









论文: SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
代码: https://github.com/lzccccc/SMOKE
0 引言
现有的单目3D目标检测基本都是2阶段的, 首先基于2D目标检测生成目标的2D候选区域, 然后针对获取到的2D候选区域预测目标的位置姿态等。 论文认为2D检测是不必要的, 甚至会引入不必要的噪声。 如果已知目标的3D属性和相机的内参, 根据几何投影关系是可以得到2D属性的, 反之亦然。论文就是基于这一特点, 直接基于图像平面上的关键点预测,得到3D检测结果。
1 网络介绍
整个网络结构非常简单, 包括一个backbone特征提取网络和检测头, 检测头包括两个并行的分支, 其中一个分支用于关键点坐标回归, 另一个分支用于3D框的回归。
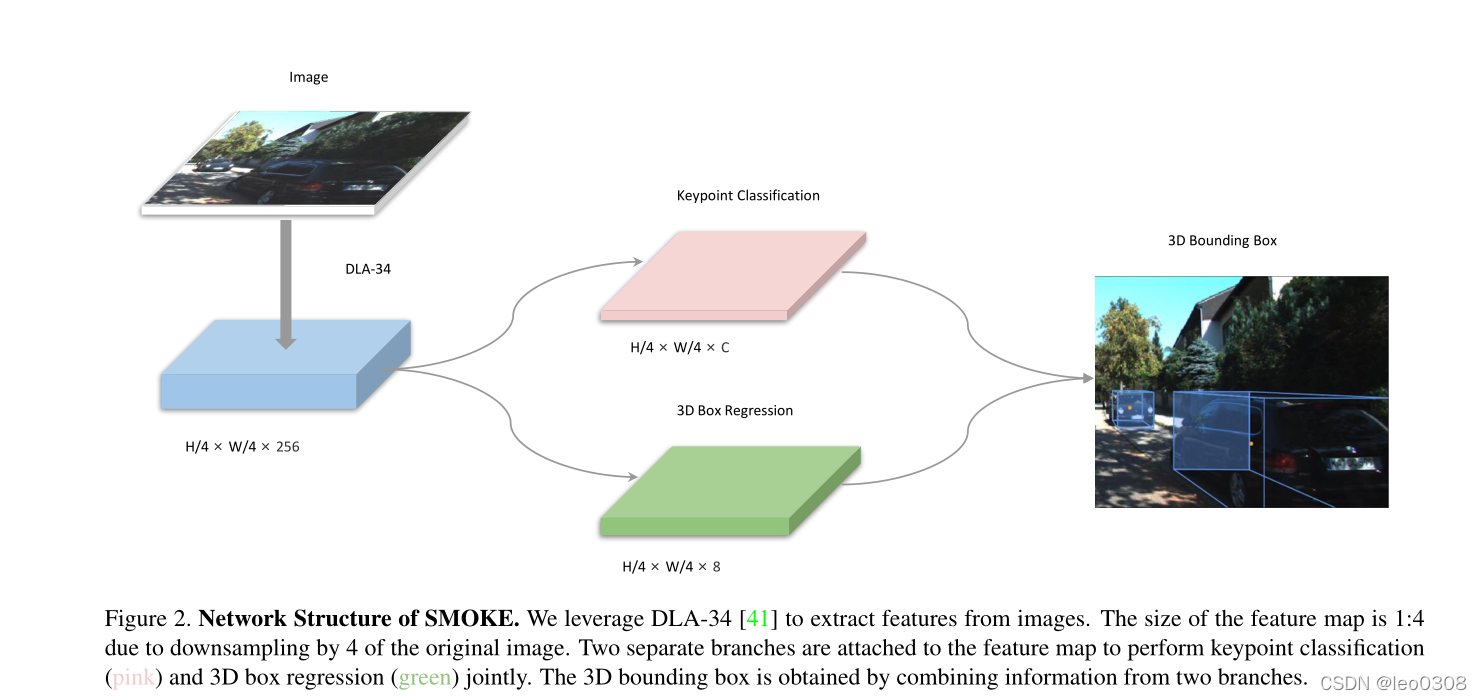
1.1 backbone网络
backbone网路采用了DLA-34的网络, 这个网络的主要特点就是做一些特征的聚合。 用一些基础的特征提取网络加一些特征聚合的操作应该也能取得不错效果。作者对backbone网络做了2点改进: 1)把普通的卷积层换成可变形卷积, 2)用GN替换BN, 因为GN 对batch_size 不敏感。
1.2 检测网络
检测网络主要包括2个并行的分支, 一个预测关键点, 另一个预测一些用于3D框计算的基本变量, 然后把这2个分支的结果进行综合就可以得到3D框的信息。
1.2.1 关键点分支
网络整体框图中叫关键点分类,其实这个叫法不是很准确, 实际应该是回归。 至于类别分类, 这篇文章没有做, 因为只关注了KITTI数据中car这一类。 关键点回归分支预测3D框的中心点在图像平面的投影[ x c x_c xc, y c y_c yc]。
1.2.2 回归分支
回归分支主要预测了计算3D框的一些基础变量, 总共有8个:
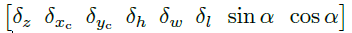
具体细节可以参见论文。 有了这8个变量, 在加上关键点分支预测的中心点坐标, 再结合相机内参和几何投影关系, 就可以重建3D框的信息。
-
计算深度
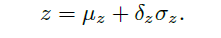
其中 δ z \delta_z δz是通过回归得到的, 是深度偏移量, 再根据预设的参数做一个尺度缩放和平移, 就得到真实的深度值。 文中的预设值是给定好的, 应该是根据统计得出的。 -
计算3D框的中心点
根据预测的中心点[ x c x_c xc, y c y_c yc], 上面计算得到的深度, 以及回归分支预测的偏移量, 以及相机的内参矩阵直接计算得到。
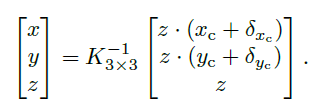
3)计算3D框的3维尺寸
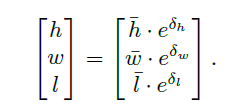
其中
h
ˉ
,
w
ˉ
,
l
ˉ
\bar{h}, \bar{w}, \bar{l}
hˉ,wˉ,lˉ是预设的物体尺寸大小,其他的变量是通过回归分支预测的。
- 计算方向
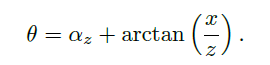
其中 α \alpha α是回归分支预测得到的。 值得注意的是, 作者这里为了预测一个角度值, 预测了2个变量 s i n α , c o s α sin\alpha,cos\alpha sinα,cosα。 但消融试验说明, 预测这样一个向量是有收益的。
至此, 就完全确定了一个3D框的位置, 大小和方向。
2 总结
SMOKE的网络结构非常简单, 在特征图上直接用2个并行的回归分支预测了10个变量, 用这10个变量, 结合相机内参, 根据几何投影关系计算3D框的信息。 几何关系的计算部分比较复杂。
其实有个疑问, 既然这样, 可以更简单粗暴一点, 直接回归3D框的信息, 不用先预测2D平面上的关键点, 在根据相机内参和投影关系投影到3D。 只是这样简单粗暴的回归, 效果可能不会好。
3 参考
[1] 最新发布!SMOKE 单目3D目标检测,代码开源!
[2] 单目3d 检测 smoke 网络
[3] Apollo 7.0障碍物感知模型原型!SMOKE 单目3D目标检测,代码开源!

















 8721
8721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









