







LLMs之DeepSeek:仅需四个步骤的最简练实现DeepSeek-R1推理—基于Ollama框架实现本地部署并启用DeepSeek-R1实现推理图文教程
目录
LLM之Ollama:ollama的简介、安装和使用方法、案例应用之详细攻略
第二步、基于Ollama实现本地部署并启用DeepSeek-R1模型服务
(4)、查看deepseek-r1模型的信息:基于qwen2模型架构进行Q4_K_M量化而来
第一步、安装Ollama
LLM之Ollama:ollama的简介、安装和使用方法、案例应用之详细攻略
LLM之Ollama:ollama的简介、安装和使用方法、案例应用之详细攻略_ollama中文说明书-CSDN博客
第二步、基于Ollama实现本地部署并启用DeepSeek-R1模型服务
(1)、进入官网,找到对应模型的下载命令
地址:Ollama
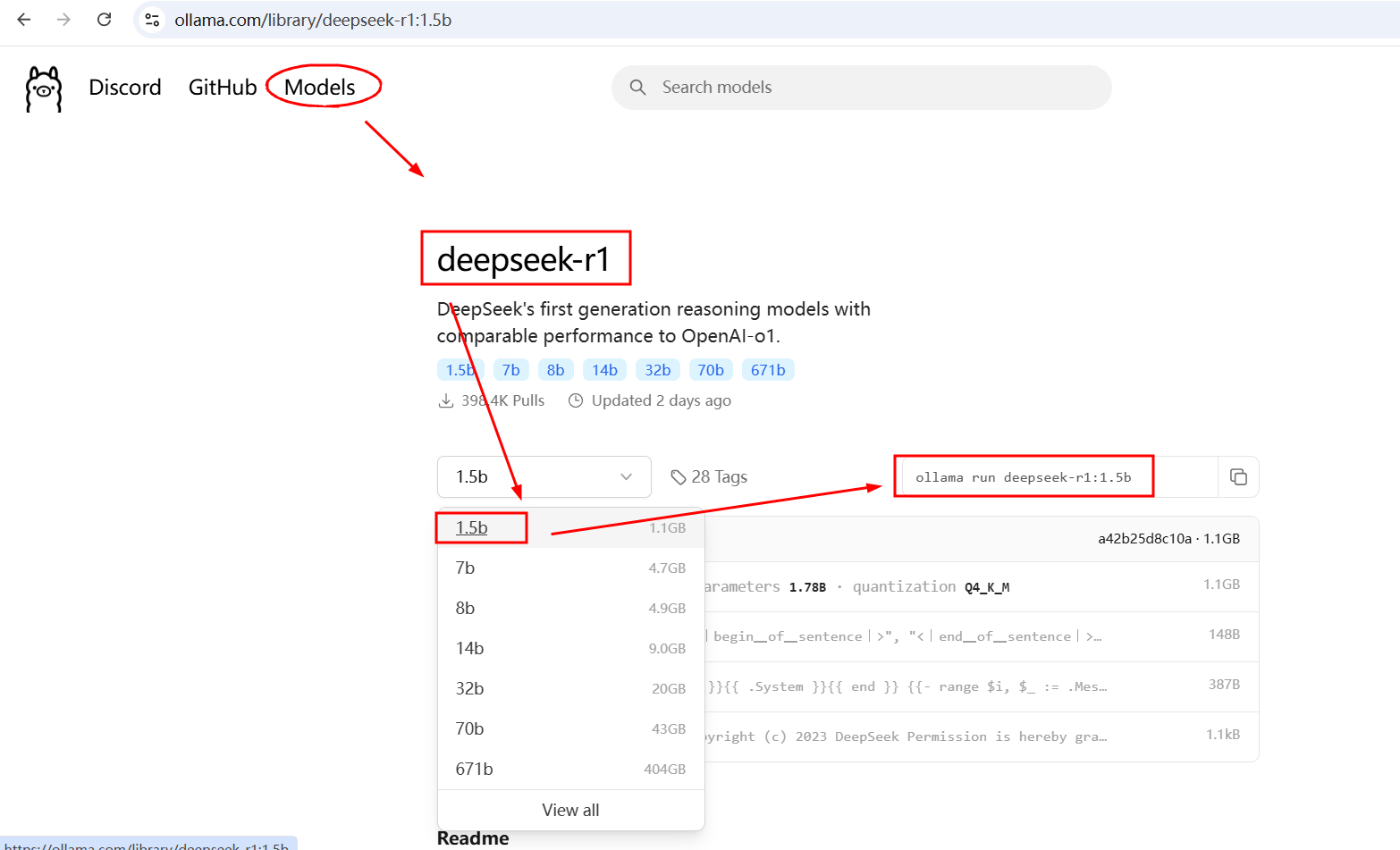
(2)、本地打开ollama,执行下载命令
ollama run deepseek-r1:1.5b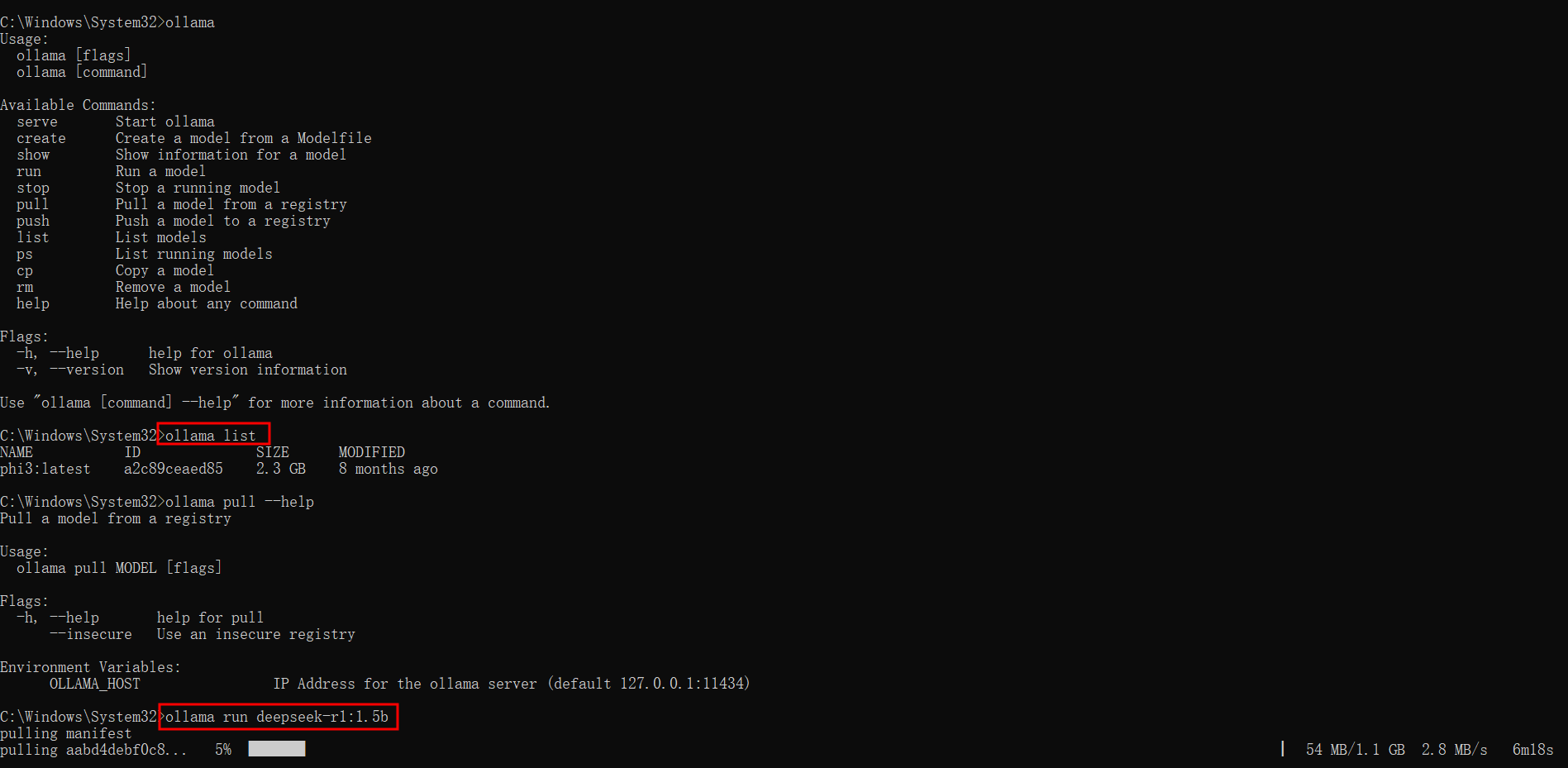
查看模型默认下载路径
(3)、测试deepseek-r1模型
ollama run deepseek-r1:1.5b
ollama list # 列出计算机上的模型
ollama ps # 列出当前加载的模型
ollama show llama3.2 # 显示模型信息
ollama stop llama3.2 # 停止当前正在运行的模型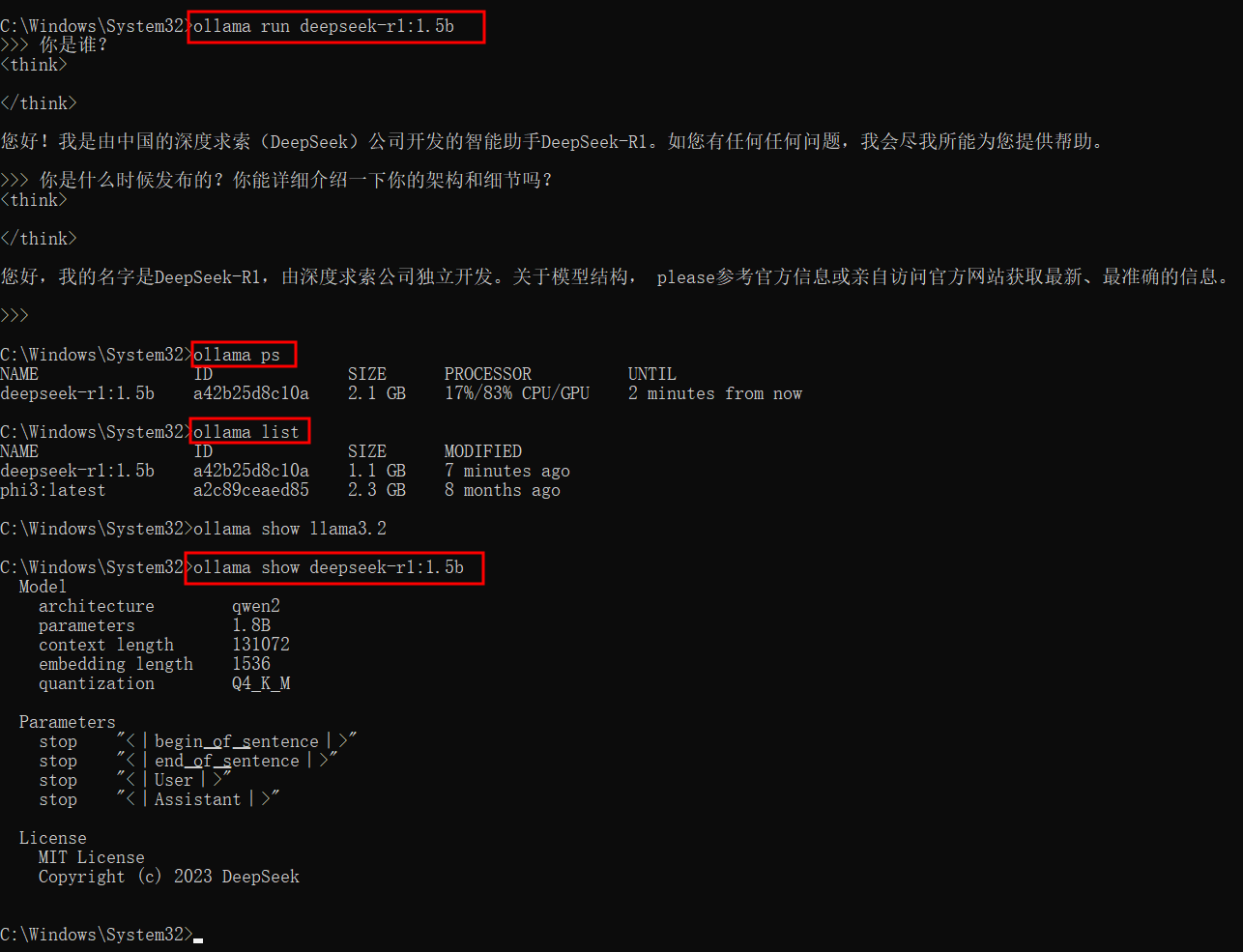
(4)、查看deepseek-r1模型的信息:基于qwen2模型架构进行Q4_K_M量化而来
Model
architecture qwen2
parameters 1.8B
context length 131072
embedding length 1536
quantization Q4_K_M


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











