







LLMs之DeepSeek-V1之GRPO:《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》翻译与解读
导读:这篇论文介绍了DeepSeekMath 7B,一个在数学推理方面显著优于现有开源模型的语言模型。DeepSeekMath项目通过构建高质量的大规模数学数据集和提出高效的强化学习算法,在开源LLM的数学推理能力方面取得了显著进展,为该领域的研究提供了新的思路和方法。 论文也指出了未来工作的方向,例如改进数据选择流程、探索更有效的强化学习算法和奖励模型等。
>> 背景痛点:
● 现有开源LLM在数学推理上的性能不足: 虽然GPT-4和Gemini-Ultra等闭源模型在数学推理方面取得了显著进展,但它们并不公开,而现有的开源模型性能差距较大。
● 高质量数学数据集的缺乏: 用于训练LLM的公开可用的大规模高质量数学数据集有限,限制了模型的数学推理能力。
● 强化学习算法的效率和有效性有待提高: 现有的强化学习算法在训练LLM进行数学推理时,计算资源消耗较大,且效果有待提升。
>> 具体的解决方案:
● 构建大规模高质量数学数据集DeepSeekMath Corpus: 从Common Crawl中提取了1200亿个与数学相关的token,构建了DeepSeekMath Corpus。该数据集利用fastText分类器进行迭代式构建,并通过人工标注进行质量控制,规模远大于现有公开的数学数据集。
● 基于代码预训练模型进行数学预训练: DeepSeekMath 7B基于DeepSeek-Coder-Base-v1.5 7B进行预训练,而不是从通用的LLM开始,这被证明对提升数学推理能力更有优势。预训练数据包含DeepSeekMath Corpus、AlgebraicStack、arXiv论文、GitHub代码和Common Crawl中的自然语言数据。
● 提出高效的强化学习算法GRPO: 提出了一种名为Group Relative Policy Optimization (GRPO) 的强化学习算法,该算法通过利用组内相对奖励来估计基线,减少了对critic模型的需求,从而显著降低了训练资源消耗。
● 数学指令微调: 使用包含链式思维(CoT)、程序式思维(PoT)和工具集成推理的数据对DeepSeekMath-Base进行微调,得到DeepSeekMath-Instruct 7B。
● 强化学习训练: 使用GRPO算法对DeepSeekMath-Instruct 7B进行强化学习训练,得到DeepSeekMath-RL 7B。
>> 核心思路步骤:
● 数据收集和清洗: 迭代式地从Common Crawl中收集数学相关数据,利用fastText分类器进行筛选,并通过人工标注提高数据质量。
● 数学预训练: 基于DeepSeek-Coder-Base-v1.5 7B,使用DeepSeekMath Corpus等数据进行预训练,得到DeepSeekMath-Base 7B。
● 数学指令微调: 使用CoT、PoT和工具集成推理数据对DeepSeekMath-Base 7B进行微调,得到DeepSeekMath-Instruct 7B。
● 强化学习训练: 使用GRPO算法对DeepSeekMath-Instruct 7B进行强化学习训练,得到DeepSeekMath-RL 7B。
● 评估: 在多个英语和中文数学基准测试上评估模型性能,包括GSM8K、MATH、CMATH、Gaokao-MathCloze等。
>> 优势:
● 优异的数学推理能力: DeepSeekMath-RL 7B在MATH基准测试上取得了51.7%的准确率(不使用外部工具和投票技术),接近Gemini-Ultra和GPT-4的水平。使用自一致性方法,准确率可达60.9%。
● 高效的强化学习算法: GRPO算法显著降低了强化学习训练的资源消耗。
● 大规模高质量数据集: DeepSeekMath Corpus规模大且质量高,为模型训练提供了坚实的基础。
● 多语言支持: DeepSeekMath Corpus包含多种语言的数据,提升了模型在多语言数学推理任务上的表现。
>> 结论和观点:
● Common Crawl数据包含丰富的数学信息: 通过精心设计的数据选择流程,可以从中提取高质量的数学数据。
● 代码预训练有利于数学推理: 在进行数学预训练之前进行代码预训练可以提高模型的数学推理能力。
● arXiv论文在提高数学推理能力方面效果不明显: 这与许多现有研究中普遍使用arXiv数据作为数学预训练数据形成对比。
● GRPO算法是一种高效且有效的强化学习算法: 它可以显著提高模型的数学推理能力,同时降低训练资源消耗。
● 强化学习主要通过提高正确答案在TopK中的排名来提升性能: 而不是提升模型的基本能力。
● 在线采样优于离线采样: 在强化学习训练中,使用实时策略模型进行数据采样比使用初始SFT模型进行数据采样效果更好。
目录
2024年1月5日,LLMs之DeepSeek-V1:《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》翻译与解读
2024年12月26日,LLMs之MoE之DeepSeek-V3:DeepSeek-V3的简介、安装和使用方法、案例应用之详细攻略
2024年12月27日,LLMs之MoE之DeepSeek-V3:《DeepSeek-V3 Technical Report》翻译与解读(DeepSeek-V3的最详细解读)
2025年1月20日,LLMs之DeepSeek-V3:DeepSeek-R1的简介、安装和使用方法、案例应用之详细攻略
《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》翻译与解读
Math Pre-Training at Scale大规模数学预训练
Exploration and Analysis of Reinforcement Learning强化学习的探索与分析
1.2 Summary of Evaluations and Metrics评估与指标总结
English and Chinese Mathematical Reasoning英语和中文数学推理
Natural Language Understanding自然语言理解
2.1 Data Collection and Decontamination数据收集与净化
6 Conclusion, Limitation, and Future Work结论、局限性与未来工作
相关文章
2024年1月5日,LLMs之DeepSeek-V1:《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》翻译与解读
LLMs之DeepSeek-V1:《DeepSeek LLM: Scaling Open-Source Language Models with Longtermism》翻译与解读-CSDN博客
2024年1月11日,LLMs之DeepSeek-V1之MoE:《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》翻译与解
2024年1月25日,LLMs之DeepSeek-V1:《DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence》翻译与解读
2024年2月5日,LLMs之DeepSeek-V1:《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》翻译与解读
2024年5月7日,LLMs之DeepSeek-V2:《DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》翻译与解读
2024年12月26日,LLMs之MoE之DeepSeek-V3:DeepSeek-V3的简介、安装和使用方法、案例应用之详细攻略
LLMs之MoE之DeepSeek-V3:DeepSeek-V3的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
2024年12月27日,LLMs之MoE之DeepSeek-V3:《DeepSeek-V3 Technical Report》翻译与解读(DeepSeek-V3的最详细解读)
2025年1月20日,LLMs之DeepSeek-V3:DeepSeek-R1的简介、安装和使用方法、案例应用之详细攻略
LLMs之DeepSeek-V3:DeepSeek-R1的简介、安装和使用方法、案例应用之详细攻略_怎样使用deepseek r1-CSDN博客
2025年1月22日,LLMs之DeepSeek-R1:《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》翻译与解读
解读论文创新点
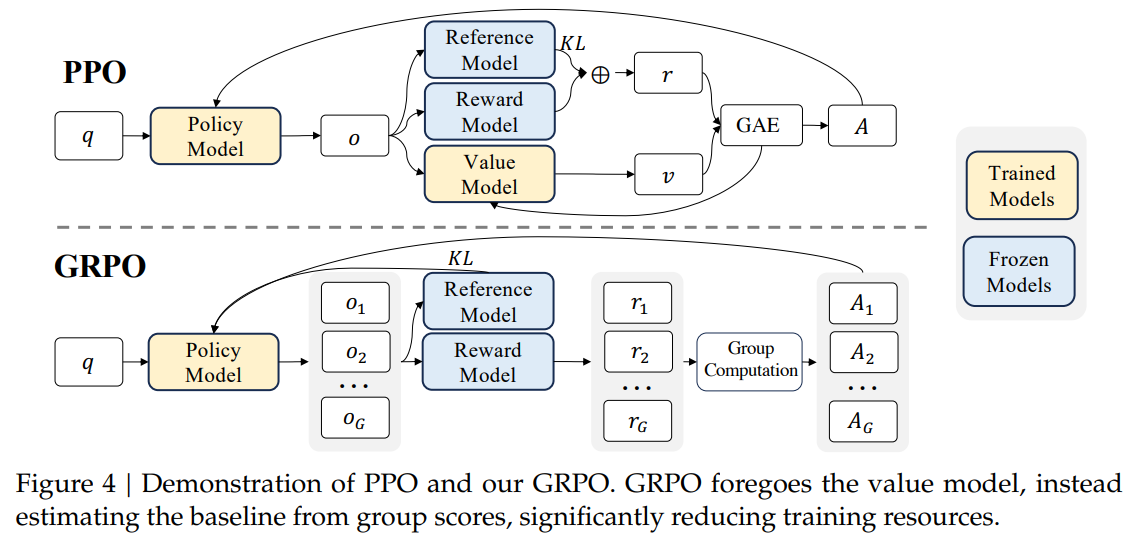
(1)、组相对策略优化(GRPO)
组相对策略优化(GRPO)是一种强化学习算法,旨在提升大型语言模型(LLM)的推理能力。它在 DeepSeekMath 论文中首次提出,用于数学推理领域。GRPO 对传统的近端策略优化(PPO)进行了改进,摒弃了价值函数模型的需求。相反,它从组得分中估计基线,从而减少了内存使用和计算开销。GRPO 现在也被 Qwen 团队采用,可用于规则/二元奖励以及通用奖励模型,以提升模型的有用性。
>> 采样:针对每个提示使用当前策略生成多个输出;
>> 奖励评分:使用奖励函数对每个生成结果进行评分,该函数可以是基于规则的或基于结果的;
>> 优势计算:将生成输出的平均奖励用作基准。然后计算组内每个解决方案相对于此基准的优势。在组内对奖励进行标准化;
>> 策略优化:策略试图最大化 GRPO 目标,该目标包括计算出的优势和一个 KL 散度项。这与 PPO 在奖励中实现 KL 项的方式不同。

Figure 4 | Demonstration of PPO and our GRPO. GRPO foregoes the value model, instead estimating the baseline from group scores, significantly reducing training resources.图 4 | PPO 和我们的 GRPO 的演示。GRPO 放弃了价值模型,转而从组得分中估计基线,从而显著减少了训练资源。
案例理解GRPO:组生成→计算奖励→计算优势→更新策略
| 数学问题求解 | 任务描述:要求LLM求解方程 2x + 5 = 15,评估标准: >> 正确性(最终答案正确性,二元奖励) >> 过程合理性(解题步骤的逻辑性,0-1连续奖励) |
| GRPO实现流程 | (1)、组生成:对同一问题生成4个解答 解答1: x=(15-5)/2=5 ✓ 解答2: 移项得2x=10 → x=5 ✓ 解答3: 直接回答x=10 ✗ 解答4: 分步错误导致x=3 ✗ |
| (2)、计算奖励 解答1: 1.0(正确+合理步骤) 解答2: 1.0(正确+合理步骤) 解答3: 0.0(错误答案) 解答4: 0.2(错误但部分步骤合理) → 组平均奖励 = (1+1+0+0.2)/4 = 0.55 | |
| (3)、计算优势 解答1优势值 = 1.0 - 0.55 = 0.45 解答2优势值 = 1.0 - 0.55 = 0.45 解答4优势值 = 0.2 - 0.55 = -0.35 | |
| (4)、更新策略 最大化高优势样本的概率 最小化低优势样本的概率 同时控制KL散度不超过阈值 |
对比:GRPO 、PPO
| 维度 | GRPO | PPO |
|---|---|---|
| 价值函数 | 无需独立价值模型 | 需训练独立价值网络 |
| 优势计算 | 组内相对奖励差异 GRPO通过组内横向比较获得相对优势 | 基于价值网络的TD误差或GAE PPO依赖时序差分和值函数估计绝对优势 |
| KL约束 | 直接作为目标函数项 | 通过奖励函数惩罚项间接实现 |
| 内存占用 | 较低(无价值网络参数) | 较高(需存储价值网络) |
| 适用场景 | 离散生成任务(数学/代码推理) | 连续决策任务(游戏/机器人控制) |
| 奖励类型 | 兼容规则/二元/模型奖励 | 依赖密集标量奖励信号 |
| 实现复杂度 | 较低(仅策略网络) | 较高(需调优策略+价值网络) |
《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》翻译与解读
| 地址 | 论文地址:[2402.03300] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models |
| 时间 | 2024年2月5日 最新版本2024年4月27日 |
| 作者 | DeepSeek-AI, Tsinghua University, Peking University |
Abstract
| Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO. | 数学推理对语言模型来说是一个重大挑战,因其复杂且结构化的特点。在本文中,我们推出了 DeepSeekMath 7B,它在 DeepSeek-Coder-Base-v1.5 7B 的基础上,继续使用来自 Common Crawl 的 1200 亿个与数学相关的标记进行预训练,同时还结合了自然语言和代码数据。DeepSeekMath 7B 在不依赖外部工具包和投票技术的情况下,在竞赛级别的 MATH 基准测试中取得了 51.7% 的出色成绩,接近 Gemini-Ultra 和 GPT-4 的性能水平。DeepSeekMath 7B 在 MATH 上对 64 个样本进行自一致性测试,得分达到了 60.9%。DeepSeekMath 的数学推理能力归因于两个关键因素:首先,我们通过精心设计的数据选择管道,充分利用了公开可用的网络数据的巨大潜力。其次,我们引入了组相对策略优化(GRPO),这是近端策略优化(PPO)的一个变体,它在增强数学推理能力的同时,还优化了 PPO 的内存使用。 |
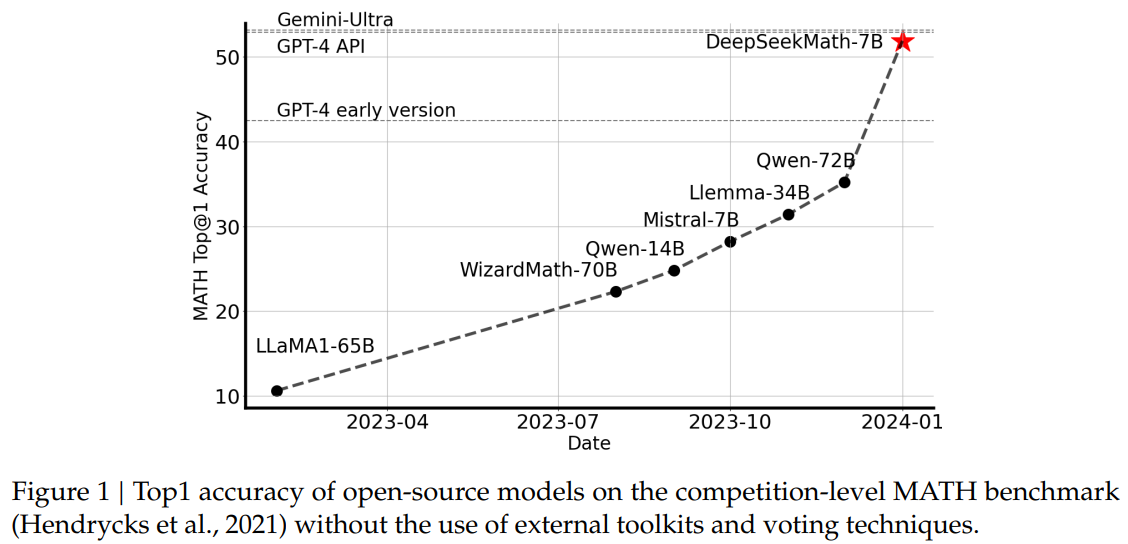
Figure 1: Top1 accuracy of open-source models on the competition-level MATH benchmark (Hendrycks et al., 2021) without the use of external toolkits and voting techniques.图 1:开源模型在竞赛级 MATH 基准测试(Hendrycks 等人,2021 年)中的 Top1 准确率,未使用外部工具包和投票技术。
1、Introduction
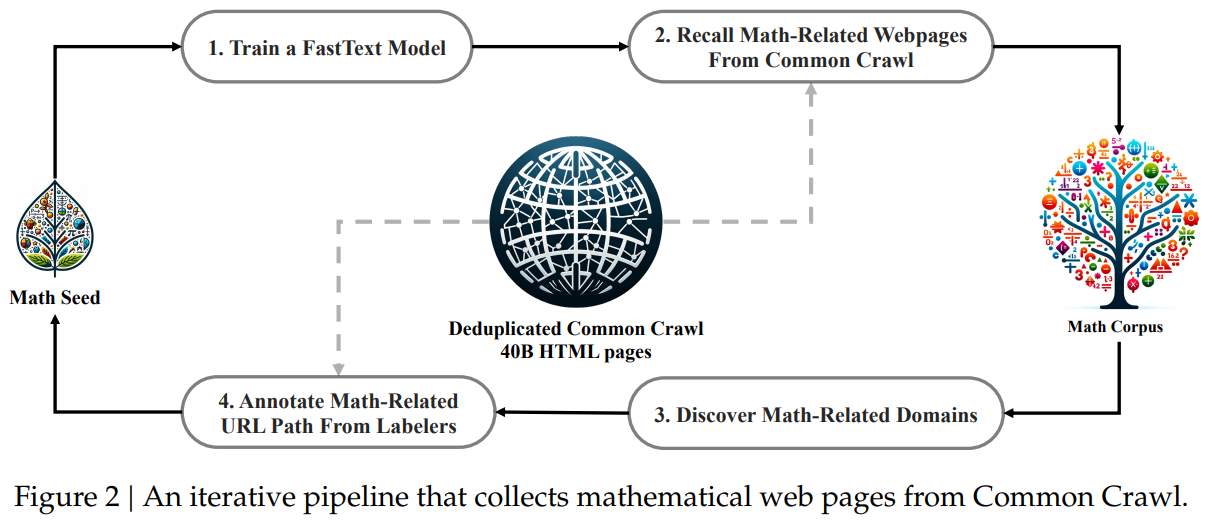
| Large language models (LLM) have revolutionized the approach to mathematical reasoning in artificial intelligence, spurring significant advancements in both the quantitative reasoning benchmark (Hendrycks et al., 2021) and the geometry reasoning benchmark (Trinh et al., 2024). Moreover, these models have proven instrumental in assisting humans in solving complex mathematical problems (Tao, 2023). However, cutting-edge models such as GPT-4 (OpenAI, 2023) and Gemini-Ultra (Anil et al., 2023) are not publicly available, and the currently accessible open-source models considerably trail behind in performance. In this study, we introduce DeepSeekMath, a domain-specific language model that significantly outperforms the mathematical capabilities of open-source models and approaches the performance level of GPT-4 on academic benchmarks. To achieve this, we create the DeepSeekMath Corpus, a large-scale high-quality pre-training corpus comprising 120B math tokens. This dataset is extracted from the Common Crawl (CC) using a fastText-based classifier (Joulin et al., 2016). In the initial iteration, the classifier is trained using instances from OpenWebMath (Paster et al., 2023) as positive examples, while incorporating a diverse selection of other web pages to serve as negative examples. Subsequently, we employ the classifier to mine additional positive instances from the CC, which are further refined through human annotation. The classifier is then updated with this enhanced dataset to improve its performance. The evaluation results indicate that the large-scale corpus is of high quality, as our base model DeepSeekMath-Base 7B achieves 64.2% on GSM8K (Cobbe et al., 2021) and 36.2% on the competition-level MATH dataset (Hendrycks et al., 2021), outperforming Minerva 540B (Lewkowycz et al., 2022a). In addition, the DeepSeekMath Corpus is multilingual, so we notice an improvement in Chinese mathematical benchmarks (Wei et al., 2023; Zhong et al., 2023). We believe that our experience in mathematical data processing is a starting point for the research community, and there is significant room for improvement in the future. | 大型语言模型(LLM)彻底改变了人工智能中数学推理的方法,推动了定量推理基准(Hendrycks 等人,2021 年)和几何推理基准(Trinh 等人,2024 年)的显著进步。此外,这些模型在帮助人类解决复杂数学问题方面也发挥了重要作用(Tao,2023 年)。然而,像 GPT-4(OpenAI,2023 年)和 Gemini-Ultra(Anil 等人,2023 年)这样的前沿模型尚未公开,而目前可获取的开源模型在性能上明显落后。 在本研究中,我们推出了 DeepSeekMath,这是一个专门针对数学领域的语言模型,其数学能力显著优于开源模型,并在学术基准测试中接近 GPT-4 的性能水平。为了实现这一目标,我们创建了 DeepSeekMath 数据集,这是一个包含 1200 亿个数学标记的大规模高质量预训练语料库。该数据集是从 Common Crawl(CC)中使用基于 fastText 的分类器(Joulin 等人,2016 年)提取的。在初始迭代中,分类器使用来自 OpenWebMath(Paster 等人,2023 年)的实例作为正例进行训练,同时纳入了大量其他网页作为负例。随后,我们利用该分类器从 CC 中挖掘更多的正例,并通过人工标注进一步优化这些实例。然后,我们用这个增强的数据集更新分类器以提升其性能。评估结果表明,大规模语料库质量很高,我们的基础模型 DeepSeekMath-Base 7B 在 GSM8K(Cobbe 等人,2021 年)上达到了 64.2%,在竞赛级别的 MATH 数据集(Hendrycks 等人,2021 年)上达到了 36.2%,超过了 Minerva 540B(Lewkowycz 等人,2022a)。此外,DeepSeekMath 语料库是多语言的,因此我们在中文数学基准测试(Wei 等人,2023 年;Zhong 等人,2023 年)中也观察到了性能的提升。我们认为我们在数学数据处理方面的经验是研究社区的一个起点,未来还有很大的改进空间。 |
| DeepSeekMath-Base is initialized with DeepSeek-Coder-Base-v1.5 7B (Guo et al., 2024), as we notice that starting from a code training model is a better choice compared to a general LLM. Furthermore, we observe the math training also improves model capability on MMLU (Hendrycks et al., 2020) and BBH benchmarks (Suzgun et al., 2022), indicating it does not only enhance the model’s mathematical abilities but also amplifies general reasoning capabilities. After pre-training, we apply mathematical instruction tuning to DeepSeekMath-Base with chain-of-thought (Wei et al., 2022), program-of-thought (Chen et al., 2022; Gao et al., 2023), and tool-integrated reasoning (Gou et al., 2023) data. The resulting model DeepSeekMath-Instruct 7B beats all 7B counterparts and is comparable with 70B open-source instruction-tuned models. Furthermore, we introduce the Group Relative Policy Optimization (GRPO), a variant reinforcement learning (RL) algorithm of Proximal Policy Optimization (PPO) (Schulman et al., 2017). GRPO foregoes the critic model, instead estimating the baseline from group scores, significantly reducing training resources. By solely using a subset of English instruction tuning data, GRPO obtains a substantial improvement over the strong DeepSeekMath-Instruct, including both in-domain (GSM8K: 82.9% → 88.2%, MATH: 46.8% → 51.7%) and out-of-domain mathematical tasks (e.g., CMATH: 84.6% → 88.8%) during the reinforcement learning phase. We also provide a unified paradigm to understand different methods, such as Rejection Sampling Fine-Tuning (RFT) (Yuan et al., 2023a), Direct Preference Optimization (DPO) (Rafailov et al., 2023), PPO and GRPO. Based on such a unified paradigm, we find that all these methods are conceptualized as either direct or simplified RL techniques. We also conduct extensive experiments, e.g., online v.s. offline training, outcome v.s. process supervision, single-turn v.s. iterative RL and so on, to deeply investigate the essential elements of this paradigm. At last, we explain why our RL boosts the performance of instruction-tuned models, and further summarize potential directions to achieve more effective RL based on this unified paradigm. | DeepSeekMath-Base 是基于 DeepSeek-Coder-Base-v1.5 7B(Guo 等人,2024 年)初始化的,因为我们注意到从代码训练模型开始是一个比从通用语言模型开始更好的选择。此外,我们观察到数学训练不仅增强了模型的数学能力,还在 MMLU(Hendrycks 等人,2020 年)和 BBH 基准测试(Suzgun 等人,2022 年)上提升了模型的能力,表明它还增强了模型的一般推理能力。 在预训练之后,我们使用链式思维(Wei 等人,2022 年)、程序思维(Chen 等人,2022 年;Gao 等人,2023 年)和工具集成推理(Gou 等人,2023 年)的数据对 DeepSeekMath-Base 进行数学指令微调。由此产生的模型 DeepSeekMath-Instruct 7B 超过了所有 7B 对手,并且与 70B 开源指令微调模型相当。 此外,我们引入了组相对策略优化(GRPO),这是近端策略优化(PPO)(Schulman 等人,2017 年)的一种变体强化学习(RL)算法。GRPO 放弃了评估器模型,而是从组分数中估计基线,从而显著减少了训练资源。仅通过使用英语指令微调数据的一个子集,GRPO 在强化学习阶段就大幅超越了强大的 DeepSeekMath-Instruct,包括在领域内(GSM8K:82.9% → 88.2%,MATH:46.8% → 51.7%)和领域外的数学任务(例如,CMATH:84.6% → 88.8%)中均取得了显著进步。我们还提供了一个统一的范式来理解不同的方法,例如拒绝采样微调(RFT)(Yuan 等人,2023a)、直接偏好优化(DPO)(Rafailov 等人,2023)、PPO 和 GRPO。基于这样一个统一的范式,我们发现所有这些方法都可以被概念化为直接或简化的强化学习技术。我们还进行了广泛的实验,例如在线与离线训练、结果与过程监督、单轮与迭代强化学习等等,以深入探究该范式的本质要素。最后,我们解释了为什么我们的强化学习能够提升指令微调模型的性能,并进一步总结了基于此统一范式实现更有效强化学习的潜在方向。 |
1.1 Contributions贡献
| Our contribution includes scalable math pre-training, along with the exploration and analysis of reinforcement learning. | 我们的贡献包括可扩展的数学预训练,以及对强化学习的探索和分析。 |
Math Pre-Training at Scale大规模数学预训练
| >> Our research provides compelling evidence that the publicly accessible Common Crawl data contains valuable information for mathematical purposes. By implementing a meticulously designed data selection pipeline, we successfully construct the DeepSeekMath Corpus, a high-quality dataset of 120B tokens from web pages filtered for mathematical content, which is almost 7 times the size of the math web pages used by Minerva (Lewkowycz et al., 2022a) and 9 times the size of the recently released OpenWebMath (Paster et al., 2023). >> Our pre-trained base model DeepSeekMath-Base 7B achieves comparable performance with Minerva 540B (Lewkowycz et al., 2022a), indicating the nu mber of parameters is not the only key factor in mathematical reasoning capability. A smaller model pre-trained on high-quality data could achieve strong performance as well. >> We share our findings from math training experiments. Code training prior to math training improves models’ ability to solve mathematical problems both with and without tool use. This offers a partial answer to the long-standing question: does code training improve reasoning abilities? We believe it does, at least for mathematical reasoning. >> Although training on arXiv papers is common, especially in many math-related papers, it brings no notable improvements on all mathematical benchmarks adopted in this paper. | >> 我们的研究提供了令人信服的证据,表明公开可获取的 Common Crawl 数据包含对数学研究有价值的大量信息。通过精心设计的数据筛选流程,我们成功构建了 DeepSeekMath 语料库,这是一个从网页中筛选出数学内容的高质量数据集,包含 1200 亿个标记,几乎是 Minerva(Lewkowycz 等人,2022a)所使用的数学网页数据量的 7 倍,是最近发布的 OpenWebMath(Paster 等人,2023)的 9 倍。 >> 我们的预训练基础模型 DeepSeekMath-Base 7B 在数学推理能力方面与 Minerva 540B(Lewkowycz 等人,2022a)表现相当,这表明参数数量并非数学推理能力的唯一关键因素。在高质量数据上预训练的小型模型也能取得出色的表现。 >> 我们分享了数学训练实验中的发现。在数学训练之前进行代码训练能够提升模型解决数学问题的能力,无论是否使用工具。这为长期存在的问题提供了一个部分答案:代码训练是否能提升推理能力?尽管在 arXiv 论文上进行训练很常见,尤其是在许多与数学相关的论文中,但在本文采用的所有数学基准测试中,这种训练方式并未带来显著的改进。 |
Exploration and Analysis of Reinforcement Learning强化学习的探索与分析
| >> We introduce Group Relative Policy Optimization (GRPO), an efficient and effective reinforcement learning algorithm. GRPO foregoes the critic model, instead estimating the baseline from group scores, significantly reducing training resources compared to Proximal Policy Optimization (PPO). >> We demonstrate that GRPO significantly enhances the performance of our instruction-tuned model DeepSeekMath-Instruct, by solely using the instruction-tuning data. Furthermore, we observe enhancements in the out-of-domain performance during the reinforcement learning process. >> We provide a unified paradigm to understand different methods, such as RFT, DPO, PPO, and GRPO. We also conduct extensive experiments, e.g., online v.s. offline training, outcome v.s. process supervision, single-turn v.s. iterative reinforcement learning, and so on to deeply investigate the essential elements of this paradigm. >> Based on our unified paradigm, we explore the reasons behind the effectiveness of reinforcement learning, and summarize several potential directions to achieve more effective reinforcement learning of LLMs. | >> 我们引入了组相对策略优化(GRPO),这是一种高效且有效的强化学习算法。GRPO 放弃了评估器模型,转而从组得分中估计基线,与近端策略优化(PPO)相比,显著减少了训练资源。 >> 我们证明,仅使用指令调优数据,GRPO 就能显著提升我们的指令调优模型 DeepSeekMath-Instruct 的性能。此外,在强化学习过程中,我们还观察到其在域外性能上的提升。 >> 我们提供了一个统一的范式来理解不同的方法,例如 RFT、DPO、PPO 和 GRPO。我们还进行了广泛的实验,例如在线与离线训练、结果与过程监督、单轮与迭代强化学习等等,以深入探究该范式的关键要素。 >> 基于我们的统一范式,我们探究了强化学习有效性的背后原因,并总结了几个实现更有效的大语言模型强化学习的潜在方向。 |
1.2 Summary of Evaluations and Metrics评估与指标总结
English and Chinese Mathematical Reasoning英语和中文数学推理
| English and Chinese Mathematical Reasoning: We conduct comprehensive assessments of our models on English and Chinese benchmarks, covering mathematical problems from grade-school level to college level. English benchmarks include GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021), SAT (Azerbayev et al., 2023), OCW Courses (Lewkowycz et al., 2022a), MMLU-STEM (Hendrycks et al., 2020). Chinese benchmarks include MGSM-zh (Shi et al., 2023), CMATH (Wei et al., 2023), Gaokao-MathCloze (Zhong et al., 2023), and Gaokao-MathQA (Zhong et al., 2023). We evaluate models’ ability to generate self-contained text solutions without tool use, and also the ability to solve problems using Python. On English benchmarks, DeepSeekMath-Base is competitive with the closed-source Minerva 540B (Lewkowycz et al., 2022a), and surpasses all open-source base models (e.g., Mistral 7B (Jiang et al., 2023) and Llemma-34B (Azerbayev et al., 2023)), regardless of whether they’ve undergone math pre-training or not, often by a significant margin. Notably, DeepSeekMath-Base is superior on Chinese benchmarks, likely because we don’t follow previous works (Lewkowycz et al., 2022a; Azerbayev et al., 2023) to collect English-only math pre-training data, and also include high-quality non-English ones. With mathematical instruction tuning and reinforcement learning, the resulting DeepSeekMath-Instruct and DeepSeekMath-RL demonstrate strong performance, obtaining an accuracy of over 50% on the competition-level MATH dataset for the first time within the open-source community. | 英语和中文数学推理:我们在英语和中文基准测试上对我们的模型进行了全面评估,涵盖了从小学到大学水平的数学问题。英语基准测试包括 GSM8K(Cobbe 等人,2021 年)、MATH(Hendrycks 等人,2021 年)、SAT(Azerbayev 等人,2023 年)、OCW 课程(Lewkowycz 等人,2022a)、MMLU-STEM(Hendrycks 等人,2020 年)。中文基准测试包括 MGSM-zh(Shi 等人,2023 年)、CMATH(Wei 等人,2023 年)、高考数学完形填空(Zhong 等人,2023 年)和高考数学问答(Zhong 等人,2023 年)。我们评估模型生成完整文本解答的能力(不使用工具),以及使用 Python 解决问题的能力。 在英语基准测试中,DeepSeekMath-Base 与闭源的 Minerva 540B(Lewkowycz 等人,2022a)相当,并且超越了所有开源基础模型(例如 Mistral 7B(Jiang 等人,2023 年)和 Llemma-34B(Azerbayev 等人,2023 年)),无论它们是否经过数学预训练,通常差距显著。值得注意的是,DeepSeekMath-Base 在中文基准测试中表现更优,这可能是因为我们没有像之前的研究(Lewkowycz 等人,2022a;Azerbayev 等人,2023)那样仅收集英文数学预训练数据,而是也纳入了高质量的非英文数据。通过数学指令调优和强化学习,由此产生的 DeepSeekMath-Instruct 和 DeepSeekMath-RL 表现出色,在开源社区中首次在竞赛级别的 MATH 数据集上实现了超过 50% 的准确率。 |
Formal Mathematics形式化数学
| Formal Mathematics: We evaluate DeepSeekMath-Base using the informal-to-formal theorem proving task from (Jiang et al., 2022) on miniF2F (Zheng et al., 2021) with Isabelle (Wenzel et al., 2008) chosen to be the proof assistant. DeepSeekMath-Base demonstrates strong few-shot autoformalization performance. | 形式化数学:我们使用(Jiang 等人,2022 年)提出的非形式化到形式化定理证明任务,在 miniF2F(Zheng 等人,2021 年)上对 DeepSeekMath-Base 进行评估,选择 Isabelle(Wenzel 等人,2008 年)作为证明助手。DeepSeekMath-Base 展示了强大的少样本自动形式化性能。 |
Natural Language Understanding自然语言理解
| Natural Language Understanding, Reasoning, and Code: To build a comprehensive profile of models’ general understanding, reasoning, and coding capabilities, we evaluate DeepSeekMath-Base on the Massive Multitask Language Understanding (MMLU) benchmark (Hendrycks et al., 2020) which encompasses 57 multiple-choice tasks covering diverse subjects, BIG-Bench Hard (BBH) (Suzgun et al., 2022) which consists of 23 challenging tasks that mostly require multi-step reasoning to solve, as well as HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021) which are widely used to evaluate code language models. Math pre-training benefits both language understanding and reasoning performance. | 为了全面评估模型的一般理解、推理和编码能力,我们在涵盖 57 个涵盖不同主题的多项选择题的大型多任务语言理解(MMLU)基准测试(Hendrycks 等人,2020 年)、由 23 个大多需要多步推理才能解决的具有挑战性的任务组成的 BIG-Bench Hard(BBH)(Suzgun 等人,2022 年)以及广泛用于评估代码语言模型的 HumanEval(Chen 等人,2021 年)和 MBPP(Austin 等人,2021 年)上对 DeepSeekMath-Base 进行了评估。数学预训练对语言理解和推理性能都有益处。 |
2 Math Pre-Training数学预训练
2.1 Data Collection and Decontamination数据收集与净化
Figure 2:An iterative pipeline that collects mathematical web pages from Common Crawl.图 2:从 Common Crawl 收集数学网页的迭代流程。
6 Conclusion, Limitation, and Future Work结论、局限性与未来工作
| We present DeepSeekMath, which outperforms all open-source models on the competition-level MATH benchmark and approaches the performance of closed models. DeepSeekMath is initialized with DeepSeek-Coder-v1.5 7B and undergoes continual training for 500B tokens, with a significant component of the training data being 120B math tokens sourced from Common Crawl. Our extensive ablation study shows web pages offer significant potential for high-quality mathematical data, while arXiv may not as beneficial as we expected. We introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), which can notably improve mathematical reasoning capabilities with less memory consumption. The experiment results show that GRPO is effective even if DeepSeekMath-Instruct 7B has reached a high score on benchmarks. We also provide a unified paradigm to understand a series of methods and summarize several potential directions for more effective reinforcement learning. | 我们提出了 DeepSeekMath,它在竞赛级别的 MATH 基准测试中超越了所有开源模型,并接近封闭模型的性能。DeepSeekMath 以 DeepSeek-Coder-v1.5 7B 为初始模型,并经过 5000 亿个标记的持续训练,其中大量训练数据来自 Common Crawl 的 1200 亿个数学标记。我们进行了广泛的消融研究,结果表明网页为高质量数学数据提供了巨大潜力,而 arXiv 可能不像我们预期的那样有益。我们引入了组相对策略优化(GRPO),这是近端策略优化(PPO)的一个变体,它可以在减少内存消耗的情况下显著提高数学推理能力。实验结果表明,即使 DeepSeekMath-Instruct 7B 在基准测试中已取得高分,GRPO 仍然有效。我们还提供了一个统一的范式来理解一系列方法,并总结了几个更有效的强化学习的潜在方向。 |
| Although DeepSeekMath achieves impressive scores on quantitative reasoning benchmarks, its capability on geometry and theorem-proof are relatively weaker than closed models. For instance, in our dry run, the model cannot handle problems related to triangles and ellipses, which may indicate data selection bias in pre-training and fine-tuning. In addition, restricted by the model scale, DeepSeekMath is worse than GPT-4 on few-shot capability. GPT-4 could improve its performance with few-shot inputs, while DeepSeekMath shows similar performance in zero-shot and few-shot evaluation. In the future, we will further improve our engineered data selection pipeline to construct more high-quality pre-trained corpus. In addition, we will explore the potential directions (Section 5.2.3) for more effective reinforcement learning of LLMs. | 尽管 DeepSeekMath 在定量推理基准测试中取得了令人瞩目的分数,但在几何和定理证明方面的能力相对弱于封闭模型。例如,在我们的试运行中,该模型无法处理与三角形和椭圆相关的问题,这可能表明在预训练和微调过程中存在数据选择偏差。此外,由于模型规模的限制,DeepSeekMath 在少样本能力方面不如 GPT-4。GPT-4 可以通过少量样本输入来提高其性能,而 DeepSeekMath 在零样本和少样本评估中的表现相似。未来,我们将进一步改进我们的工程数据选择流程,以构建更多高质量的预训练语料库。此外,我们将探索更有效的大型语言模型强化学习的潜在方向(第 5.2.3 节)。 |



















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











