









LLMs之EmbeddingModel/reRanker:gte-multilingual-base的简介、安装和使用方法、案例应用之详细攻略
导读:这篇论文介绍了mGTE,一个用于多语言文本检索的通用长上下文文本表示模型和重排序模型。mGTE 通过在长上下文多语言文本编码器、混合文本表示模型和交叉编码器重排序器上进行一系列的改进和优化,在保证检索效果的同时显著提高了效率。 其在长上下文多语言文本检索领域具有显著的优势,并有潜力应用于各种研究和工业场景。 反向缩放RoPE NTK和两阶段预训练策略的有效性也得到了实验验证。
>> 背景痛点:
● 长文本和多语言文本检索的需求日益增长: 现有的基于编码器的模型难以处理长文本和多语言文本,而大型语言模型(LLM)计算成本过高,不适合自托管搜索服务。
● 现有多语言编码器上下文窗口有限: 例如,之前的多语言编码器XLM-R的上下文窗口长度仅为512个token,无法有效处理长文本。
● 缺乏高效且有效的长上下文多语言检索模型: 现有模型在处理长上下文检索任务时,效率和效果难以兼顾。
● 需要高效的多语言文本表示模型和重排序器来改进检索性能。
>> 具体的解决方案:提出了mGTE,一种面向长上下文的多语言文本表示模型和重排序模型。论文提出了一种端到端的解决方案,包括一个长上下文多语言文本编码器、一个混合文本表示模型(TRM)和一个交叉编码器重排序器。
● 长上下文多语言文本编码器: 基于BERT架构,进行了多项改进,包括使用旋转位置编码(RoPE)代替绝对位置编码,将FFN升级为门控线性单元(GLU),移除注意力分数上的dropout,并将token embedding大小填充为64的倍数以提高吞吐量。 此外,引入了无填充(unpadding)机制以减少冗余计算。该编码器在原生8192个token的上下文中进行预训练。使用多阶段课程(2048-token到8192-token)进行掩码语言模型预训练。
● 混合文本表示模型 (TRM): 基于编码器构建,通过对比学习进行预训练和微调。使用InfoNCE损失函数,结合密集向量和稀疏向量两种表示方式。该模型结合了密集向量和稀疏向量两种表示方式。密集向量通过对比学习获得,稀疏向量则通过预测每个token的权重得到。TRM采用多任务学习的方式,同时优化Matryoshka嵌入和稀疏表示,以提供弹性向量表示。
● 交叉编码器重排序器: 该模型采用交叉编码器架构,根据对比学习进行微调。直接预测查询和文档的相关性得分。
>> 核心思路步骤:
● 文本编码器预训练: 使用两阶段的课程学习策略,先在2048个token的上下文中预训练,再在8192个token的上下文中预训练,均采用掩码语言建模(MLM)目标函数。
● 文本表示模型 (TRM) 预训练: 使用对比学习,对大量的弱相关文本对进行预训练,得到文本的密集向量表示。 使用了反向缩放RoPE NTK来适应较短的上下文长度。
● TRM 微调: 在高质量数据集上进行微调,同时学习Matryoshka嵌入和稀疏表示,目标函数为InfoNCE损失函数。
● 重排序器微调: 在相同的数据集上微调重排序器,同样使用InfoNCE损失函数,但调整了负样本的采样策略。
>> 优势:
● 高效:在训练和推理过程中都比同等规模的现有模型(如BGE-M3)效率更高,编码速度提升了14倍。无填充机制和xFormers库的应用是效率提升的关键。
● 有效:在多个多语言和长上下文检索基准测试中,其性能与大型的现有模型相当,甚至在长上下文检索任务上表现更好。
● 通用性:支持多种语言,能够处理长文本。
● 开源:模型和代码将开源,便于进一步的研究和应用。
目录
1、模型信息:305M,Dimension=768,Max_Tokens=8192
建议安装 xformers 并启用 unpadding 来加速,参考enable-unpadding-and-xformers
嵌入模型:文本嵌入模型有三个版本可用:text-embedding-v1/v2/v3,其中 v3 是最新 API 服务
相关文章
《mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval》翻译与解读
| 地址 | |
| 时间 | 2024年7月29日 |
| 作者 | 阿里巴巴集团,香港理工大学 |
| 摘要 | 我们介绍了从零开始构建长上下文多语言文本表示模型(TRM)和重排序器用于文本检索的系统性工作。首先,我们介绍了一个基于RoPE和无填充技术增强的文本编码器(基础尺寸),该编码器在原生8192个token的上下文中进行了预训练(比之前多语言编码器的512个token更长)。然后,我们通过对比学习构建了一个混合型TRM和一个交叉编码器重排序器。评估表明,我们的文本编码器性能优于相同大小的先前最先进XLM-R模型。同时,我们的TRM和重排序器达到了与大尺寸最先进BGE-M3模型相当的表现,并且在长上下文检索基准测试中取得了更好的结果。进一步分析显示,所提出的模型在训练和推理过程中都表现出更高的效率。我们认为它们的效率和有效性可以为各种研究和工业应用带来益处。 |
gte-multilingual-base的简介
gte -multilingual-base模型是GTE (通用文本嵌入)模型系列中的最新模型,具有几个关键属性:
>> 高性能:与类似规模的模型相比,在多语言检索任务和多任务表示模型评估中取得了最先进的(SOTA)结果。
>> 训练架构:使用仅编码器的 transformers 架构进行训练,从而减小了模型大小。与之前基于仅解码器的 LLM 架构的模型(例如 gte-qwen2-1.5b-instruct)不同,该模型对推理的硬件要求较低,推理速度提高了 10 倍。
>> 长上下文:支持最多8192 个标记的文本长度。
>> 多语言功能:支持超过70 种语言。
>> 弹性密集嵌入:支持弹性输出密集表示,同时保持下游任务的有效性,显著降低存储成本,提高执行效率。
>> 稀疏向量:除了密集表示之外,它还可以生成稀疏向量。
HuggingFace地址:https://huggingface.co/Alibaba-NLP/gte-multilingual-base
1、模型信息:305M,Dimension=768,Max_Tokens=8192
模型尺寸:305M
嵌入维度:768
最大输入令牌:8192
2、评估
我们在多个下游任务上验证了gte-multilingual-base模型的性能,包括多语言检索、跨语言检索、长文本检索以及MTEB 排行榜上的一般文本表示评估等。
检索任务
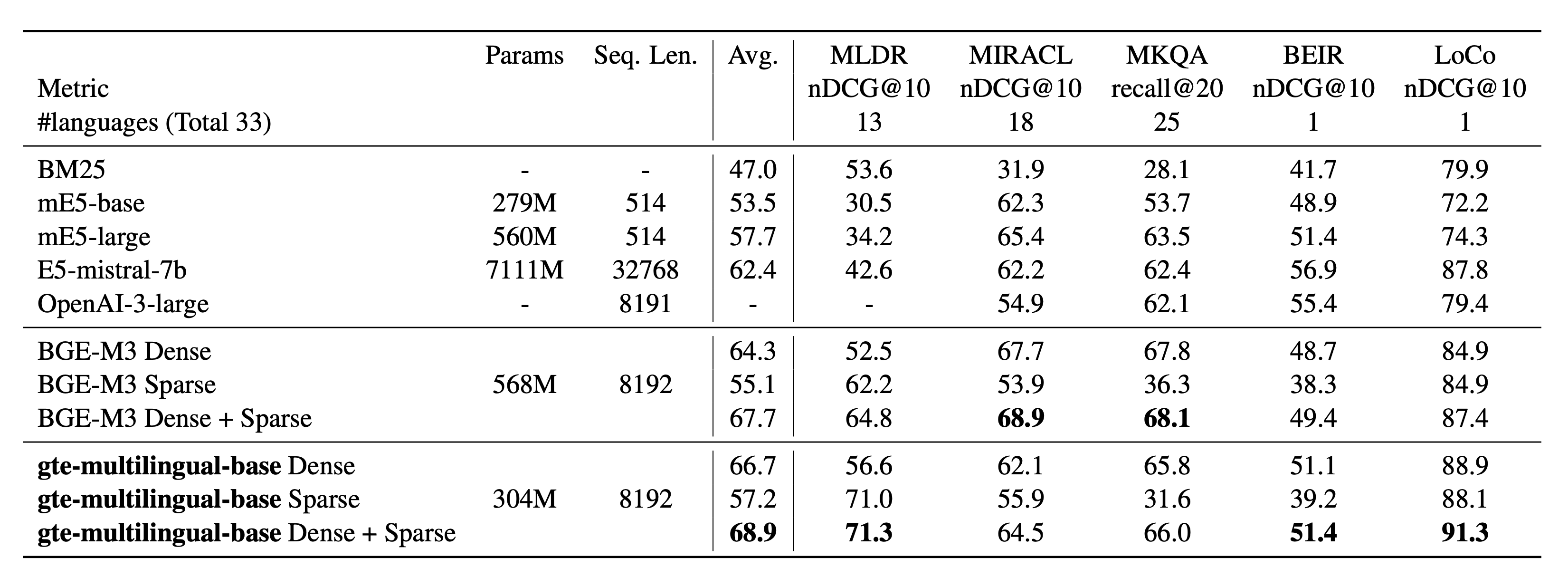
关于MIRACL和MLDR(多语言)、MKQA(跨语言)、BEIR和LoCo (英语)的检索结果。
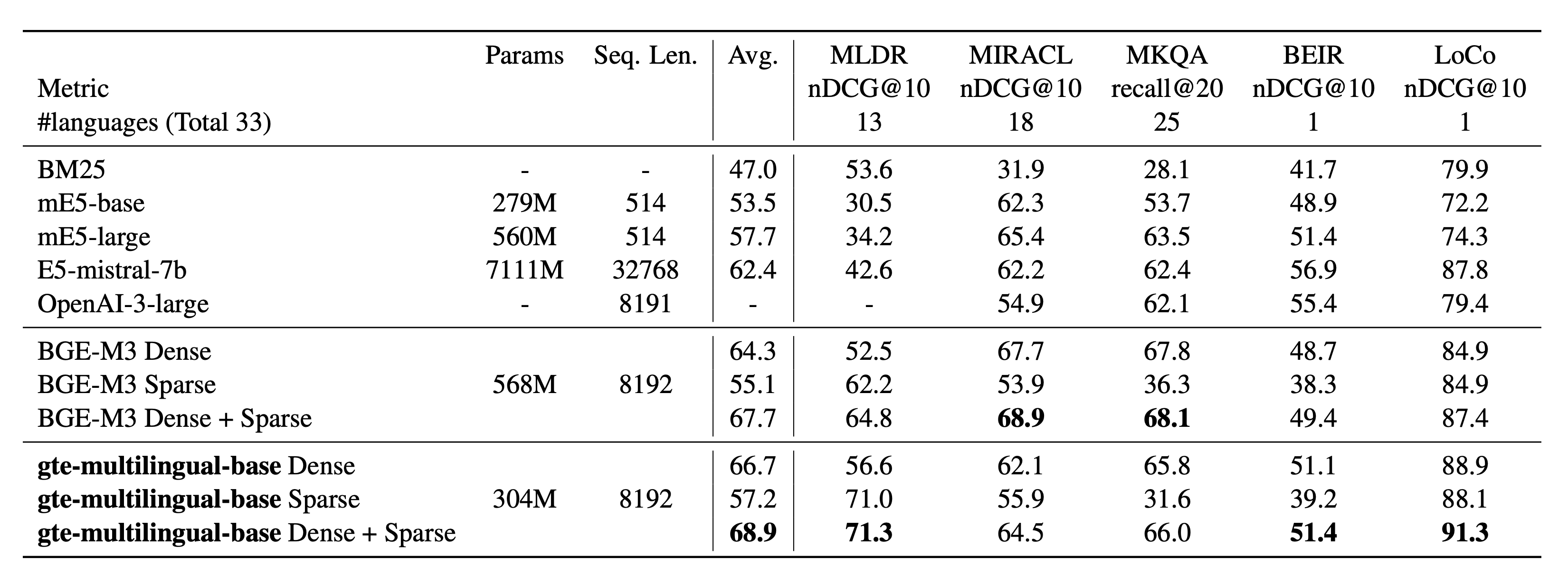
MLDR的详细结果
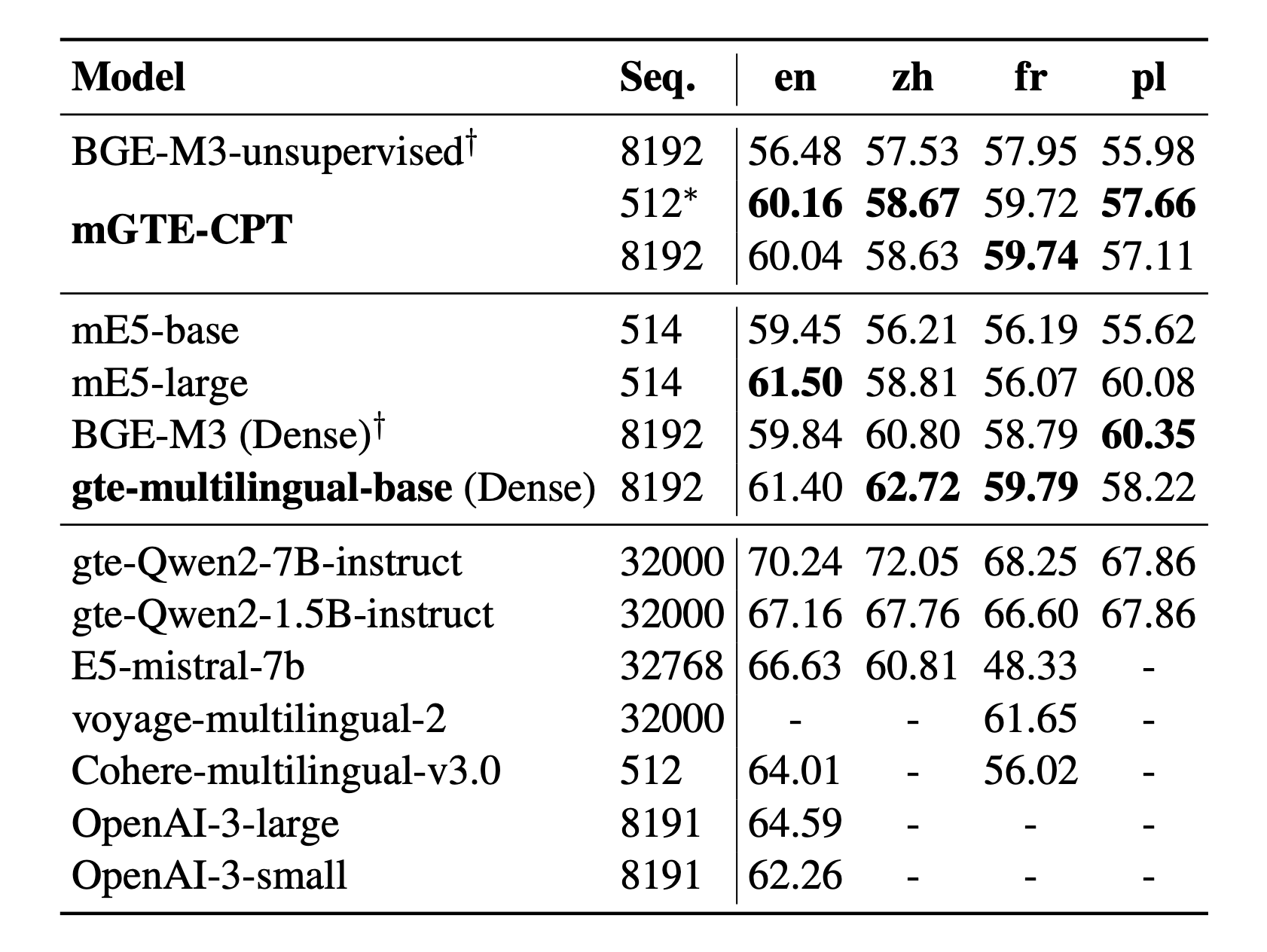
MTEB上的结果:英语、中文、法语、波兰语
gte-multilingual-base的安装和使用方法
1、安装
下载地址:https://huggingface.co/Alibaba-NLP/gte-multilingual-base
2、使用方法
建议安装 xformers 并启用 unpadding 来加速,参考enable-unpadding-and-xformers
如何离线使用:new-impl/discussions/2
地址:https://huggingface.co/Alibaba-NLP/new-impl/discussions/2#662b08d04d8c3d0a09c88fa3
如何与TEI一起使用:refs/pr/7
地址:https://huggingface.co/Alibaba-NLP/gte-multilingual-base/discussions/7#66bfb82ea03b764ca92a2221
3、云 API 服务
除了开源的GTE系列机型外,GTE系列机型在阿里云上也以商业API服务的形式提供。请注意,商业 API 背后的模型与开源模型并不完全相同。
嵌入模型:文本嵌入模型有三个版本可用:text-embedding-v1/v2/v3,其中 v3 是最新 API 服务
ReRank 模型:gte-rerank 模型服务可用
gte-multilingual-base的案例应用
1、使用 Transformer 实现密集嵌入
# Requires transformers>=4.36.0
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path = 'Alibaba-NLP/gte-multilingual-base'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=8192, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
dimension=768 # The output dimension of the output embedding, should be in [128, 768]
embeddings = outputs.last_hidden_state[:, 0][:dimension]
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
# [[0.3016996383666992, 0.7503870129585266, 0.3203084468841553]]
2、与sentence-transformers一起使用
# Requires transformers>=4.36.0
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path = 'Alibaba-NLP/gte-multilingual-base'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=8192, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
dimension=768 # The output dimension of the output embedding, should be in [128, 768]
embeddings = outputs.last_hidden_state[:, 0][:dimension]
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
# [[0.3016996383666992, 0.7503870129585266, 0.3203084468841553]]
3、与自定义代码一起使用以获取密集嵌入和稀疏标记权重
# You can find the script gte_embedding.py in https://huggingface.co/Alibaba-NLP/gte-multilingual-base/blob/main/scripts/gte_embedding.py
from gte_embedding import GTEEmbeddidng
model_name_or_path = 'Alibaba-NLP/gte-multilingual-base'
model = GTEEmbeddidng(model_name_or_path)
query = "中国的首都在哪儿"
docs = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
embs = model.encode(docs, return_dense=True,return_sparse=True)
print('dense_embeddings vecs', embs['dense_embeddings'])
print('token_weights', embs['token_weights'])
pairs = [(query, doc) for doc in docs]
dense_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.0)
sparse_scores = model.compute_scores(pairs, dense_weight=0.0, sparse_weight=1.0)
hybrid_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.3)
print('dense_scores', dense_scores)
print('sparse_scores', sparse_scores)
print('hybrid_scores', hybrid_scores)
# dense_scores [0.85302734375, 0.257568359375, 0.76953125, 0.325439453125]
# sparse_scores [0.0, 0.0, 4.600879669189453, 1.570279598236084]
# hybrid_scores [0.85302734375, 0.257568359375, 2.1497951507568356, 0.7965233325958252]



















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











