







LLMs之Inference:ktransformers的简介、安装和使用方法、案例应用(仅需一张4090即可部署671B的DeepSeek-Coder-V3/R1【GPU在线量化为INT4】)之详细攻略
目录
GPT-4/01级别的本地VSCode Copilot:DeepSeek-Coder-V3/R1
LLMs之Inference:基于ktransformers 框架来部署DeepSeek-R1和DeepSeek-V3模型实现更快的本地推理速度(多种优化策略显著提升)之详细攻略
ktransformers 简介
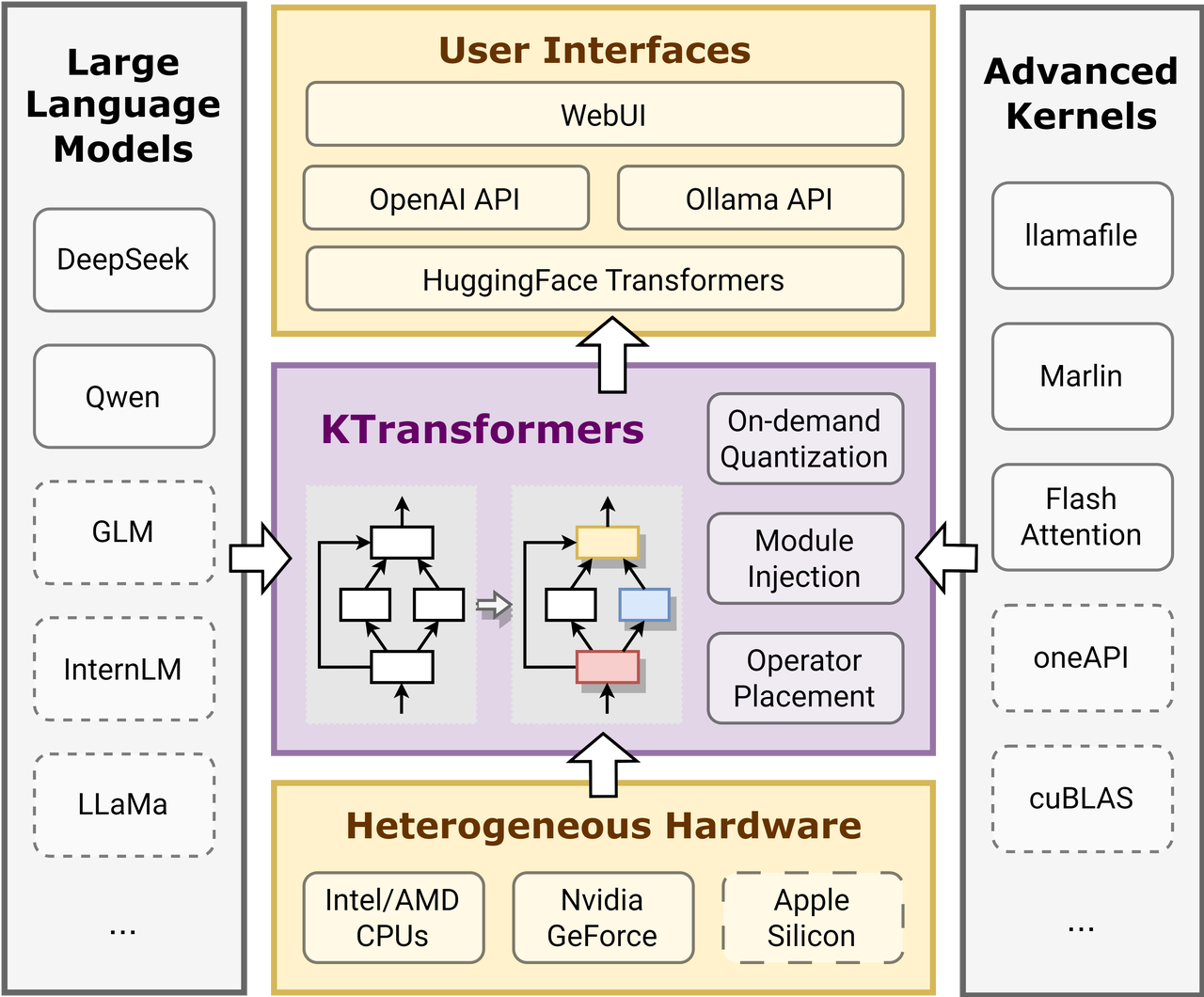
ktransformers (发音为 Quick Transformers) 是一个灵活的 Python 框架,旨在通过高级内核优化和部署/并行策略来增强 Hugging Face Transformers 的使用体验。它提供了一个与 Transformers 兼容的接口、符合 OpenAI 和 Ollama 的 RESTful API,甚至还有一个简化的类似 ChatGPT 的 Web UI。ktransformers 的愿景是成为一个灵活的平台,用于实验创新的 LLM 推理优化,尤其关注受资源限制的本地部署。
官方文档:Introduction - Ktransformers
0、更新
2025 年 2 月 15 日:KTransformers V0.2.1:上下文更长(从 4K 增加到 8K,适用于 24GB 显存)且速度稍快(提升 15%)(最高可达 16 个标记/秒)。
2025 年 2 月 10 日:支持 Deepseek-R1 和 V3 在单(24GB 显存)/多 GPU 和 382G 内存上运行,速度提升可达 3 至 28 倍。有关详细展示和复现教程,请点击此处查看。地址:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md
2024 年 8 月 28 日:将 DeepseekV2 所需的显存从 21G 降至 11G。
2024 年 8 月 15 日:更新有关注入和多 GPU 的详细教程。
2024 年 8 月 14 日:支持将 llamfile 作为线性后端。
2024 年 8 月 12 日:支持多 GPU;支持新模型:mixtral 8*7B 和 8*22B;支持在 GPU 上进行 q2k、q3k、q5k 去量化的操作。
2024 年 8 月 9 日:支持原生 Windows 系统。
1、ktransformers 特点
>> 灵活性和可扩展性:基于模板的注入框架允许轻松替换原始 Torch 模块,并结合多种优化方法。
>> 高级内核优化:集成并利用 GGUF/GGML、Llamafile、Marlin、sglang 和 flashinfer 等先进内核,实现高效的推理。
>> 异构计算支持:支持 GPU/CPU 卸载量化模型,例如高效利用 Llamafile 和 Marlin 内核。
>> 本地部署优化:特别关注受限资源的本地部署优化,例如 24GB VRAM 的桌面设备。
>> 兼容性:提供与 Transformers 兼容的接口,以及与 OpenAI 和 Ollama 兼容的 RESTful API。
>> 简化的 Web UI:提供类似 ChatGPT 的简化 Web UI。
ktransformers 安装和使用方法
1、安装
持续更新中……
相关地址:Deepseek-R1/V3 Show Case - Ktransformers
2、使用方法
ktransformers 的核心是一个用户友好的基于模板的注入框架。研究人员可以使用它轻松地将原始的 torch 模块替换为优化的变体,并简化组合多种优化的过程。
示例用法
用户只需创建一个基于 YAML 的注入模板,并在使用 Transformers 模型之前调用 optimize_and_load_gguf 函数。代码示例如下:
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_rule_path, gguf_path, config)
...
generated = prefill_and_generate(model, tokenizer, input_tensor.cuda(), max_new_tokens=1000)此示例中,AutoModel 首先在 meta 设备上初始化以避免占用任何内存资源。然后,optimize_and_load_gguf 迭代模型的所有子模块,匹配 YAML 规则文件中指定的规则,并将其替换为指定的先进模块。注入后,可以使用原始的 generate 接口,同时也提供兼容的 prefill_and_generate 方法,该方法可以启用 CUDAGraph 等进一步的优化以提高生成速度。
自定义模型
详细的注入和多 GPU 使用教程 (使用 DeepSeek-V2 为例) (链接未提供在给定文本中)。 YAML 模板示例 (替换所有原始线性模块为 Marlin):
- match:
name:"^model\\.layers\\..*$" # 正则表达式
class:torch.nn.Linear # 只匹配名称和类同时匹配的模块
replace:
class:ktransformers.operators.linear.KTransformerLinear # 量化数据类型上的优化内核
device:"cpu" # 初始化时加载此模块的设备
kwargs:
generate_device:"cuda"
generate_linear_type:"QuantizedLinearMarlin"每个规则包含 match 和 replace 两部分。match 指定要替换的模块,replace 指定要注入的模块及其初始化关键字。
3、示例
GPT-4/01级别的本地VSCode Copilot:DeepSeek-Coder-V3/R1

>> 软件版本与硬件配置:GPT-4/01级别的本地VSCode Copilot,运行在24GB VRAM的桌面电脑上。新推出的DeepSeek-Coder-V3/R1,其Q4_K_M版本仅需14GB VRAM和382GB DRAM即可运行。
>> 预填充速度:KTransformers在不同配置下的预填充速度分别为54.21(32核心)→ 74.362(双插座,2×32核心)→ 255.26(优化后的基于AMX的MoE内核,仅限V0.3版本)→ 286.55(选择性使用6个专家,仅限V0.3版本) 与llama.cpp在2×32核心上的10.31 tokens/s相比,实现了高达27.79倍的速度提升。
>> 解码速度:KTransformers在不同配置下的解码速度分别为8.73(32核心)→ 11.26(双插座,2×32核心)→ 13.69(选择性使用6个专家,仅限V0.3版本) 与llama.cpp在2×32核心上的4.51 tokens/s相比,实现了高达3.03倍的速度提升。
>> 开源计划:AMX优化和选择性专家激活功能将在V0.3版本开源。目前这些功能仅在预览版二进制分发中提供。
LLMs之Inference:基于ktransformers 框架来部署DeepSeek-R1和DeepSeek-V3模型实现更快的本地推理速度(多种优化策略显著提升)之详细攻略
LLMs之Inference:基于ktransformers 框架来部署DeepSeek-R1和DeepSeek-V3模型实现更快的本地推理速度(多种优化策略显著提升)之详细攻略-CSDN博客
本地236B的DeepSeek-Coder-V2性能
在仅有 24GB VRAM 的台式机上运行 GPT-4/o1 级别的本地 VSCode Copilot。
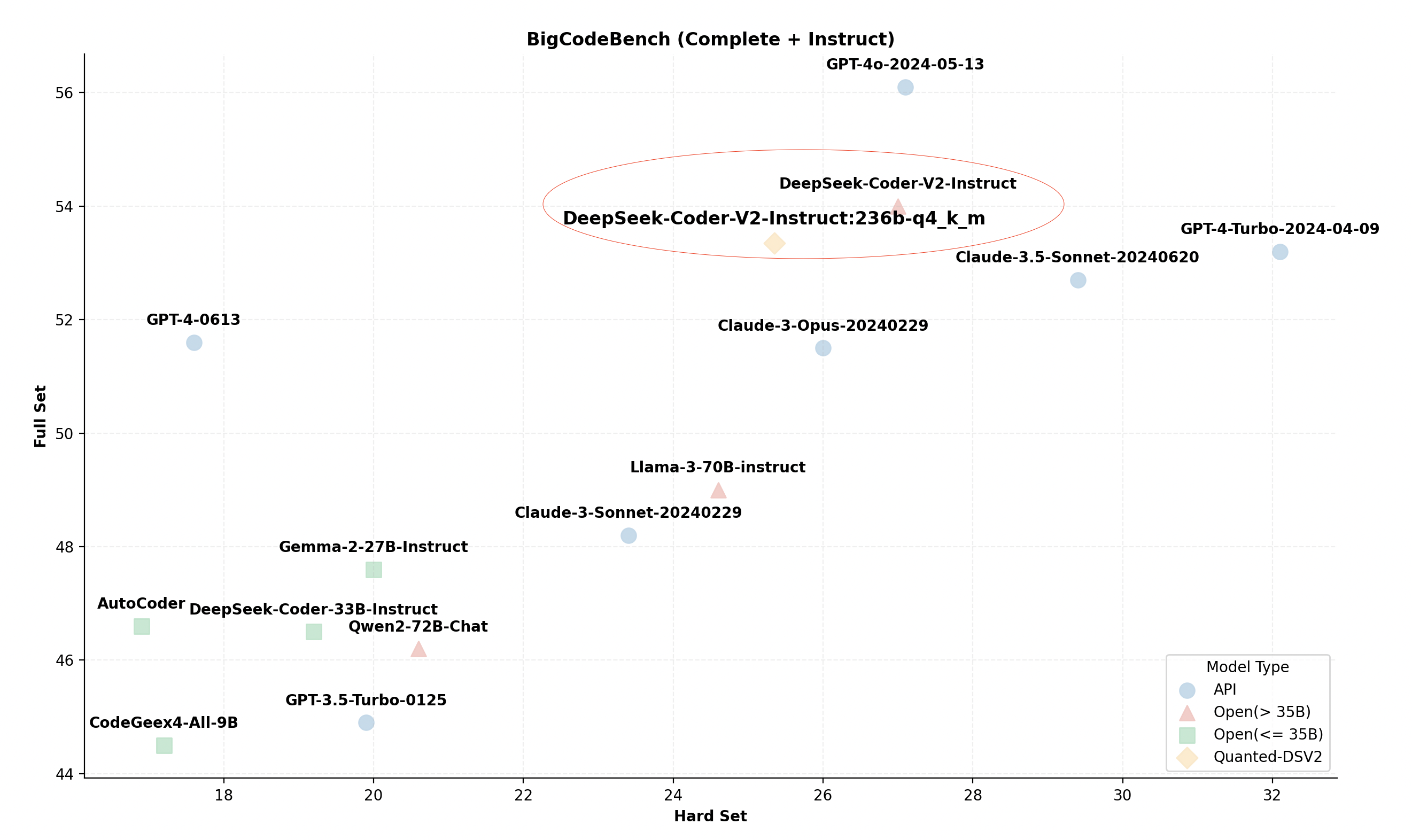
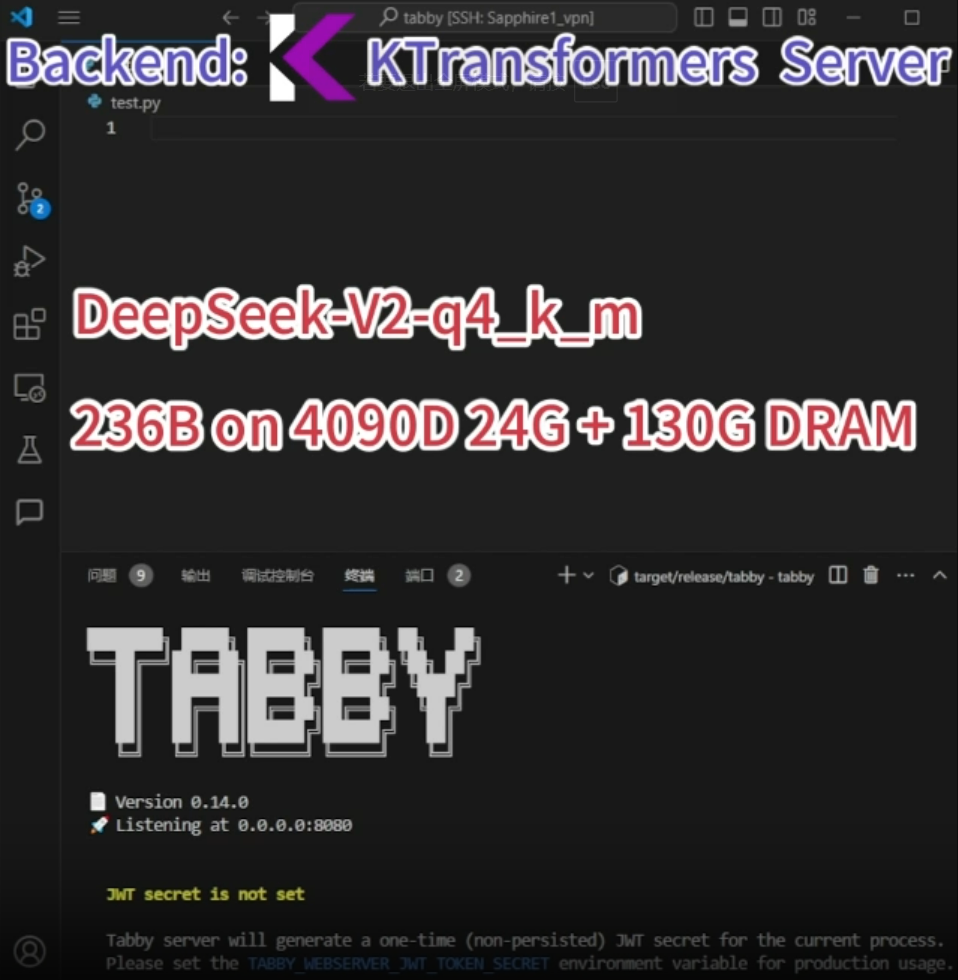
DeepSeek-Coder-V2的Q4_K_M版本仅需21GB VRAM和136GB DRAM,即可在本地桌面机上运行。在BigCodeBench上的表现优于GPT4-0613。
>> DeepSeek-Coder-V2速度:通过MoE卸载和注入高级内核,实现了2K提示预填充速度为126 tokens/s,生成速度为13.6 tokens/s。
>> VSCode集成:DeepSeek-Coder-V2被封装成兼容OpenAI和Ollama的API,可作为Tabby和其他前端的后端无缝集成。
ktransformers的案例应用
持续更新中……



















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











