







LLMs之s1:《s1: Simple test-time scaling》翻译与解读
导读:论文关注的是语言模型的测试时缩放 (test-time scaling) 技术,s1 方法提供了一种简单、高效且样本效率极高的测试时缩放方法,能够显著提升语言模型的推理能力。 其核心在于精心设计的小型数据集 s1K 和创新的预算强制技术。 该方法的开源特性也为语言模型推理能力的研究提供了新的方向和思路。 论文的研究结果挑战了以往对大型数据集和复杂方法的依赖,为资源受限环境下的语言模型推理能力提升提供了新的可能性。
>> 背景痛点:
● 现有语言模型的推理能力瓶颈:虽然近年来大型语言模型 (LLM) 的性能有了显著提升,但这主要依赖于训练时的大规模计算。 在推理阶段,模型的性能往往受限,尤其是在需要复杂推理的任务上。
● OpenAI o1 模型的启示和挑战:OpenAI 的 o1 模型展示了测试时缩放的潜力,即通过增加测试时的计算来提高性能。然而,o1 模型的方法并未公开,导致许多研究者尝试复现,但大多依赖复杂方法且效果不佳,没有清晰地复现测试时缩放行为。
>> 具体的解决方案:论文提出了一种名为 s1 的简单测试时缩放方法,它结合了精心策划的小型数据集和一种名为“预算强制 (budget forcing)”的测试时技术。
>> 核心思路步骤:
● 数据集构建 (s1K):构建了一个包含 1000 个高质量、多样化且难度适中的问题及其推理过程的数据集 s1K。 数据集的筛选遵循三个关键标准:难度 (Difficulty)、多样性 (Diversity) 和质量 (Quality)。
● 监督微调 (SFT):使用 s1K 数据集对现成的预训练模型 Qwen2.5-32B-Instruct 进行监督微调,得到 s1-32B 模型。
● 预算强制 (Budget Forcing):提出了一种简单的测试时技术——预算强制。该技术通过强制终止模型的思考过程或通过多次附加“Wait”来延长思考过程,从而控制模型的测试时计算量。 这可以引导模型仔细检查答案,纠正错误的推理步骤。
>> 优势:
● 样本效率高:s1 方法仅需 1000 个样本进行训练,就达到了与更复杂方法相当甚至更好的推理性能,显著提高了样本效率。
● 简单高效:s1 方法简单易于实现,避免了复杂的强化学习或多智能体方法。
● 测试时缩放效果显著:s1-32B 模型在多个基准测试中都展现出明显的测试时缩放特性,即随着测试时计算量的增加,性能也得到提升。
● 开源:模型、数据和代码均已开源,方便其他研究者复现和改进。
>> 结论和观点:
● 小型高质量数据集的重要性:论文强调了精心策划的小型数据集在提高语言模型推理能力方面的关键作用。 随机选择样本或仅关注样本长度或多样性都会导致性能显著下降。
● 预算强制的有效性:预算强制是一种简单有效的测试时缩放技术,能够精确控制模型的计算量,并带来性能提升。 与其他测试时缩放方法相比,预算强制具有更好的可控性和缩放效果。
● 序列式缩放优于并行式缩放:论文指出,序列式缩放 (sequential scaling) 比并行式缩放 (parallel scaling) 更有效,因为后续计算可以建立在中间结果之上,从而进行更深入的推理和迭代改进。
● 预训练模型的重要性:论文认为,预训练模型中已经包含了大量的推理知识,s1 方法的微调只是激活并进一步扩展了这些能力。
目录
LLMs之s1:《s1: Simple test-time scaling》翻译与解读
LLMs之s1:s1的简介、特点、安装和使用方法、案例应用之详细攻略
《s1: Simple test-time scaling》翻译与解读
6.1 Sample-efficient reasoning样本高效推理
Limits to further test-time scaling进一步测试时间扩展的限制
Parallel scaling as a solution并行扩展作为一种解决方案
相关文章
LLMs之s1:《s1: Simple test-time scaling》翻译与解读
https://yunyaniu.blog.csdn.net/article/details/145483602
LLMs之s1:s1的简介、特点、安装和使用方法、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/145483596
《s1: Simple test-time scaling》翻译与解读
| 地址 | |
| 时间 | 2025年2月3日 |
| 作者 | Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, Tatsunori Hashimoto |
Abstract
| Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1-32B exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1-32B with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at this https URL | Test-time scaling是一种很有前景的语言建模新方法,它利用额外的测试时计算来提高性能。最近,OpenAI 的 o1 模型展示了这种能力,但并未公开其方法,导致了众多的复制尝试。我们寻求实现测试时缩放和强大推理性能的最简单方法。首先,我们根据三个通过消融验证的标准(难度、多样性和质量)整理了一个包含 1000 个问题及其推理过程的小数据集 s1K。其次,我们开发了预算强制技术,通过强制终止模型的思考过程或在模型试图结束时多次追加“等待”来控制测试时计算。这可以使模型重新检查其答案,通常能纠正错误的推理步骤。在对 Qwen2.5-32B-Instruct 语言模型进行监督微调以适应 s1K 并配备预算强制技术后,我们的模型 s1-32B 在竞赛数学问题上的表现超过了 o1-preview,最高提升了 27%(MATH 和 AIME24)。此外,通过预算强制技术对 s1-32B 进行缩放,可以在不进行测试时干预的情况下超越其性能:在 AIME24 上从 50% 提升到 57%。我们的模型、数据和代码在以下这个 https 网址上是开源的。 |
Figure 1. Test-time scaling with s1-32B. We benchmark s1-32B on reasoning-intensive tasks and vary test-time compute.图 1.使用 s1-32B 进行测试时的缩放。我们在推理密集型任务上对 s1-32B 进行基准测试,并改变测试时的计算量。
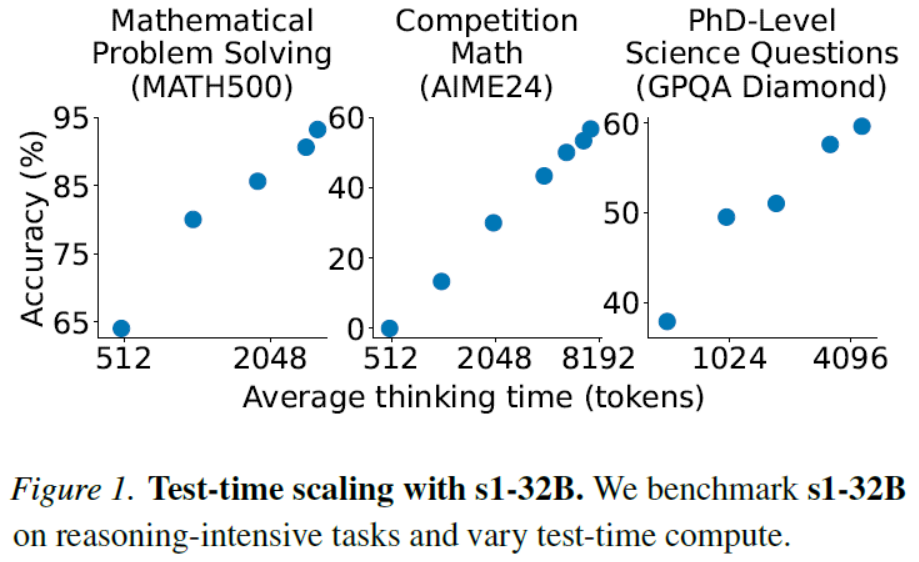
1、Introduction
| Performance improvements of language models (LMs) over the past years have largely relied on scaling up train-time compute using large-scale self-supervised pretraining (Ka-plan et al., 2020; Hoffmann et al., 2022). The creation of these powerful models has set the stage for a new scaling of this approach is to increase the compute at test time to get better results. There has been much work exploring this idea (Snell et al., 2024; Welleck et al., 2024), and the via-bility of this paradigm was recently validated by OpenAI o1 (OpenAI, 2024). o1 has demonstrated strong reasoning performance with consistent gains from scaling test-time compute. OpenAI describes their approach as using large-scale reinforcement learning (RL) implying the use of sizable amounts of data (OpenAI, 2024). This has led to various attempts to replicate their models relying on techniques like Monte Carlo Tree Search (Gao et al., 2024b; Zhang et al., 2024a), multi-agent approaches (Qin et al., 2024), and oth-ers (Wang et al., 2024a; Huang et al., 2024b; 2025). Among these approaches, DeepSeek R1 (DeepSeek-AI et al., 2025) has successfully replicated o1-level performance, also em-ploying reinforcement learning via millions of samples and multiple training stages. However, despite the large num-ber of o1 replication attempts, none have openly replicated a clear test-time scaling behavior. Thus, we ask: what is the simplest approach to achieve both test-time scaling and strong reasoning performance? | 近年来,语言模型(LMs)性能的提升主要依赖于在训练时通过大规模自监督预训练来增加计算量(Ka-plan 等人,2020 年;Hoffmann 等人,2022 年)。这些强大模型的创建为一种新的扩展方式奠定了基础,即在测试时增加计算量以获得更好的结果。对此想法的研究工作有很多(Snell 等人,2024 年;Welleck 等人,2024 年),并且 OpenAI 的 o1 最近验证了这种范式的可行性(OpenAI,2024 年)。o1 展示了强大的推理性能,并且随着测试时计算量的增加而持续提升。OpenAI 将其方法描述为使用大规模强化学习(RL),这意味着使用了大量数据(OpenAI,2024 年)。这导致了各种尝试复制其模型的努力,采用了诸如蒙特卡罗树搜索(Gao 等人,2024 年 b;Zhang 等人,2024 年 a)、多智能体方法(Qin 等人,2024 年)以及其他方法(Wang 等人,2024 年 a;Huang 等人,2024 年 b;2025 年)。在这些方法中,DeepSeek R1(DeepSeek-AI 等人,2025 年)已成功复制了 o1 级别的性能,同样通过数百万个样本和多个训练阶段采用了强化学习。然而,尽管进行了大量的 o1 复制尝试,但没有一个公开复制出明确的测试时间缩放行为。因此,我们提出问题:实现测试时间缩放和强大推理性能的最简单方法是什么? |
| We show that training on only 1,000 samples with next-token prediction and controlling thinking duration via a simple test-time technique we refer to as budget forcing leads to a strong reasoning model that scales in performance with more test-time compute. Specifically, we construct s1K, which consists of 1,000 carefully curated questions paired with reasoning traces and answers distilled from Gemini Thinking Experimental (Google, 2024). We perform super-vised fine-tuning (SFT) of an off-the-shelf pretrained model on our small dataset requiring just 26 minutes of training on 16 H100 GPUs. After training, we control the amount of test-time compute our model spends using budget forc-ing: (I) If the model generates more thinking tokens than a desired limit, we forcefully end the thinking process by appending an end-of-thinking token delimiter. Ending the thinking this way makes the model transition to generating its answer. (II) If we want the model to spend more test-time compute on a problem, we suppress the generation of the end-of-thinking token delimiter and instead append “Wait” to the model’s current reasoning trace to encourage more exploration. Equipped with this simple recipe – SFT on 1,000 samples and test-time budget forcing – our model s1-32B exhibits test-time scaling (Figure 1). Further, s1-32B is the most sample-efficient reasoning model and outperforms closed-source models like OpenAI’s o1-preview (Figure 2). | 我们表明,仅使用 1000 个样本进行训练,采用下一个标记预测,并通过一种我们称为预算强制的简单测试时间技术来控制思考时长,就能得到一个强大的推理模型,其性能会随着测试时间计算量的增加而提升。具体来说,我们构建了 s1K,它由 1000 个精心挑选的问题以及从 Gemini Thinking Experimental(谷歌,2024 年)中提炼出的推理轨迹和答案组成。我们在我们的小数据集上对一个现成的预训练模型进行监督微调(SFT),仅需在 16 个 H100 GPU 上训练 26 分钟。训练完成后,我们通过预算强制来控制模型在测试时的计算量:(I)如果模型生成的思考标记超过了期望的限制,我们就会强制结束思考过程,在模型的推理轨迹后附加一个思考结束标记。以这种方式结束思考能让模型转而生成答案。(II)如果希望模型在某个问题上花费更多的测试计算量,我们就会抑制思考结束标记的生成,而是附加“等待”字样到模型当前的推理轨迹中,以鼓励更多的探索。凭借这一简单的方法——在 1000 个样本上进行有监督微调以及测试时的预算强制——我们的模型 s1-32B 展现出了测试时的计算量扩展(图 1)。此外,s1-32B 是样本效率最高的推理模型,并且优于像 OpenAI 的 o1-preview 这样的闭源模型(图 2)。 |
| We conduct extensive ablation experiments targeting (a) our selection of 1,000 (1K) reasoning samples and (b) our test-time scaling. For (a), we find that jointly incorporating difficulty, diversity, and quality measures into our selec-tion algorithm is important. Random selection, selecting samples with the longest reasoning traces, or only selecting maximally diverse samples all lead to significantly worse performance (around −30% on AIME24 on average). Train-ing on our full data pool of 59K examples, a superset of s1K, does not offer substantial gains over our 1K selection. This highlights the importance of careful data selection and echoes prior findings for instruction tuning (Zhou et al.,2023). For (b), we define desiderata for test-time scaling methods to compare different approaches. Budget forcing leads to the best scaling as it has perfect controllability with a clear positive slope leading to strong performance. | 我们针对(a)我们选择的 1000 个推理样本以及(b)测试时的计算量扩展进行了广泛的消融实验。对于(a),我们发现将难度、多样性和质量指标共同纳入我们的选择算法中是很重要的。随机选择、选择推理痕迹最长的样本或仅选择最大多样性的样本都会导致性能显著下降(在 AIME24 上平均下降约 30%)。在我们的 59K 示例的完整数据池上进行训练,并未比我们的 1K 选择带来显著提升。这突显了精心挑选数据的重要性,并与先前关于指令调优的研究结果(Zhou 等人,2023 年)相呼应。对于(b),我们为测试时缩放方法定义了期望,以比较不同的方法。预算强制导致最佳缩放,因为它具有完美的可控性,且具有明显的正斜率,从而带来强劲的性能。 |
| In summary, our contributions are: We develop simple meth-ods for creating a sample-efficient reasoning dataset (§2) and test-time scaling (§3); Based on these we build s1-32B which is competitive with o1-preview (§4); We ablate sub-tleties of data (§5.1) and test-time scaling (§5.2). We end with a discussion to motivate future work on simple rea-soning (§6). Our code, model, and data are open-source at https://github.com/simplescaling/s1. | 总之,我们的贡献在于:我们开发了用于创建样本高效推理数据集(第 2 节)和测试时缩放(第 3 节)的简单方法;基于这些方法,我们构建了 s1-32B,其性能可与 o1-preview 相媲美(第 4 节);我们消除了数据(第 5.1 节)和测试时缩放(第 5.2 节)的细微差别。最后,我们进行了讨论以激励未来关于简单推理的工作(第 6 节)。我们的代码、模型和数据在 https://github.com/simplescaling/s1 上开源。 |
6 Discussion and related work
6.1 Sample-efficient reasoning样本高效推理
Models
| There are a number of concurrent efforts to build models that replicate the performance of o1 (OpenAI, 2024). For example, DeepSeek-r1 and k1.5 (DeepSeek-AI et al., 2025; Team et al., 2025) are built with reinforcement learning methods, while others rely on SFT using tens of thousands of distilled examples (Team, 2025; Xu et al., 2025; Labs, 2025). We show that SFT on only 1,000 examples suffices to build a competitive reasoning model matching o1-preview and produces a model that lies on the pareto frontier (Figure 2). Further, we introduce budget forcing which combined with our reasoning model leads to the first reproduction of OpenAI’s test-time scaling curves (OpenAI, 2024). Why does supervised finetuning on just 1,000 samples lead to such performance gains? We hypothesize that the model is already exposed to large amounts of reasoning data during pretraining which spans trillions of tokens. Thus, the ability to perform reasoning is already present in our model. Our sample-efficient finetuning stage just activates it and we scale it further at test time with budget forcing. This is similar to the ”Superficial Alignment Hypothesis” presented in LIMA (Zhou et al., 2023), where the authors find that 1,000 examples can be sufficient to align a model to adhere to user preferences. | 目前有许多并行的努力致力于构建能够复制 o1(OpenAI,2024 年)性能的模型。例如,DeepSeek-r1 和 k1.5(DeepSeek-AI 等人,2025 年;Team 等人,2025 年)是通过强化学习方法构建的,而其他模型则依赖于使用数万个精炼样本进行监督微调(Team,2025 年;Xu 等人,2025 年;Labs,2025 年)。我们表明,仅使用 1000 个样本进行监督微调就足以构建一个与 o1 预览版相媲美的推理模型,并生成一个位于帕累托前沿的模型(图 2)。此外,我们引入了预算强制机制,结合我们的推理模型,首次重现了 OpenAI 的测试时间缩放曲线(OpenAI,2024 年)。为什么仅对 1000 个样本进行监督微调就能带来如此显著的性能提升?我们假设模型在预训练期间已经接触到了大量的推理数据,这些数据涵盖了数万亿个标记。因此,推理能力已经存在于我们的模型中。我们的样本高效微调阶段只是激活了这种能力,并在测试时通过预算强制机制进一步扩展它。这与 LIMA(周等人,2023 年)中提出的“表面对齐假设”类似,该研究发现 1000 个示例就足以使模型对齐以遵循用户偏好。 |
Benchmarks and methods基准和方法
| To evaluate and push the limits of these models, increasingly challenging benchmarks have been introduced, such as Olympiad-level science competitions (He et al., 2024; Jain et al., 2024; Zhong et al., 2023) and others (Srivastava et al., 2023; Glazer et al., 2024; Su et al., 2024; Kim et al., 2024; Phan et al., 2025). To enhance models’ performance on reasoning-related tasks, researchers have pursued several strategies: Prior works have explored continuing training language models on specialized corpora related to mathematics and science (Azerbayev et al., 2023; Yang et al., 2024), sometimes even synthetically generated data (Yu et al., 2024). Others have developed training methodologies specifically aimed at reasoning performance (Zelikman et al., 2022, 2024; Luo et al., 2025; Yuan et al., 2025; Wu et al., 2024a). Another significant line of work focuses on prompting-based methods to elicit and improve reasoning abilities, including methods like Chain-of-Thought prompting (Wei et al., 2023; Yao et al., 2023a, b; Bi et al., 2023; Fu et al., 2023; Zhang et al., 2024b; Xiang et al., 2025; Hu et al., 2024). These combined efforts aim to advance the reasoning ability of language models, enabling them to handle more complex and abstract tasks effectively. | 为了评估并突破这些模型的极限,人们引入了越来越具挑战性的基准测试,例如奥林匹克级别的科学竞赛(He 等人,2024 年;Jain 等人,2024 年;Zhong 等人,2023 年)以及其他基准(Srivastava 等人,2023 年;Glazer 等人,2024 年;Su 等人,2024 年;Kim 等人,2024 年;Phan 等人,2025 年)。为了提升模型在推理相关任务上的表现,研究人员采取了多种策略:先前的研究探索了在与数学和科学相关的专门语料库上继续训练语言模型(Azerbayev 等人,2023 年;Yang 等人,2024 年),有时甚至使用合成生成的数据(Yu 等人,2024 年)。还有人开发了专门针对推理性能的训练方法(Zelikman 等人,2022 年、2024 年;Luo 等人,2025 年;Yuan 等人,2025 年;Wu 等人,2024 年 a)。另一条重要的研究路线专注于基于提示的方法来激发和提升推理能力,包括诸如“思维链”提示等方法(Wei 等人,2023 年;Yao 等人,2023 年 a、b;Bi 等人,2023 年;Fu 等人,2023 年;Zhang 等人,2024 年 b;Xiang 等人,2025 年;Hu 等人,2024 年)。这些综合努力旨在提升语言模型的推理能力,使它们能够有效地处理更复杂和抽象的任务。 |
6.2 Test-time scaling测试时缩放方法
Methods
| As we introduce in §3, we differentiate two methods to scale test-time compute: parallel and sequential. The former relies on multiple solution attempts generated in parallel and selecting the best outcome via specific criteria. These criteria include choosing the most frequent response for majority voting or the best response based on an external reward for Best-of-N (Brown et al., 2024; Irvine et al., 2023; Snell et al., 2024). Unlike repeated sampling, previous sequential scaling methods let the model generate solution attempts sequentially based on previous attempts, allowing it to refine each attempt based on previous outcomes (Snell et al., 2024; Hou et al., 2025; Lee et al., 2025). Tree-based search methods (Gandhi et al., 2024; Wu et al., 2024b) offer a hybrid approach between sequential and parallel scaling, such as Monte-Carlo Tree Search (MCTS) (Liu et al., 2024; Zhang et al., 2023; Zhou et al., 2024; Choi et al., 2023) and guided beam search (Xie et al., 2023). REBASE (Wu et al., 2024b) employs a process reward model to balance exploitation and pruning during tree search. Empirically, REBASE has been shown to outperform sampling-based methods and MCTS (Wu et al., 2024b). Reward models (Lightman et al., 2023; Wang et al., 2024b, c) play a key role in these methods. They come in two variants: outcome reward models and process reward models. Outcome reward models (Xin et al., 2024; Ankner et al., 2024) assign a score to complete solutions and are particularly useful in Best-of-N selection, while process reward models (Lightman et al., 2023; Wang et al., 2024b; Wu et al., 2024b) assess individual reasoning steps and are effective in guiding tree-based search methods. | 正如我们在第 3 节中所介绍的,我们将测试时间计算的扩展方法分为两类:并行和顺序。前者依赖于并行生成的多个解决方案尝试,并通过特定标准选择最佳结果。这些标准包括基于多数投票选择最频繁的响应,或者基于外部奖励选择最佳响应的“N 中选优”(Brown 等人,2024 年;Irvine 等人,2023 年;Snell 等人,2024 年)。与重复采样不同,先前的顺序扩展方法让模型基于之前的尝试依次生成解决方案尝试,使其能够根据之前的输出结果来优化每个尝试(Snell 等人,2024 年;Hou 等人,2025 年;Lee 等人,2025 年)。基于树的搜索方法(Gandhi 等人,2024 年;Wu 等人,2024 年 b)提供了顺序和并行扩展之间的混合方法,例如蒙特卡罗树搜索(MCTS)(Liu 等人,2024 年;Zhang 等人,2023 年;Zhou 等人,2024 年;Choi 等人,2023 年)和引导束搜索(Xie 等人,2023 年)。REBASE(Wu 等人,2024 年 b)采用过程奖励模型在树搜索期间平衡利用和剪枝。从经验来看,REBASE 已被证明优于基于采样的方法和蒙特卡罗树搜索(Wu 等人,2024b)。奖励模型(Lightman 等人,2023;Wang 等人,2024b,c)在这些方法中起着关键作用。它们有两种变体:结果奖励模型和过程奖励模型。结果奖励模型(Xin 等人,2024;Ankner 等人,2024)为完整解决方案分配分数,在最佳 N 选择中特别有用,而过程奖励模型(Lightman 等人,2023;Wang 等人,2024b;Wu 等人,2024b)评估单个推理步骤,在指导基于树的搜索方法方面效果显著。 |
Limits to further test-time scaling进一步测试时间扩展的限制
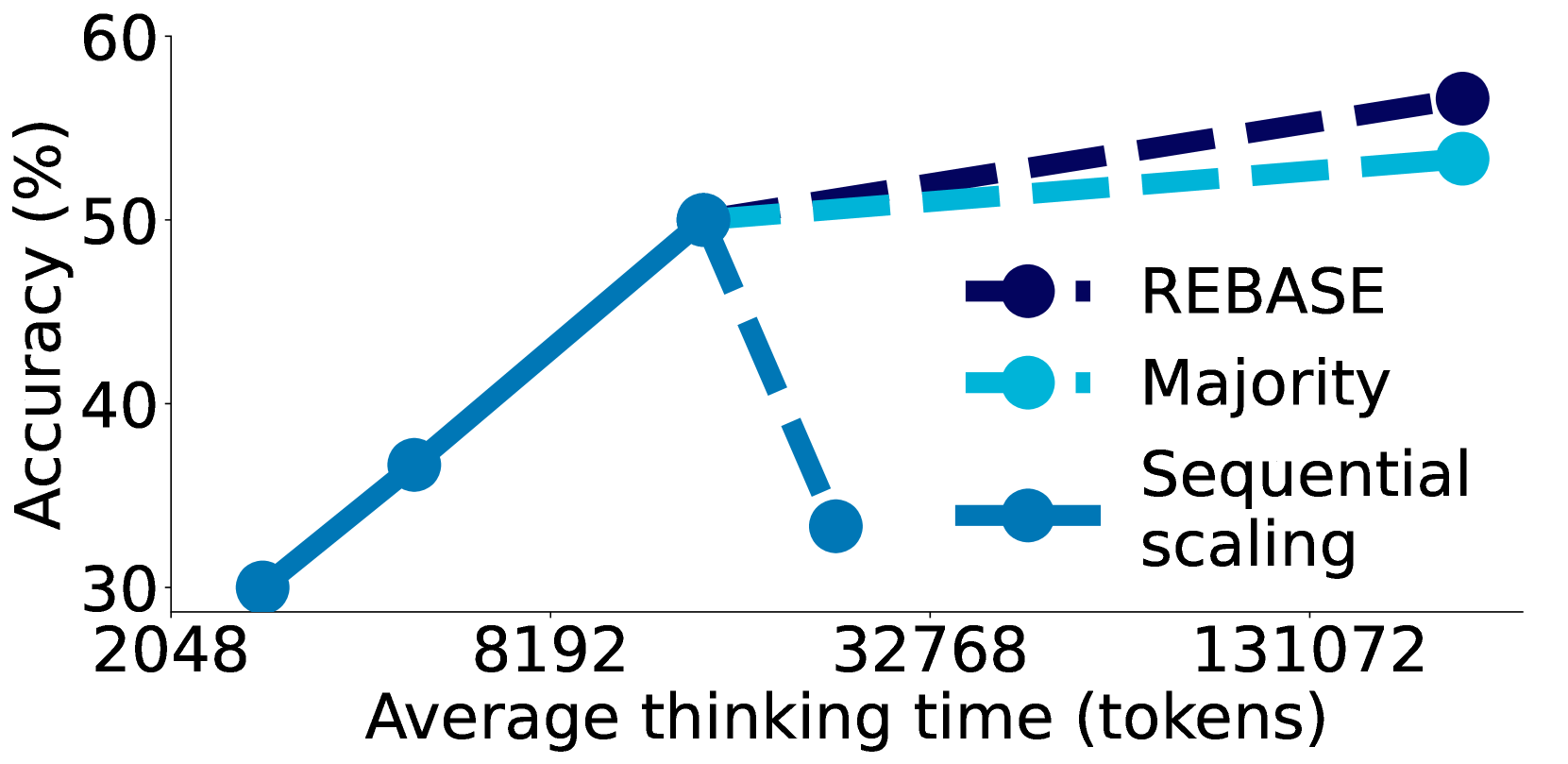
| We have shown that budget forcing allows extrapolating test-time compute in §4, e.g., improving AIME24 performance from 50% to 57%. However, it has two key limitations when scaling further: it eventually flattens out (Figure 4), and the context window of the underlying language model constrains it. Despite these constraints, our work shows test-time scaling across a wide range of accuracies (Figure 1), partly because scaling down test-time compute behaves predictably and does not suffer from these constraints. Continuing test-time scaling will require approaches that can further extrapolate test-time compute. How can we get such extrapolation? There may be improvements to budget forcing such as rotating through different strings, not only “Wait”, or combining it with frequency penalties or higher temperature to avoid repetitive loops. An exciting direction for future work is also researching whether applying budget forcing to a reasoning model trained with reinforcement learning yields better extrapolation; or if RL allows for new ways of test-time scaling beyond budget forcing. Our work defines the right metrics (§3.2) – Control, Scaling, and Performance – to enable future research and progress on extrapolating test-time compute. Figure 7:Scaling further with parallel scaling methods. All metrics averaged over the 30 questions in AIME24. Average thinking tokens for REBASE do not account for the additional compute from the reward model. For sequential scaling, we prompt the model to use up to (from left to right) 32, 64, 256, and 512 steps. For REBASE and majority voting we generate 16 parallel trajectories to aggregate across. | 我们在第 4 节中展示了预算强制允许外推测试时间计算,例如将 AIME24 的性能从 50% 提升至 57%。然而,当进一步扩展时,它存在两个关键限制:最终会趋于平稳(图 4),并且底层语言模型的上下文窗口对其构成限制。尽管存在这些限制,我们的工作表明测试时间计算在广泛的准确率范围内均可扩展(图 1),部分原因是降低测试时间计算的行为可预测,且不受这些限制的影响。 继续测试时间扩展将需要能够进一步外推测试时间计算的方法。如何实现这种外推?可能对预算强制进行改进,例如轮流使用不同的字符串,而不仅仅是“等待”,或者将其与频率惩罚或更高的温度相结合以避免重复循环。未来工作的一个令人兴奋的方向是研究将预算强制应用于通过强化学习训练的推理模型是否能产生更好的外推效果;或者强化学习是否允许在预算强制之外实现新的测试时间扩展方式。我们的工作定义了正确的指标(§3.2)——控制、扩展和性能——以推动未来关于测试时间计算外推的研究和进展。 图 7:使用并行扩展方法进一步扩展。所有指标均基于 AIME24 中的 30 个问题的平均值。REBASE 的平均思考标记未计入奖励模型的额外计算。对于顺序扩展,我们提示模型使用最多(从左到右)32、64、256 和 512 步。对于 REBASE 和多数投票,我们生成 16 个并行轨迹进行汇总。图 7.通过并行扩展方法进一步扩展规模。所有指标均基于 AIME24 中的 30 个问题进行平均。REBASE 的平均思考标记数未计入奖励模型的额外计算量。对于顺序扩展,我们提示模型使用最多(从左到右)32、64、256 和 512 步。对于 REBASE 和多数投票,我们生成 16 条并行轨迹以进行汇总。 |
Figure 7. Scaling further with parallel scaling methods. All met-rics averaged over the 30 questions in AIME24. Average thinking tokens for REBASE do not account for the additional compute from the reward model. For sequential scaling, we prompt the model to use up to (from left to right) 32, 64, 256, and 512 steps. For REBASE and majority voting we generate 16 parallel trajectories to aggregate across.图 7. 进一步通过并行扩展方法进行扩展。所有指标均基于 AIME24 中的 30 个问题进行平均。REBASE 的平均思考标记数未计入奖励模型的额外计算量。对于顺序扩展,我们提示模型使用最多(从左到右)32、64、256 和 512 步。对于 REBASE 和多数投票,我们生成 16 条并行轨迹进行汇总。
Parallel scaling as a solution并行扩展作为一种解决方案
| Parallel scaling offers one solution to the limits of sequential scaling, thus we augment our sequentially scaled model with two methods: (I) Majority voting: After generating k solutions, the final solution is the most frequent one across generations; (II) Tree search via REBASE: We use the REBASE process reward model, which is initialized from LLaMA-34B and further finetuned on a synthetic process reward modeling dataset (Wu et al., 2024b). We then aggregate the solutions generated by REBASE via majority voting. As shown in Figure 7, augmenting our model with REBASE scales better than majority voting, and even sequential scaling in this scenario. However, REBASE requires an additional forward pass at each step for the reward model adding some computation overhead. For sequential scaling, when prompted to use up to 512 steps, for 12 out of the 30 evaluation questions the model generates a response that exceeds the context window leading to a large performance drop. Overall, we find that these parallel scaling methods complement sequential scaling thus they offer an avenue for scaling test-time compute even further; beyond fixed context windows. | 并行扩展为顺序扩展的局限性提供了一种解决方案,因此我们通过两种方法来增强顺序扩展的模型:(I)多数投票:生成 k 个解决方案后,最终的解决方案是各代中最常见的一个;(II)通过 REBASE 进行树搜索:我们使用 REBASE 过程奖励模型,该模型从 LLaMA-34B 初始化,并在合成的过程奖励建模数据集(Wu 等人,2024b)上进一步微调。然后通过多数投票聚合 REBASE 生成的解决方案。如图 7 所示,在这种情况下,通过 REBASE 增强我们的模型比多数投票甚至顺序扩展的扩展性更好。然而,REBASE 在每一步都需要为奖励模型进行额外的前向传递,这会增加一些计算开销。对于顺序扩展,当提示使用多达 512 步时,在 30 个评估问题中有 12 个问题,模型生成的响应超出了上下文窗口,导致性能大幅下降。总体而言,我们发现这些并行扩展方法补充了顺序扩展,因此它们为测试时计算的进一步扩展提供了途径;超越了固定的上下文窗口。 |
Impact Statement影响声明
| Language models with strong reasoning capabilities have the potential to greatly enhance human productivity, from assisting in complex decision-making to driving scientific breakthroughs. However, recent advances in reasoning, such as OpenAI’s o1 and DeepSeek’s r1, lack transparency, limiting broader research progress. Our work aims to push the frontier of reasoning in a fully open manner, fostering innovation and collaboration to accelerate advancements that ultimately benefit society. | 具备强大推理能力的语言模型有可能极大地提高人类生产力,从协助复杂决策到推动科学突破。然而,近期推理方面的进展,如 OpenAI 的 o1 和 DeepSeek 的 r1,缺乏透明度,限制了更广泛的研究进展。我们的工作旨在以完全开放的方式推进推理的前沿,促进创新与合作,以加速最终造福社会的进步。 |



















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











