







LLMs之Grok-1.5:Grok-1.5的简介、安装和使用方法、案例应用之详细攻略
导读:xAI公司在不久前发布了Grok-1模型以及模型结构,揭示了公司到去年11月为止在大语言模型研发上的进步。2024年3月28日(美国时间),xAI以“迅雷不及掩耳之势”正式发布Grok-1.5。具体特点如下所示
>> Grok-1.5在算术和编程相关任务中的表现有很大提升,在MATH和GSM8K等数学测评中的得分均有提高。
>> 支持的上下文长度扩大到128K的token,内存容量较之前扩大16倍,可以处理更长更复杂的任务输入。
>> 在需要在长文本中快速提取信息的NIAH测评中,Grok-1.5效果显著。
>> 采用基于JAX、Rust和Kubernetes的分布式训练框架,提高训练稳定性和高效性。
>> Grok-1.5将在近期内面向早期测试人员和现有Grok用户在App Store平台推广应用。
总体来说,Grok-1.5相比Grok-1在算术逻辑和广义语言理解能力等方面有了明显提升,并支持了更长的输入上下文。它采用了优化后的训练系统,提高了模型训练的稳定性和效率。这对提升语言模型应用水平具有重要意义。
目录
LLMs之Grok:Grok(一款具有00后特点般幽默、机智和实时的大语言模型)的简介、使用方法、案例应用之详细攻略
LLMs之Grok-1:Grok-1的简介、安装、使用方法之详细攻略
LLMs之Grok-1.5:Grok-1.5的简介、安装和使用方法、案例应用之详细攻略
相关文章
LLMs之Grok:Grok(一款具有00后特点般幽默、机智和实时的大语言模型)的简介、使用方法、案例应用之详细攻略
LLMs之Grok:Grok(一款具有00后特点般幽默、机智和实时的大语言模型)的简介、使用方法、案例应用之详细攻略_grok-1怎么使用-CSDN博客
LLMs之Grok-1:Grok-1的简介、安装、使用方法之详细攻略
LLMs之Grok-1:Grok-1的简介、安装、使用方法之详细攻略_grok1 模型训练方法-CSDN博客
LLMs之Grok-1.5:Grok-1.5的简介、安装和使用方法、案例应用之详细攻略
LLMs之Grok-1.5:Grok-1.5的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
Grok-1.5的简介
2024年3月28日(美国时间),xAI以“迅雷不及掩耳之势”正式发布Grok-1.5。Grok-1.5具备改进的推理能力和128K令牌的上下文长度。即将在X平台上推出。
Grok-1.5,是xAI最新的模型,能够理解长篇上下文和进行高级推理。Grok-1.5将在未来几天内提供给早期测试者和现有的Grok用户在X平台上使用。
两周前,xAI发布了Grok-1的模型权重和网络架构,向大家展示了直到去年11月xAI的进展。自那时以来,我们在最新的模型Grok-1.5中改进了推理和问题解决能力。
官网地址:Announcing Grok-1.5
1、能力和推理:MATH、GSM8K、HumanEval
在Grok-1.5中最显著的改进之一是其在编码和与数学相关的任务中的表现。在我们的测试中,Grok-1.5在MATH基准测试中获得了50.6%的分数,在GSM8K基准测试中获得了90%的分数,这两个数学基准测试涵盖了从小学到高中竞赛题的广泛范围。此外,它在HumanEval基准测试中获得了74.1%的分数,该测试评估了代码生成和问题解决能力。
2、长篇上下文理解
Grok-1.5的一个新特性是其能够在其上下文窗口内处理长达128K令牌的上下文。这使得Grok的记忆容量增加了16倍,使其能够利用来自长度大大超过以往的文档的信息。
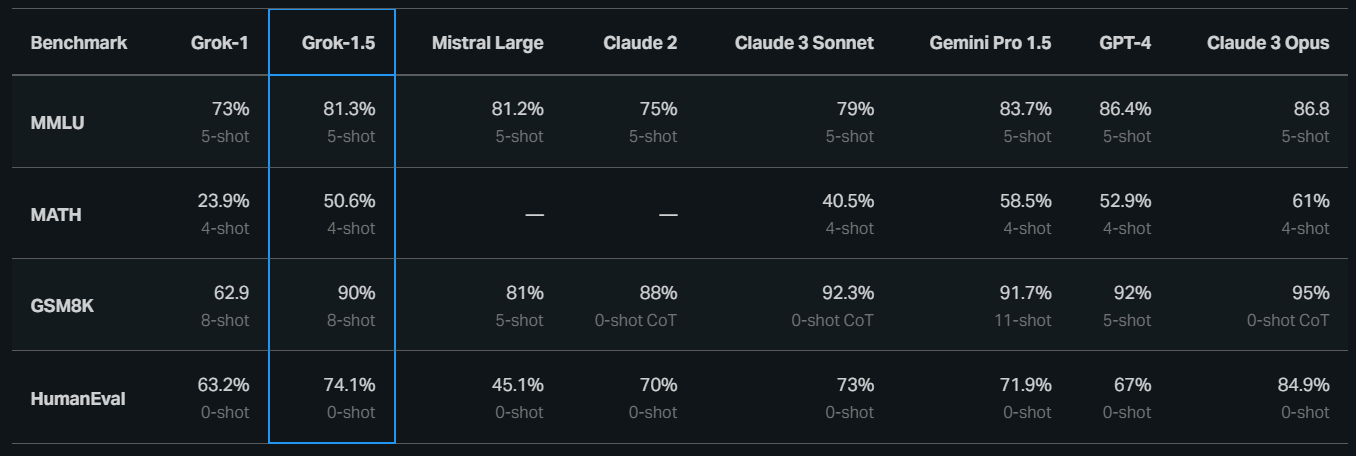
请注意,GPT-4的分数是从2023年3月的发布中获取的。对于MATH和GSM8K,我们呈现maj@1结果。对于HumanEval,我们报告pass@1基准分数。
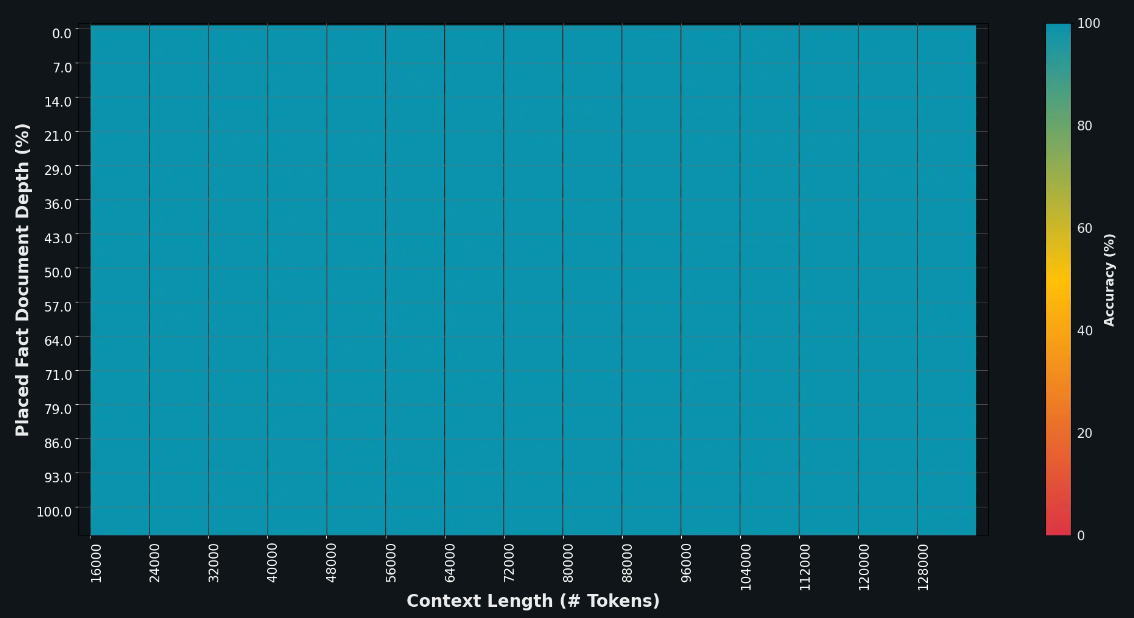
该图显示了一个图表,可视化了模型从其上下文窗口中检索信息的能力。x轴是上下文窗口的长度,y轴是要从窗口中检索的事实的相对位置。我们使用颜色标记回忆率。整个图表都是绿色的,这意味着对于每个上下文窗口和要检索的事实的每个位置,回忆率都是100%。
此外,即使上下文窗口扩展,该模型也可以处理更长、更复杂的提示,同时保持其指示遵循能力。在“Haystack ”(NIAH)评估中,Grok-1.5展示了针对长达128K令牌的上下文中嵌入文本的强大检索能力,实现了完美的检索结果。
3、Grok-1.5基础设施
在大规模GPU集群上运行的尖端大型语言模型(LLMs)研究需要强大而灵活的基础设施。Grok-1.5建立在基于JAX、Rust和Kubernetes的自定义分布式训练框架上。该训练堆栈使我们的团队能够以最小的努力规划新的想法并在规模上训练新的架构。在大型计算集群上训练LLMs的一个主要挑战是最大程度地提高训练作业的可靠性和正常运行时间。我们的自定义训练协调器确保问题节点会自动被检测并从训练作业中排除。我们还优化了检查点、数据加载和训练作业重启,以最大程度地减少故障发生时的停机时间。如果你对我们的训练堆栈感兴趣,请申请加入我们的团队。
4、展望未来
Grok-1.5将很快提供给早期测试者,我们期待收到您的反馈,以帮助我们改进Grok。随着我们逐渐向更广泛的受众推出Grok-1.5,我们很高兴地宣布未来几天将推出几个新功能。
Grok-1.5的安装和使用方法
1、安装
等待官方开源中……
Grok-1.5的案例应用
持续更新中……



















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











