/spaces/parler-tts/parler_tts
Huggingface开源的高质量 TTS 模型的推理和训练库。
所有数据集、预处理、训练代码和权重均在许可下公开发布,这个是很少见的!
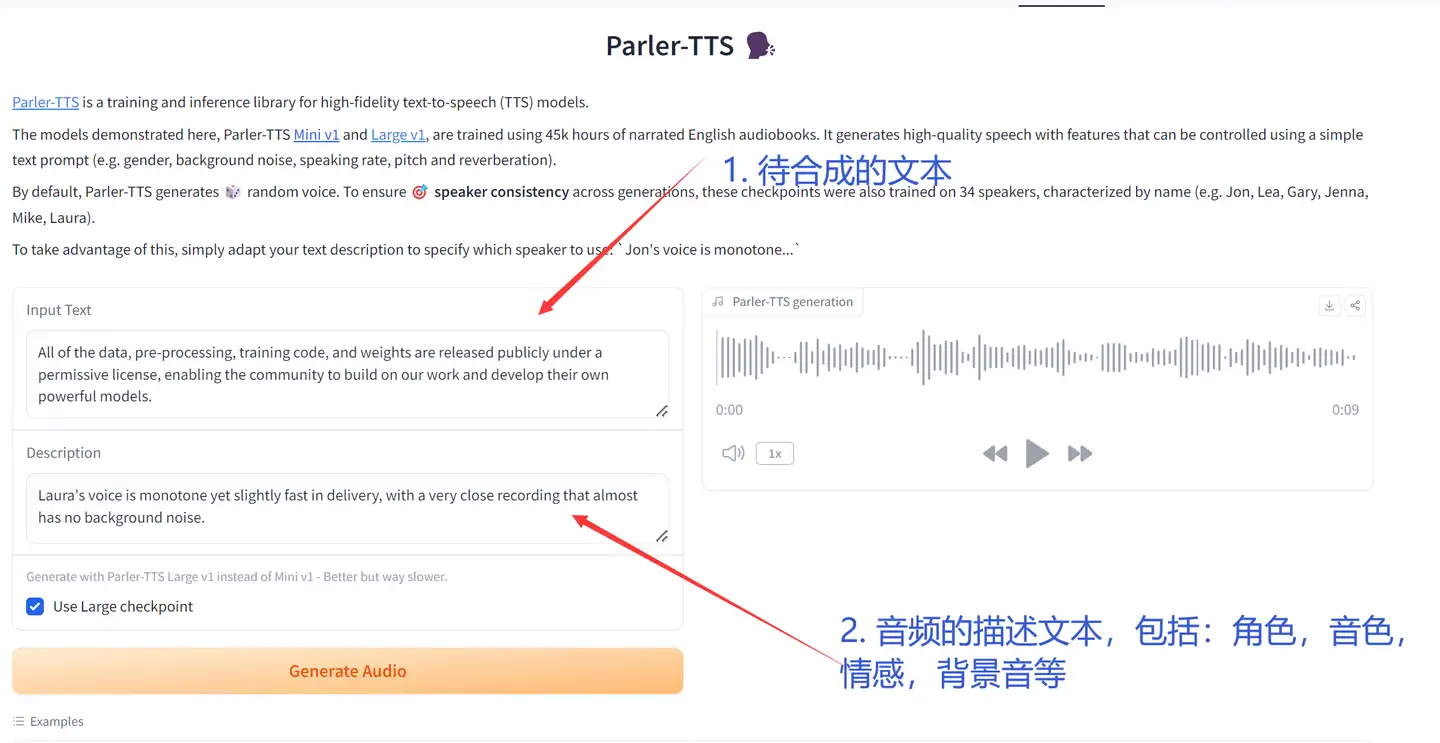
由于是英文,所以我标注一下~
个人实测:
- 1. 数据集和模型:只有英文,数据集主要包括一些电子书的音频,质量高。
- 2. 模型:可控性和声音质量不错,可以文本描述音频的性别、音调、说话风格等,目前来说,独一档的存在。
- 3. 适合读文章,但乱七八糟的符号会吞音
Mini-CPM-V 2.6:面壁智能开源的满血版小钢炮,接近4V性能且端侧可部署的多模态模型
代码:https://github.com/OpenBMB/MiniCPM-V
演示网站(针对自己的场景图片/视频,先试试效果):https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6
部署文档:https://modelbest.feishu.cn/wiki/C2BWw4ZP0iCDy7kkCPCcX2BHnOf
面壁这个项目非常有意思(实力),最初的版本一出来,就被斯坦福某位抄袭,然后火爆国内外,让国内网友直呼“倒反天罡”。
但我当时没有太关注,因为我总觉得这些项目太toy了,简单的OCR都做不好,更别说复杂的理解和问答了。
直到前两天,2.6发布,各大AI自媒体的宣传关键词,看着我都吓得慌:优于4V!端侧最强!比肩4O!
刚好我也在热榜上看到了,索性就在demo上试了一下,发现确实不一样,之前我能部署的开源多模态模型很多完成不了的任务,它确实可以稳定的产出,指令跟随能力和格式化输出能力也不错。
我自己在本机部署过,以及部署了vllm的并发服务,推荐的配置:
RTX3090显卡
Ubuntu20.04
Driver Version: 545.23.08
CUDA Version: 12.3
transformers 4.40.0
torch 2.4.0+cu124
torchaudio 2.4.0+cu124
flash-attn 2.6.3
更为关键的是,他们的文档齐全,官方团队在微信群非常积极的指导安装配置,点个赞!
个人评价:
- OCR准确率比较高,目标检测和识别我没怎么测试
- 指令跟随能力比较强,可以格式化输出,比较稳定
- 复杂表格识别能力一般,理解能力一般,毕竟才8B,不能指望太多;
- 能当一只眼睛,脑子还是得外接llm。
- 对显卡要求不算高,18G基本上就可以使用满血版。
- 尽量不要用int4的量化版!性能损失较为严重,我就不举例子了
- 有多模态需求,2.6版本上就完事了
TikTokDownloader:TikTok 抖音 数据采集工具
代码:https://github.com/JoeanAmier/TikTokDownloader
我没实测,就不点评了,但应该是有用的。用过的朋友欢迎评论区或者私信交流。
仅需一张图片即可实现实时换脸
代码:xxx
个人点评:这个项目争议非常大,我纠结过一段时间,到底要不要分享。
纠结了很久,还是不贴名字和链接了,因为这个项目底层没有做安全限制。
写到这个项目的唯一目的,就是建议大家,如非必要,不要在网络分享自己的自拍照!

本来想用鹰酱的图片,但怕侵权。
如上图所示,它的正脸换脸效果,非常猛,如果不仔细看的话,真人图片,几乎没法区分,非常容易用来造h谣。
最后在此声明,我个人不会绝不会利用该工具,在网上上传非法视频和图片。
大家也不要私信和评论区问我是什么项目,我不会回复这个问题。
qwen2-audio:阿里通义团队最新音频理解-对话开源模型-十边形
代码:https://github.com/QwenLM/Qwen2-Audio
演示网址:通义千问2-音频模型-对话
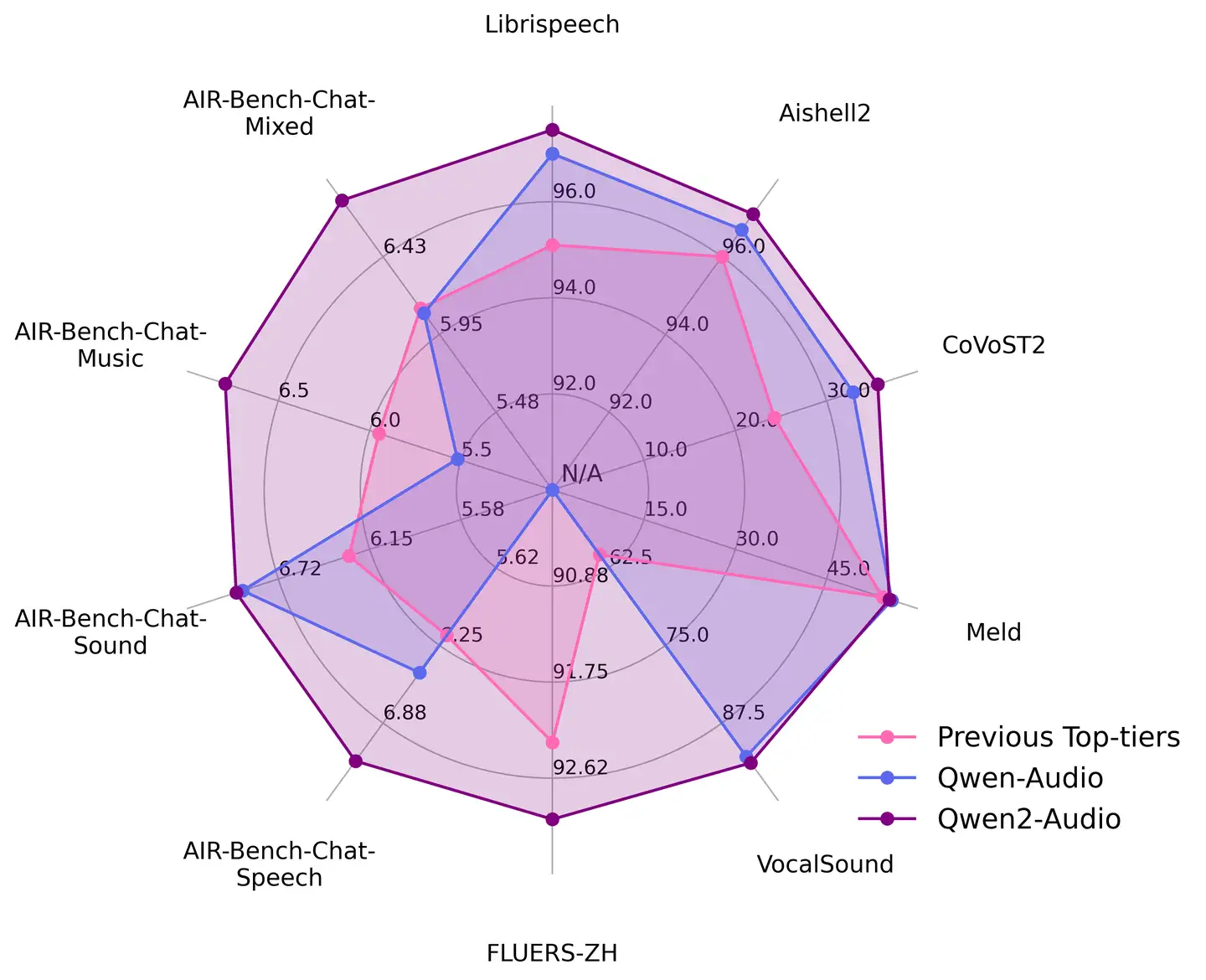
相比一代,性能全面提升
个人评价:我玩过qwen-audio一代,效果非常拉胯,资源消耗大,能力差。但2代效果还可以,长上下文理解比较强,asr文本准确率还可以,但时间戳可能不准(我没有严格对比过),指令跟随还可以。
不得不说,语音这块的开源,阿里真的做了非常多的贡献!
总结:
看到这里的朋友点个赞和关注吧,大家的关注是我长期更新的动力~
我的知乎ID:强化学徒
小红书账号:和AI一起进化
CSDN: hehedadaq-CSDN博客
微信公众号:kaixindelele



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











