









 本文介绍了tiktoken,一个快速的BPE标记器,其性能优于同类开源工具,文章详细讲解了tiktoken的安装步骤和基础用法,包括用于OpenAI模型的编码以及可视化BPE过程的代码示例。
本文介绍了tiktoken,一个快速的BPE标记器,其性能优于同类开源工具,文章详细讲解了tiktoken的安装步骤和基础用法,包括用于OpenAI模型的编码以及可视化BPE过程的代码示例。
Py之tiktoken:tiktoken的简介、安装、使用方法之详细攻略
目录
tiktoken的简介
tiktoken是一个用于OpenAI模型的快速BPE标记器。
1、性能:tiktoken比一个类似的开源分词器快3到6倍
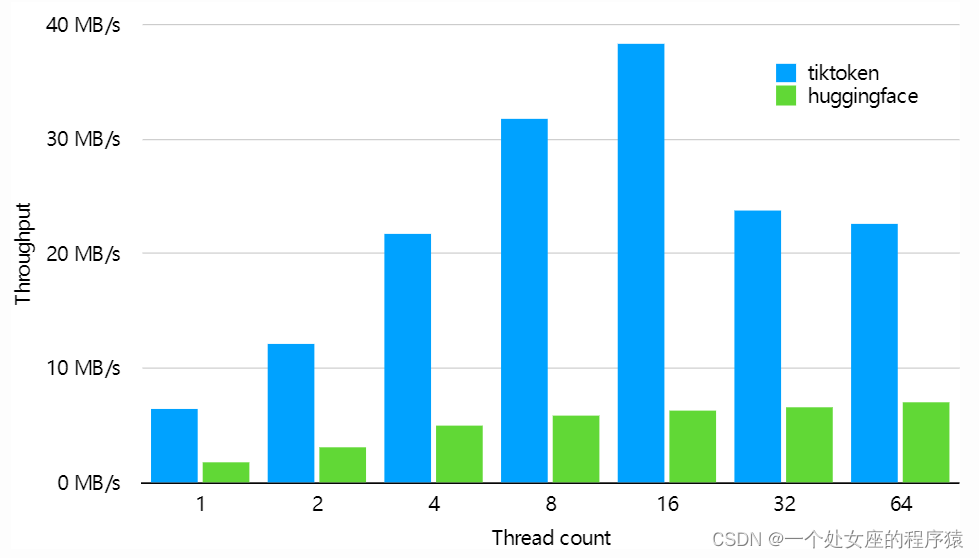
tiktoken的安装
pip install tiktoken
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tiktokenC:\Windows\system32>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tiktoken
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting tiktoken
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/91/cf/7f3b821152f7abb240950133c60c394f7421a5791b020cedb190ff7a61b4/tiktoken-0.5.1-cp39-cp39-win_amd64.whl (760 kB)
|████████████████████████████████| 760 kB 726 kB/s
Requirement already satisfied: regex>=2022.1.18 in d:\programdata\anaconda3\lib\site-packages (from tiktoken) (2022.3.15)
Requirement already satisfied: requests>=2.26.0 in d:\programdata\anaconda3\lib\site-packages (from tiktoken) (2.31.0)
Requirement already satisfied: charset-normalizer<4,>=2 in d:\programdata\anaconda3\lib\site-packages (from requests>=2.26.0->tiktoken) (2.0.12)
Requirement already satisfied: urllib3<3,>=1.21.1 in d:\programdata\anaconda3\lib\site-packages (from requests>=2.26.0->tiktoken) (1.26.9)
Requirement already satisfied: idna<4,>=2.5 in d:\programdata\anaconda3\lib\site-packages (from requests>=2.26.0->tiktoken) (3.3)
Requirement already satisfied: certifi>=2017.4.17 in d:\programdata\anaconda3\lib\site-packages (from requests>=2.26.0->tiktoken) (2021.10.8)
Installing collected packages: tiktoken
Successfully installed tiktoken-0.5.1tiktoken的使用方法
1、基础用法
(1)、用于OpenAI模型的快速BPE标记器
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
assert enc.decode(enc.encode("hello world")) == "hello world"
# To get the tokeniser corresponding to a specific model in the OpenAI API:
enc = tiktoken.encoding_for_model("gpt-4")(2)、帮助可视化BPE过程的代码
from tiktoken._educational import *
# Train a BPE tokeniser on a small amount of text
enc = train_simple_encoding()
# Visualise how the GPT-4 encoder encodes text
enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
enc.encode("hello world aaaaaaaaaaaa")


















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











