







LLMs之Llama 4:《The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation》翻译与解读
导读:Meta 发布的 Llama 4 系列模型代表了多模态大型语言模型发展的新阶段。通过采用 MoE 架构、早期融合、MetaP 训练技术等先进技术,以及改进的后训练流程和多层级安全措施,Llama 4 在性能、效率和安全性方面都取得了显著的突破。Llama 4 Scout 和 Llama 4 Maverick 模型的开源发布,将进一步推动多模态 AI 的创新和发展,并为开发者提供强大的工具来构建个性化体验。 Meta 对模型安全性和偏差的关注,也体现了其对负责任 AI 开发的承诺。Llama 4系列大型语言模型,重点关注其多模态能力和在性能、效率、安全性和公平性方面的改进。Meta 的 Llama 4 系列模型代表了大型语言模型技术的一次重大飞跃,它在多模态能力、效率、上下文长度和安全性方面都达到了新的高度。通过结合 MoE 架构、早期融合、知识蒸馏和改进的后训练流程,Llama 4 模型在多个基准测试中取得了优异的成绩,并有效地降低了模型的部署成本。 Meta 对模型安全性和偏差的持续关注,也为负责任的人工智能发展树立了榜样。 Llama 4 的开源策略,有望进一步促进 AI 社区的繁荣和创新。
>> 背景痛点:
● 现有模型的局限性:现有的领先大型语言模型在多模态能力、上下文长度、推理能力、以及应对偏差和恶意攻击方面存在不足。 它们通常在处理复杂推理任务、多语言理解、长文本处理和图像理解等方面表现欠佳,并且容易受到恶意提示攻击(Jailbreaks)和偏差的影响。 此外,高性能模型通常需要巨大的计算资源,部署成本高昂。
● 对开放性和个性化体验的需求:随着人工智能在日常生活中应用的日益广泛,人们对开放、易于访问且能够提供个性化体验的领先模型和系统有着迫切的需求。
>> 具体的解决方案:Meta 推出了 Llama 4 系列模型,旨在解决上述痛点。该系列包含三个模型:
● Llama 4 Behemoth:一个 2880 亿活跃参数的教师模型,用于知识蒸馏。其性能在多个 STEM 基准测试中超过了 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。
● Llama 4 Maverick:一个 170 亿活跃参数(4000 亿总参数)的模型,包含 128 个专家,在多模态能力、推理、编码和多语言能力方面表现出色,性能优于 GPT-4o 和 Gemini 2.0 Flash,并且与 DeepSeek v3 具有竞争力,同时具有更低的成本。
● Llama 4 Scout:一个 170 亿活跃参数(1090 亿总参数)的模型,包含 16 个专家,具有业界领先的 1000 万 token 的上下文窗口,在多模态能力、编码、推理和图像基准测试中表现优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1,并优于所有之前的 Llama 模型。
>> 核心思路步骤:Llama 4 模型的开发过程主要包括以下步骤:
● 预训练:使用混合专家 (MoE) 架构、早期融合 (early fusion) 技术、MetaP 超参数优化技术以及 FP8 精度训练,在超过 30 万亿 token 的多语言、多模态数据上进行预训练。 预训练中使用了高达 48 张图片进行视觉理解训练。
● 知识蒸馏:使用 Llama 4 Behemoth 作为教师模型,对 Llama 4 Maverick 和 Llama 4 Scout 进行知识蒸馏。 开发了一种新的蒸馏损失函数,动态地调整软目标和硬目标的权重。
● 后训练:采用轻量级监督微调 (SFT) 、在线强化学习 (RL) 和轻量级直接偏好优化 (DPO) 的三阶段后训练流程。 其中,RL 阶段使用了连续在线 RL 策略和自适应数据过滤,以提高模型的推理和对话能力。 为了避免 SFT 和 DPO 过度约束模型,对数据进行了筛选,只保留难度较高的样本。
● 安全性和偏差缓解:在模型开发的各个阶段都集成了安全措施,包括数据过滤、安全数据、Llama Guard、Prompt Guard 和 CyberSecEval 等工具,并通过对抗性测试(包括 GOAT 技术)来识别和减轻潜在风险,并努力减少模型中的偏差。
>> 优势:
● 多模态能力:Llama 4 模型是原生多模态模型,能够同时处理文本和图像数据。
● 高效性:Llama 4 Scout 能够运行在单个 H100 GPU 上,Llama 4 Maverick 能够运行在单个 H100 DGX 主机上,具有极高的效率和较低的成本。
● 长上下文窗口:Llama 4 Scout 具有 1000 万 token 的上下文窗口,能够处理超长文本。
● 高性能:Llama 4 模型在多个基准测试中取得了最先进的成果,在推理、编码、多语言和图像理解等方面表现出色。
● 安全性:Llama 4 模型集成了多种安全措施,以防止恶意攻击和减轻潜在风险。
● 减少偏差:Llama 4 模型在减少偏差方面取得了显著进展,其表现与 Grok 相当。
>> 结论和观点:
● Llama 4 系列模型是 Meta 在大型语言模型领域的重要进展,标志着原生多模态 AI 创新进入了一个新的时代。
● 开放性是推动创新的关键,Meta 致力于将 Llama 模型开源,以促进 AI 社区的共同发展。
● Llama 4 模型的开发过程体现了 Meta 对模型性能、效率、安全性以及公平性的重视。
● Llama 4 模型将为开发者提供强大的工具,以构建更个性化、更安全和更有用的 AI 应用。
目录
《The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation》翻译与解读
Llama 4 长上下文检索能力:文本与视频的“Needle-in-a-Haystack”测试
《The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation》翻译与解读
| 地址 | 文章地址:https://ai.meta.com/blog/llama-4-multimodal-intelligence/ |
| 时间 | 2025年4月5日 |
| 作者 | Meta 团队 |
一、引言:Llama 4 的发布和主要特点
Meta 发布了 Llama 4 系列模型,这些模型在多模态能力、上下文窗口大小、性能和效率方面都达到了新的高度,并强调了开源的理念。
-
主要发布内容: Meta 发布了 Llama 4 系列的三个新模型:Llama 4 Scout、Llama 4 Maverick 和 Llama 4 Behemoth。其中,Llama 4 Scout 和 Llama 4 Maverick 是首批公开发布的原生多模态模型,Llama 4 Behemoth 作为教师模型,用于训练 Llama 4 Scout 和 Llama 4 Maverick。
-
Llama 4 Scout 的特点: 这是一个 170 亿活跃参数的模型,包含 16 个专家,能够运行在单个 NVIDIA H100 GPU 上(使用 Int4 量化)。它具有业界领先的 1000 万 token 的上下文窗口,在广泛的基准测试中表现优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
-
Llama 4 Maverick 的特点: 这是一个 170 亿活跃参数的模型,包含 128 个专家,在广泛的基准测试中优于 GPT-4o 和 Gemini 2.0 Flash,在推理和编码方面与 DeepSeek v3 的结果相当,但活跃参数不到 DeepSeek v3 的一半。它具有最佳的性能成本比,其实验性聊天版本在 LMArena 上获得了 1417 的 ELO 分数。
-
Llama 4 Behemoth 的特点: 这是一个 2880 亿活跃参数的模型,包含 16 个专家,是目前 Meta 最强大的 LLM 之一,在多个 STEM 基准测试中优于 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.0 Pro。该模型仍在训练中。
二、Llama 4 的开发方法:预训练阶段
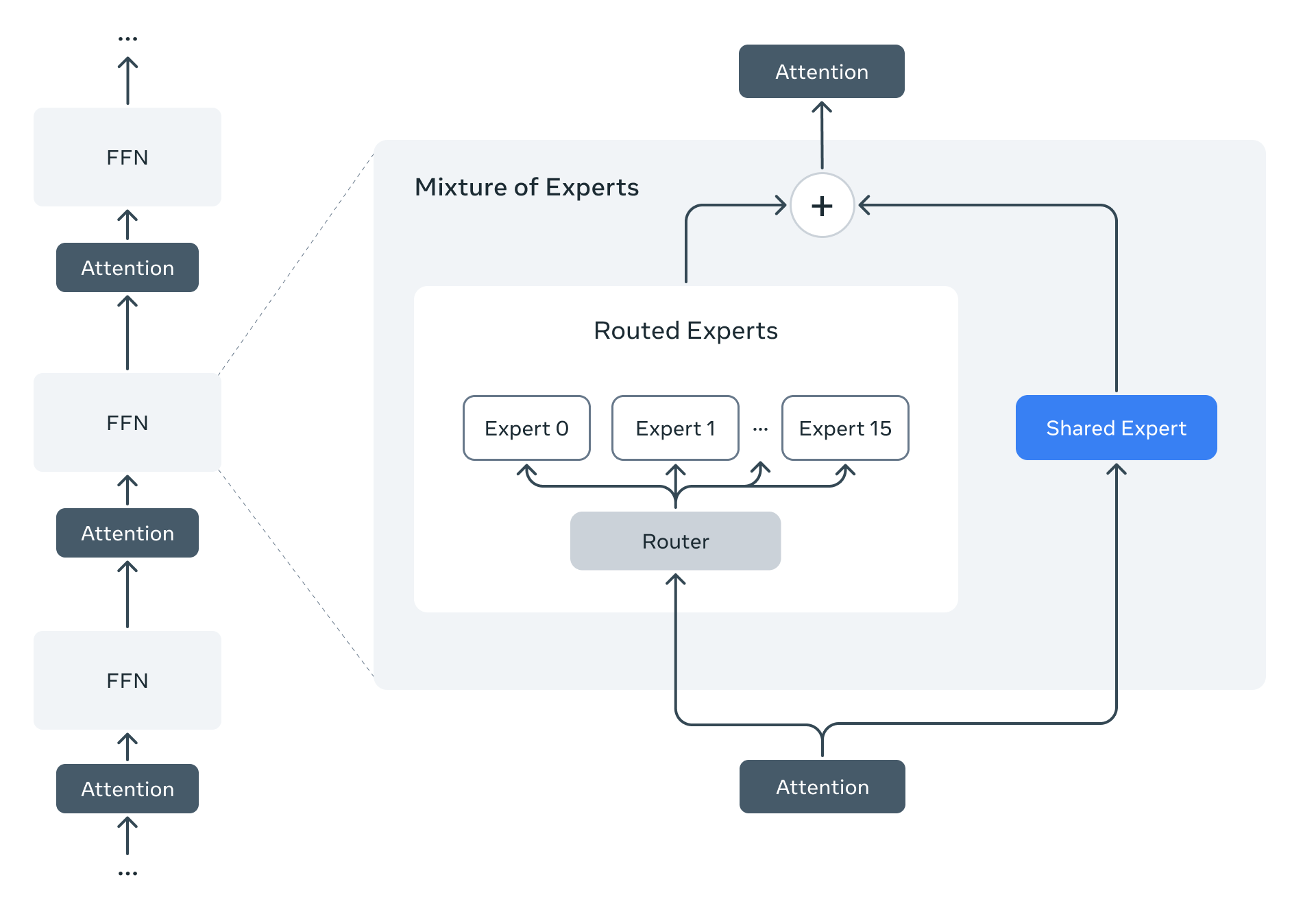
Llama 4 的预训练阶段使用了多种先进技术,包括 MoE 架构、早期融合、MetaP 训练技术和 FP8 精度训练,以提高模型的质量和效率,并支持多语言和多模态能力。
-
MoE 架构: Llama 4 是 Meta 首个使用混合专家 (MoE) 架构的模型。MoE 架构提高了训练和推理效率,在固定的训练 FLOPs 预算下,能够提供比密集模型更高的质量。Llama 4 Maverick 有 170 亿活跃参数和 4000 亿总参数,它交替使用密集层和 MoE 层,每个 token 会被发送到共享专家和 128 个路由专家中的一个。
-
原生多模态: Llama 4 模型采用早期融合 (early fusion) 的方法,将文本和视觉 token 无缝集成到统一的模型主干中,允许使用大量未标记的文本、图像和视频数据进行联合预训练。视觉编码器基于 MetaCLIP,但与冻结的 Llama 模型一起单独训练,以更好地适应 LLM。
-
MetaP 训练技术: Meta 开发了一种名为 MetaP 的新训练技术,用于可靠地设置关键模型超参数,例如每层学习率和初始化比例。该技术使超参数能够很好地迁移到不同的批量大小、模型宽度、深度和训练 token 数值。
-
多语言支持: Llama 4 在 200 多种语言上进行预训练,其中 100 多种语言的 token 数超过 10 亿,多语言 token 总量是 Llama 3 的 10 倍以上。
-
高效训练: 使用 FP8 精度进行训练,在不牺牲质量的情况下确保高模型 FLOPs 利用率。Llama 4 Behemoth 使用 FP8 精度和 32000 个 GPU 进行训练,实现了 390 TFLOPs/GPU 的计算能力。训练数据超过 30 万亿 token,是 Llama 3 的两倍多。
三、Llama 4 的开发方法:后训练阶段
Llama 4 的后训练阶段采用了一种改进的流程,包括轻量级 SFT、在线 RL 和轻量级 DPO,并通过数据过滤和持续在线 RL 策略来提高模型性能和效率,最终训练出了性能优异的多模态模型。
-
模型选择: Llama 4 系列包含大小不同的模型,以适应不同的用例和开发人员需求。Llama 4 Maverick 是用于通用助手和聊天用例的产品主力模型,Llama 4 Scout 则具有业界领先的 1000 万 token 的上下文窗口。
-
后训练流程: Llama 4 的后训练流程采用轻量级监督微调 (SFT) > 在线强化学习 (RL) > 轻量级直接偏好优化 (DPO) 的方法。为了避免 SFT 和 DPO 过度约束模型,Meta 使用 Llama 模型作为评判来去除超过 50% 的简单数据,并在剩余的较难的数据集上进行轻量级 SFT。在线 RL 阶段则精心挑选较难的提示,并采用持续在线 RL 策略,交替进行模型训练和数据过滤,最终实现了模型智能和对话能力之间的良好平衡。
-
Llama 4 Maverick 的性能: 这是一个 170 亿活跃参数、128 个专家和 4000 亿总参数的模型,在编码、推理、多语言、长上下文和图像基准测试中超过了 GPT-4o 和 Gemini 2.0,并且在编码和推理方面与更大的 DeepSeek v3.1 具有竞争力。
-
Llama 4 Scout 的性能: 这是一个 170 亿活跃参数、16 个专家和 1090 亿总参数的模型,其上下文窗口大小为 1000 万 token,在图像接地 (image grounding) 方面表现出色,能够将用户提示与相关的视觉概念对齐。
Llama 4 Maverick 多模态与推理性能基准评估
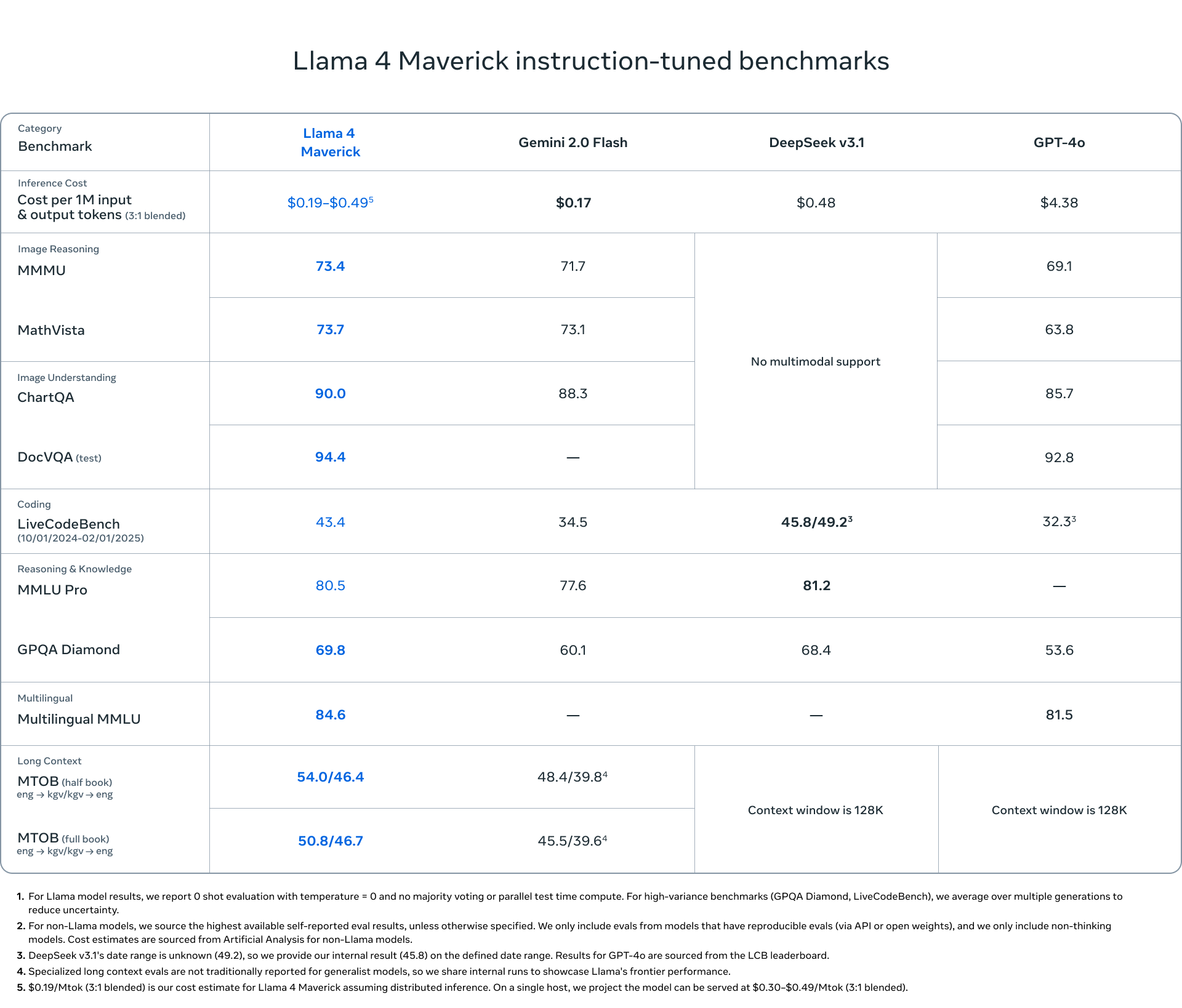
这张图展示了多个大模型(Llama 4 Maverick、Gemini 2.0 Flash、DeepSeek v3.1 和 GPT-4o)在不同基准测试上的表现,涵盖以下几个维度:
-
成本:Llama 4 Maverick 的推理成本最低($0.19-$0.49/M tokens),远低于 GPT-4o 的 $4.38。
-
图像推理(MMMU & MathVista):Llama 4 Maverick 在这两项中表现最佳。
-
图像理解(ChartQA & DocVQA):依然保持领先。
-
编程能力(LiveCodeBench):略逊于 DeepSeek,但远超 GPT-4o。
-
知识与推理(MMLU Pro & GPQA Diamond):领先于 Gemini 2.0 Flash 和 GPT-4o。
-
多语言能力:在 Multilingual MMLU 上表现出色。
-
长上下文能力(MTOB):支持最长达 1M tokens 的上下文窗口,并在翻译任务中表现良好。
结论:Llama 4 Maverick 综合性能优秀,尤其在图像理解和成本效率方面表现突出。
Llama 4 长上下文检索能力:文本与视频的“Needle-in-a-Haystack”测试
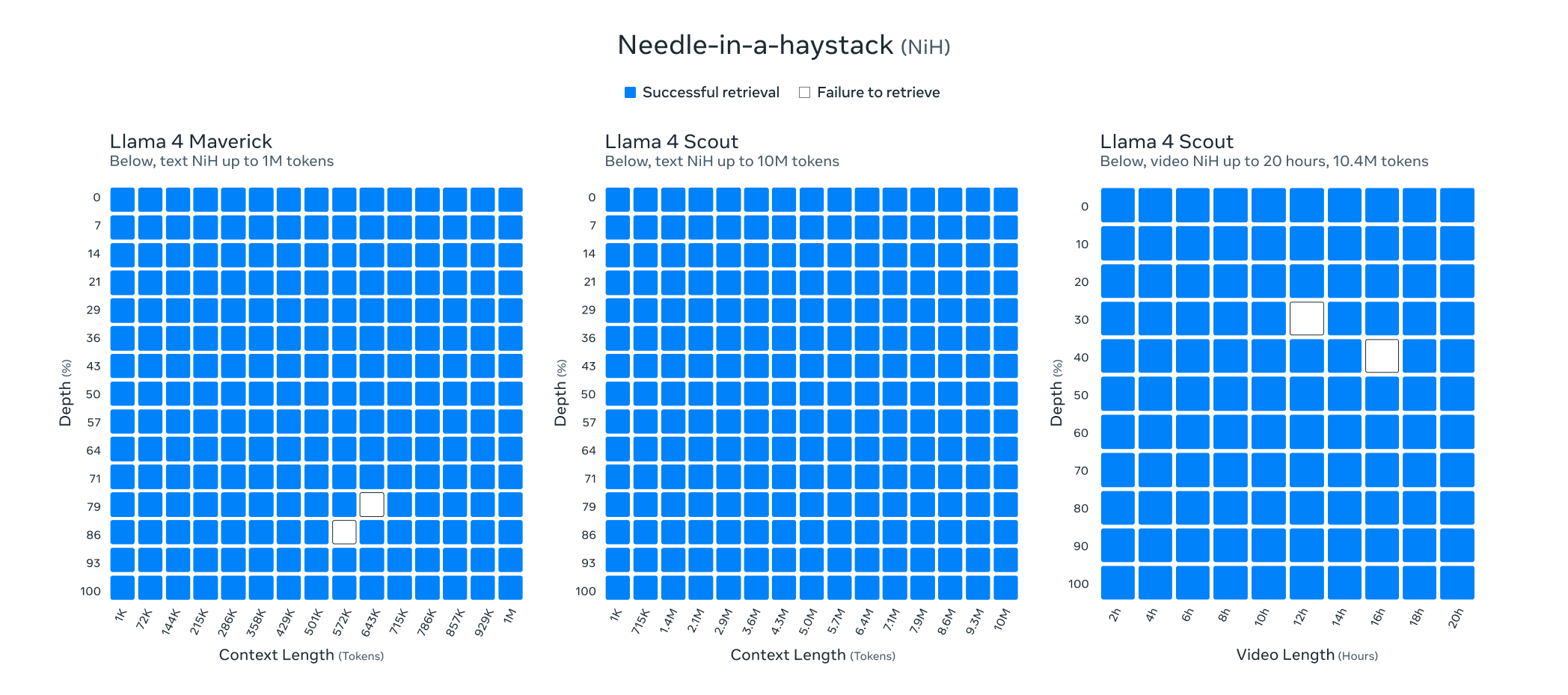
这组图是关于模型在长上下文中检索信息(Needle-in-a-Haystack)的能力:
-
Llama 4 Maverick(左图):在 1M tokens 的文本上下文中几乎可以稳定地准确检索到目标内容,仅在接近 1M 时出现极少失误。
-
Llama 4 Scout(中图):在超长上下文(达 10M tokens)中依旧保持100%检索成功率。
-
Llama 4 Scout 视频(右图):在高达20小时的视频内容(编码为10.4M tokens)中表现出高检索能力,仅在部分时段(如14h 和 16h)出现个别失败。
结论:Llama 4 在处理超长文本和视频上下文方面具备极强的信息定位与检索能力。
Llama 4 在代码上的理解与生成表现:负对数似然分析
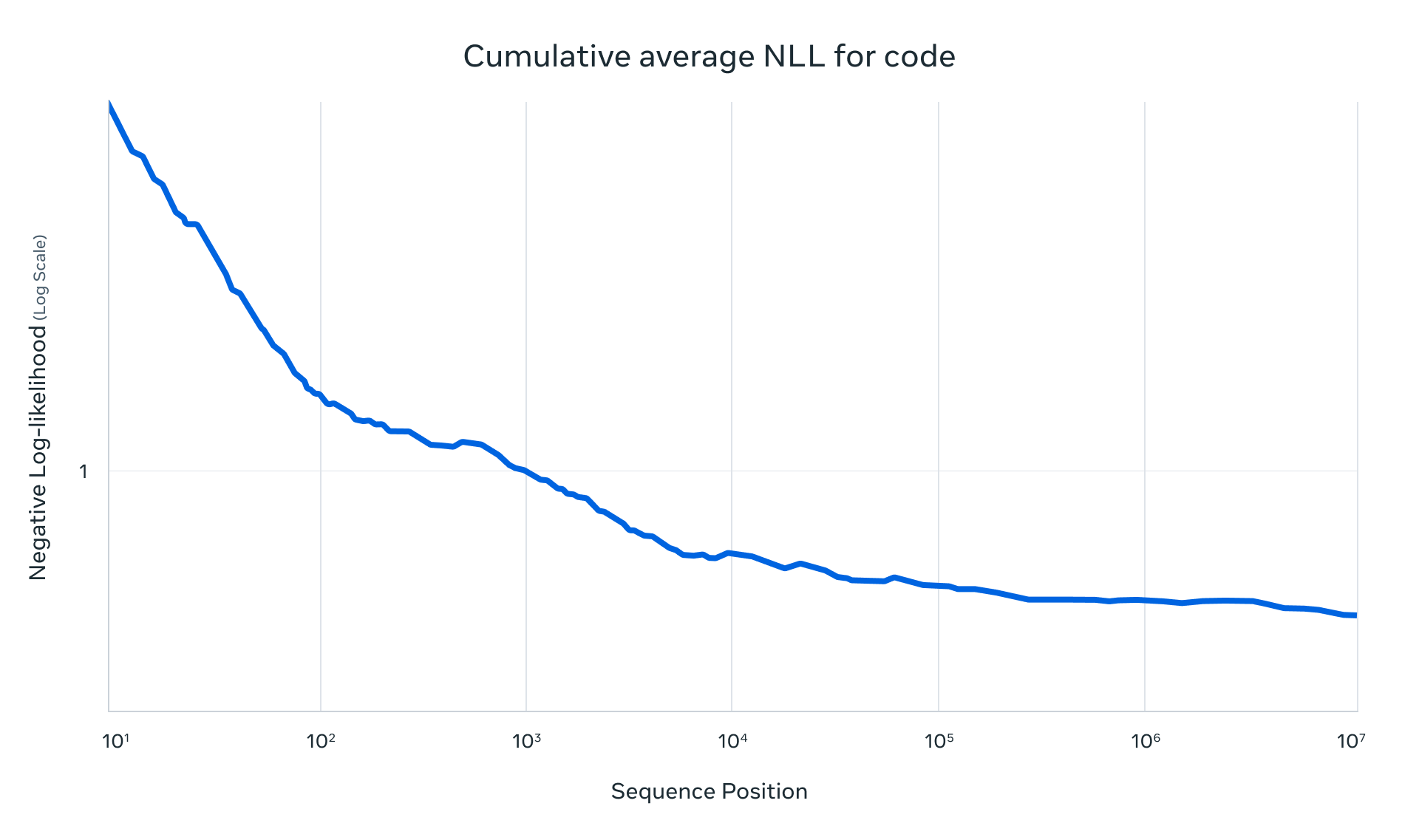
这张图展示了模型对代码数据的累积平均负对数似然(Negative Log-Likelihood, NLL)随序列位置的变化,纵轴为对数坐标:
-
在序列的初期(前几十个 token)NLL 较高,说明预测不确定性大;
-
随着上下文变长,模型对后续 token 的预测更准确,NLL 显著降低并趋于稳定;
-
到了百万级 token,NLL 维持在非常低的水平,说明模型能很好地理解和生成长代码片段。
结论:Llama 4 在代码理解和长序列生成上拥有强大的上下文保持能力。
Llama 4 Scout 多任务基准测试比较
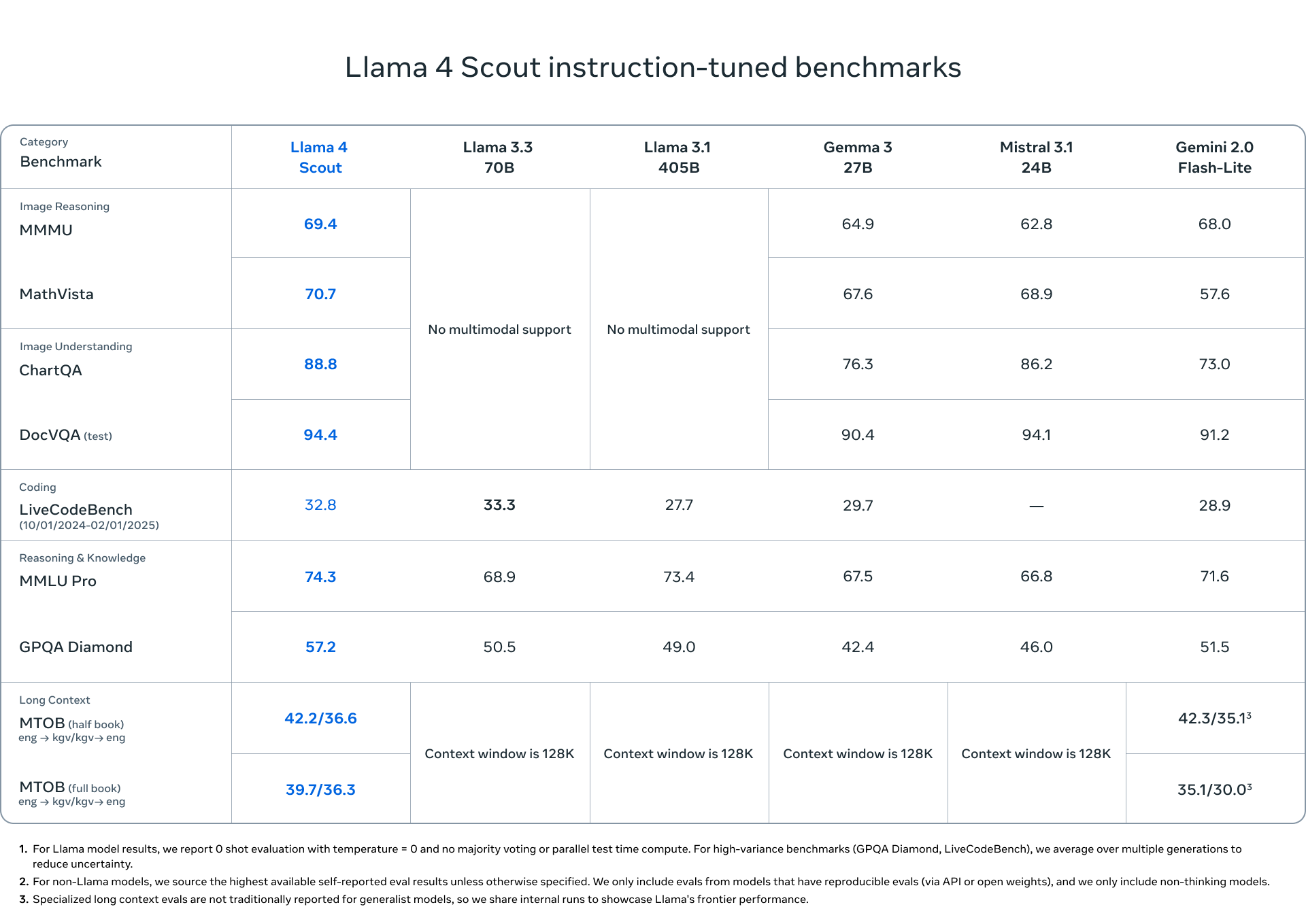
- 总体概览:图片展示了多个语言模型(如 Llama 4 Scout、Llama 3.3 70B、Gemma 3 27B 等)在不同基准测试中的性能比较,涵盖了图像推理、图像理解、代码生成、推理与知识、以及长上下文处理等任务。
- 性能亮点:
- 图像推理:Llama 4 Scout 在 MMMU 和 MathVista 中分别得分 69.4 和 70.7,高于大多数对比模型。
- 图像理解:在 ChartQA 和 DocVQA 测试中,Llama 4 Scout 得分分别为 88.8 和 94.4,领先其他模型。
- 代码生成:Llama 4 Scout 的 LiveCodeBench 表现为 32.8,低于部分对比模型(如 Llama 3.3 70B 的 33.3)。
- 推理与知识:MMLU Pro 和 GPQA Diamond 测试中,Llama 4 Scout 得分为 74.3 和 57.2,在 GPQA Diamond 上表现略逊色。
- 长上下文处理:Llama 4 Scout 在半本书(42.2/36.6)和整本书(39.7/36.3)的 MTLOB 测试中具备相对较强的能力,但其他模型的上下文窗口固定为 128K。
Llama 4 Behemoth 基准性能对比
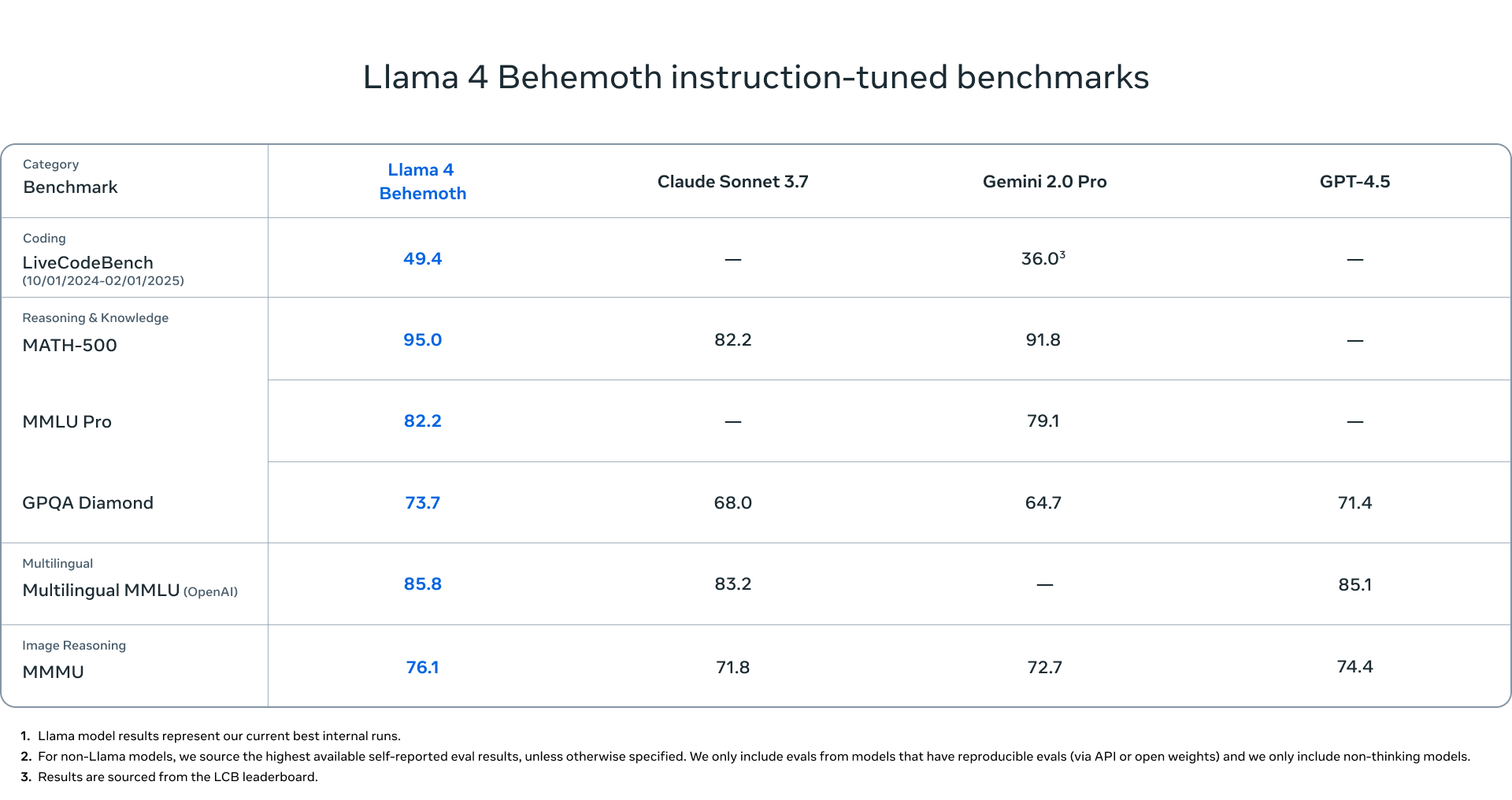
图片展示了 Llama 4 Behemoth 和其他模型(如 Claude Sonnet 3.7、Gemini 2.0 Pro 等)在多任务基准测试中的性能对比,涵盖代码生成、推理与知识、多语言能力和图像推理任务。
- 性能亮点:
- 代码生成:Llama 4 Behemoth 在 LiveCodeBench 测试中得分 49.4,显著优于 Gemini 2.0 Pro(36.0)。
- 推理与知识:
- 在 MATH-500 测试中,Llama 4 Behemoth 以 95.0 的高分领先。
- MMLU Pro 和 GPQA Diamond 中,得分为 82.2 和 73.7,均优于大部分对比模型。
- 多语言能力:在 Multilingual MMLU 测试中,Llama 4 Behemoth 得分 85.8,优于 Claude Sonnet 3.7 和 Gemini 2.0 Pro。
- 图像推理:在 MMMU 测试中,得分 76.1,同样高于其他对比模型。
四、Llama 4 的安全性和保护措施
Meta 采取了多层级安全措施和对抗性测试来确保 Llama 4 模型的安全性和可靠性,并致力于减少模型中的偏差。
-
多层级安全措施: Llama 4 集成了从预训练到后训练到可调系统级缓解措施的多层级安全措施,以保护模型免受恶意攻击。
-
开源安全工具: Meta 开源了 Llama Guard、Prompt Guard 和 CyberSecEval 等安全工具,帮助开发者检测和防御潜在的恶意输入和输出。
-
对抗性测试: Meta 对模型进行了广泛的对抗性测试,包括使用自动化和手动测试以及 Generative Offensive Agent Testing (GOAT) 技术来模拟中等技能的对抗性行为者,以发现并解决潜在的风险。
-
减少模型偏差: Meta 致力于减少 Llama 模型中的偏差,并使其能够理解和表达有争议话题的双方观点,Llama 4 在减少偏差方面取得了显著进展。
五、Llama 生态系统和未来展望
Meta 强调了 Llama 生态系统的完整性和开放性,并展望了未来的发展方向。
-
Llama 生态系统: Meta 致力于构建完整的 Llama 生态系统,包括模型、产品集成和开发者社区。
-
未来计划: Meta 将继续研究和开发 Llama 模型和产品,并将在 LlamaCon 上分享更多信息。



















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











