







LLMs之PE之MCP:模型上下文协议 (MCP)的简介、安装和使用方法、案例应用之详细攻略
目录
MCP的简介
2024年11月25日,Anthropic发布了MCP。模型上下文协议 (MCP) 是一种开放协议,用于简化大型语言模型 (LLM) 应用程序与外部数据源和工具之间的集成。它类似于 USB-C 接口,为 AI 应用提供标准化的连接方式,使 LLM 可以连接到不同的数据源和工具。 MCP 由 Anthropic 公司发起并维护,是一个开源项目,鼓励社区贡献。
总而言之,MCP 提供了一种灵活、可扩展且安全的机制,用于将 LLM 与外部数据源和工具集成,从而构建更强大和更智能的 AI 应用程序。 其开源特性和社区支持,也保证了其持续发展和改进。MCP 通过标准化 LLM 与外部资源的交互方式,简化了构建基于 LLM 的复杂应用的流程,并提升了应用的灵活性和安全性。 它提供了一套完整的工具和资源,帮助开发者构建和部署基于 MCP 的应用。
博客首发地址:https://www.anthropic.com/news/model-context-protocol
官网地址:Introduction - Model Context Protocol
GitHub地址:https://github.com/modelcontextprotocol
文档地址:https://docs.anthropic.com/en/docs/agents-and-tools/mcp
1、特点
>> 标准化:MCP 提供了一种标准化的方式,让应用程序为 LLM 提供上下文信息。这使得 LLM 可以轻松地与各种数据源和工具集成,而无需针对每个数据源编写特定的代码。
>> 可扩展性:MCP 支持多种编程语言的 SDK,包括 TypeScript、Python、Java、Kotlin 和 C#,方便开发者在不同的环境中使用。 它还支持多种传输方式,并提供灵活的扩展性,允许开发者根据需要添加新的功能和集成。
>> 安全性:MCP 提供了最佳实践,用于在基础设施内保护数据安全。
>> 互操作性:MCP 允许在不同的 LLM 提供商和厂商之间切换,提高了系统的灵活性。
>> 预构建集成:MCP 提供不断增长的预构建集成列表,LLM 可以直接插入这些集成。
>> 简化构建复杂工作流:MCP 有助于在 LLM 之上构建代理和复杂工作流。
2、为什么需要 MCP?
LLM 经常需要与数据和工具集成,MCP 提供以下优势:
>> 预构建集成:提供不断增长的预构建集成列表,LLM 可以直接使用。
>> 灵活性:允许在不同的 LLM 提供商和厂商之间灵活切换。
>> 数据安全:提供最佳实践,用于保护基础设施中的数据安全。
>> 构建复杂工作流:帮助构建基于 LLM 的代理和复杂工作流。
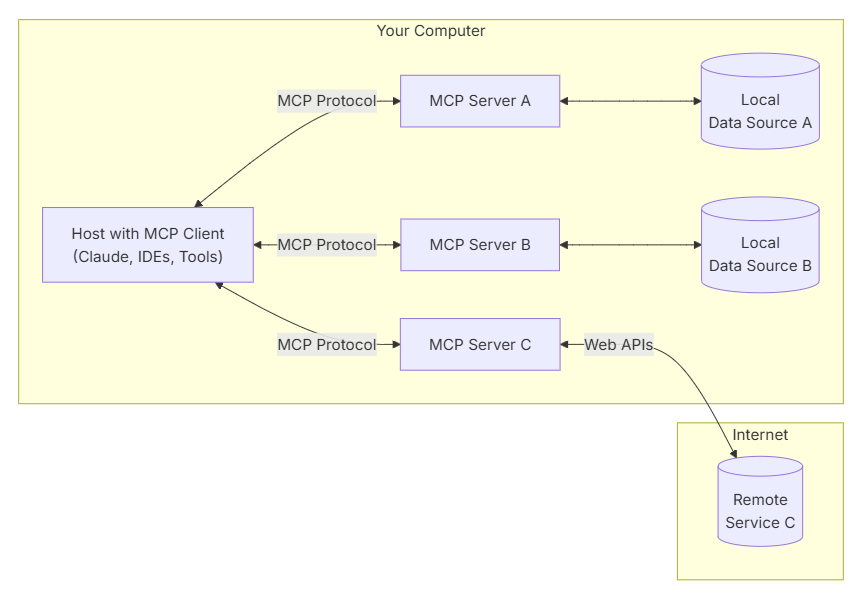
3、MCP总体架构
MCP 的核心遵循客户端-服务器架构,其中主机应用程序可以连接到多个服务器:
>> MCP 主机 (Hosts):例如 Claude Desktop、IDE 或其他想要通过 MCP 访问数据的 AI 工具。
>> MCP 客户端 (Clients):协议客户端,与服务器保持一对一连接。
>> MCP 服务器 (Servers):轻量级程序,通过标准化的 MCP 协议公开特定功能。
>> 本地数据源 (Local Data Sources):计算机的文件、数据库和 MCP 服务器可以安全访问的服务。
>> 远程服务 (Remote Services):通过互联网(例如,通过 API)提供的外部系统,MCP 服务器可以连接到这些系统。
MCP的安装和使用方法
MCP 的安装和使用方法取决于你所选择的 SDK 和应用场景。 GitHub 上提供了多种语言的 SDK,例如 TypeScript SDK、Python SDK、Java SDK、Kotlin SDK 和 C# SDK。 每个 SDK 都提供了相应的文档和示例代码,指导开发者如何使用 MCP。
1、安装
>> 选择合适的 SDK:根据你的编程语言和项目需求,选择合适的 SDK。
>> 安装 SDK:根据 SDK 的文档说明,安装相应的依赖包。
>> 创建服务器:开发一个 MCP 服务器,该服务器负责连接到你的数据源或工具,并通过 MCP 协议与 LLM 客户端通信。 GitHub 上提供了服务器模板,可以作为参考。
>> 创建客户端:开发一个 MCP 客户端,该客户端负责与 MCP 服务器通信,并将上下文信息传递给 LLM。 同样,GitHub 上也提供了客户端模板。
>> 集成 LLM:将 MCP 客户端集成到你的 LLM 应用程序中,使 LLM 可以访问 MCP 服务器提供的数据和工具。
2、使用方法
2.1、开发流程
-
准备文档:
在开始之前,需要收集必要的文档,以帮助LLM(如Claude)理解MCP的相关内容。这些文档包括:- 访问 MCP文档 并复制完整的文档文本。
- 导航到MCP的TypeScript SDK或Python SDK代码库,复制README文件和其他相关文档。
-
描述服务器:
向Claude清晰地描述你想要构建的服务器。具体包含:- 服务器将暴露哪些资源
- 提供哪些工具
- 应该提供哪些提示
- 需要与哪些外部系统交互
例如,可以描述构建一个连接到公司PostgreSQL数据库的MCP服务器,暴露表架构作为资源,并提供运行只读SQL查询的工具。
-
与Claude合作:
在构建MCP服务器时,可以通过以下方式与Claude进行互动:- 首先专注于核心功能,然后逐步添加更多特性。
- 请求Claude解释不理解的代码部分。
- 根据需要请求修改或改进。
- 让Claude帮助测试服务器并处理边界情况。
-
Claude的功能支持:
Claude可以帮助实现所有关键的MCP特性,包括:- 资源管理和暴露
- 工具定义和实现
- 提示模板和处理器
- 错误处理和日志记录
- 连接和传输设置
2.2、最佳实践
在使用Claude构建MCP服务器时,建议遵循以下最佳实践:
- 将复杂的服务器分解为更小的组件。
- 在继续之前彻底测试每个组件。
- 注意安全性——验证输入并适当限制访问。
- 为未来的维护良好地记录代码。
- 仔细遵循MCP协议规范。
2.3、后续步骤
在Claude帮助你构建服务器之后:
- 认真审查生成的代码。
- 使用MCP Inspector工具测试服务器。
- 将其连接到Claude.app或其他MCP客户端。
- 根据实际使用情况和反馈进行迭代。
MCP的案例应用
GitHub 上的 servers 目录列出了多个已维护的 MCP 服务器,以及 example-clients 展示了支持 MCP 集成的客户端列表。 虽然具体案例应用细节没有在提供的链接中详细描述,但从其架构和功能描述可以推断出 MCP 可用于构建各种 AI 应用,例如:
>> AI 驱动的 IDE:将 IDE 与代码库、文档和其他工具集成。
>> 增强型聊天界面:将聊天界面与外部知识库和服务集成。
>> 自定义 AI 工作流:创建自定义的 AI 工作流,将 LLM 与各种数据源和工具连接起来。
>> Claude for Desktop:该应用直接使用了 MCP 来连接预构建的服务器,访问各种数据和功能。
持续更新中……



















 3372
3372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











