









TF之GNMT:Neural Machine Translation 基于神经网络机器翻译(seq2seq,RNN→attention注意力) 的简介、在TensorFlow中构建自己的神经机器翻译系统介绍
目录
TF之NMT:Neural Machine Translation 神经机器翻译(seq2seq+注意力机制) 的简介、安装、使用方法之详细攻略
Neural Machine Translation 基于神经网络机器翻译(seq2seq,RNN→attention注意力) 的简介、在TensorFlow中构建自己的神经机器翻译系统介绍
2017年7月12日,在TensorFlow中构建自己的神经机器翻译系统
TF之NMT:Neural Machine Translation 神经机器翻译(seq2seq+注意力机制) 的简介、安装、使用方法之详细攻略
相关文章
TF之NMT:Neural Machine Translation 神经机器翻译(seq2seq+注意力机制) 的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/104584843
TF之GNMT:Neural Machine Translation 基于神经网络机器翻译(seq2seq,RNN→attention注意力) 的简介、在TensorFlow中构建自己的神经机器翻译系统介绍
https://yunyaniu.blog.csdn.net/article/details/83041972
Neural Machine Translation 基于神经网络机器翻译(seq2seq,RNN→attention注意力) 的简介、在TensorFlow中构建自己的神经机器翻译系统介绍
2016年9月27日神经网络机器翻译,在生产规模上的应用
原文地址:https://blog.research.google/2016/09/a-neural-network-for-machine.html
作者:Quoc V. Le和Mike Schuster,Google Brain团队研究科学家
十年前,我们宣布推出Google翻译,并采用基于短语的机器翻译作为该服务背后的关键算法。自那时以来,机器智能的快速进展改进了我们的语音识别和图像识别能力,但提高机器翻译仍然是一个具有挑战性的目标。
今天,我们宣布了Google神经机器翻译系统(GNMT),该系统利用最先进的训练技术,实现了迄今为止机器翻译质量的最大改进。我们完整的研究结果在我们今天发布的新技术报告中描述:“Google的神经机器翻译系统:弥合人类翻译与机器翻译之间的差距”[1]。
几年前,我们开始使用循环神经网络(RNN)直接学习输入序列(例如一种语言中的句子)到输出序列(同一句子在另一种语言中的句子)的映射[2]。而基于短语的机器翻译(PBMT)将输入句子分解为单词和短语,独立翻译,神经机器翻译(NMT)将整个输入句子视为一个翻译单元。这种方法的优势在于,与以前的基于短语的翻译系统相比,它需要更少的工程设计选择。当它首次推出时,NMT在规模较小的公共基准数据集上与现有的基于短语的翻译系统具有相等的准确性。
自那时以来,研究人员提出了许多技术来改进NMT,包括通过模仿外部对齐模型来处理稀有单词[3],使用注意力来对齐输入词和输出词[4],以及将单词分解成较小的单元以处理稀有单词[5,6]。尽管有这些改进,NMT还不够快或准确,无法用于生产系统,如Google翻译。我们的新论文[1]描述了我们如何克服许多挑战,使NMT在非常大的数据集上运行,并构建了一个足够快速和准确的系统,为Google的用户和服务提供更好的翻译。
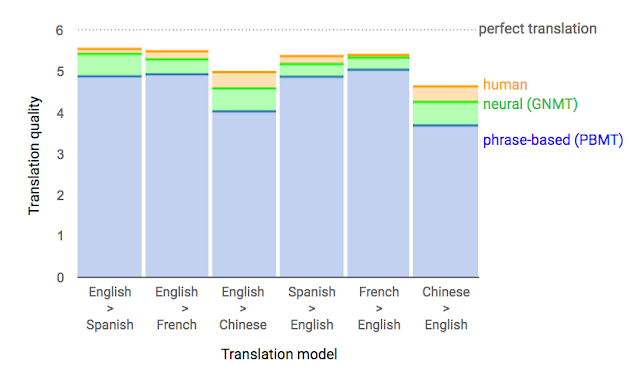
来自并行评估的数据,其中人类评分者比较给定源句子的翻译质量。得分范围从0到6,0表示“完全没有意义的翻译”,6表示“完美的翻译”。
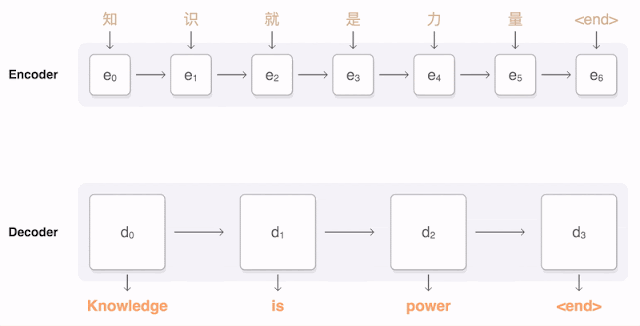
以下可视化展示了GNMT翻译一句中文句子到英文的过程。首先,网络将中文单词编码为一个向量列表,其中每个向量表示到目前为止读取的所有单词的含义(“编码器”)。一旦整个句子被读取,解码器开始生成英文句子(“解码器”),一次生成一个单词。为了在每个步骤生成翻译的单词,解码器关注的是对生成英文单词最相关的编码中文向量的加权分布(“注意力”;蓝色链接的透明度表示解码器关注编码单词的程度)。
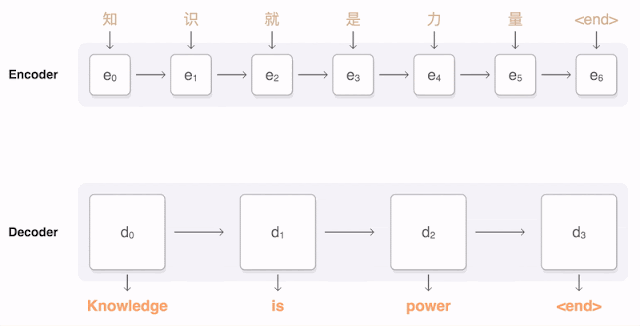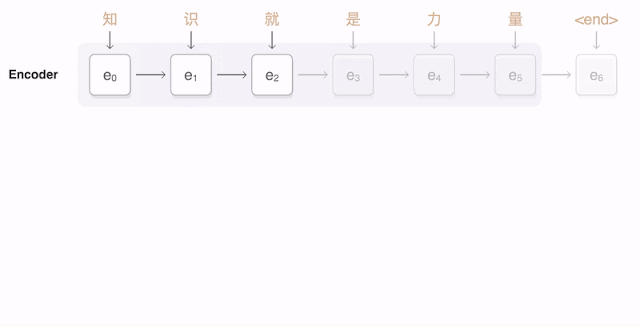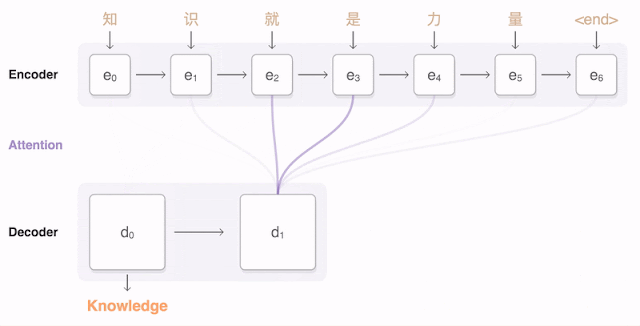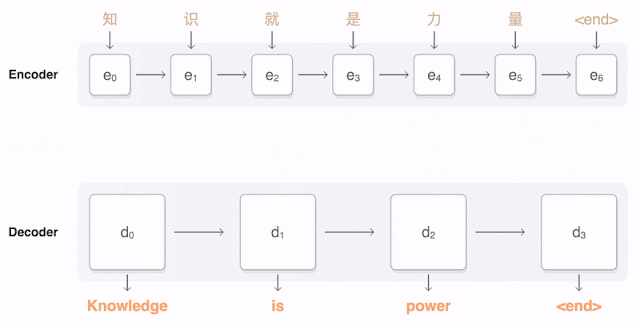
GNMT系统使用人类评分的并排比较作为度量标准,GNMT系统生成的翻译与先前基于短语的生产系统相比,质量大大提高。在从Wikipedia和新闻网站的抽样句子上,通过双语人类评分器,GNMT在几个主要语言对上将翻译错误减少了55%-85%。

由我们的系统为从新闻网站抽样的输入句子产生的翻译示例。点击此处查看从新闻网站和书籍中随机抽样的输入句子的更多翻译示例。
除了今天发布这篇研究论文外,我们还宣布在一个难以处理的语言对上推出GNMT:中文到英文。Google翻译移动和Web应用程序现在现在100%使用GNMT进行从中文到英文的所有机器翻译,每天约有1800万次翻译。GNMT的生产部署得以实现,得益于我们公开提供的机器学习工具包TensorFlow和我们的张量处理单元(TPU),这提供了足够的计算能力来部署这些强大的GNMT模型,同时满足Google翻译产品严格的延迟要求。从中文翻译到英文是Google翻译支持的10,000多种语言对之一,我们将努力在未来几个月内将GNMT推广到更多语言对。
机器翻译绝非已解决的问题。GNMT仍然可能产生人类翻译员永远不会犯的重大错误,比如遗漏单词、错误翻译专有名称或罕见术语,以及独立翻译句子而不考虑段落或页面的上下文。我们仍然有很多工作要做,以更好地为用户服务。然而,GNMT代表了一个重要的里程碑。我们要感谢过去几年中为这个研究方向做出贡献的许多研究人员和工程师,无论是在Google内部还是更广泛的社区。
致谢:
我们感谢Google Brain团队和Google翻译团队成员对该项目的帮助。我们感谢Nikhil Thorat和Big Picture团队提供的可视化。
References:
[1] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016.
[2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Advances in Neural Information Processing Systems, 2014.
[3] Addressing the rare word problem in neural machine translation, Minh-Thang Luong, Ilya Sutskever, Quoc V. Le, Oriol Vinyals, and Wojciech Zaremba. Proceedings of the 53th Annual Meeting of the Association for Computational Linguistics, 2015.
[4] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. International Conference on Learning Representations, 2015.
[5] Japanese and Korean voice search, Mike Schuster, and Kaisuke Nakajima. IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
[6] Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich, Barry Haddow, Alexandra Birch. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
2017年7月12日,在TensorFlow中构建自己的神经机器翻译系统
原文地址:https://blog.research.google/2017/07/building-your-own-neural-machine.html
作者:Thang Luong(研究科学家)和Eugene Brevdo(高级软件工程师),Google Brain团队
机器翻译——自动在语言之间进行翻译的任务——是机器学习领域中最活跃的研究领域之一。在许多机器翻译方法中,序列到序列("seq2seq")模型[1, 2]最近取得了巨大成功,并已成为大多数商业翻译系统(如Google翻译)中的事实标准,这要归功于它能够使用深度神经网络捕捉句子含义的能力。然而,虽然有大量关于seq2seq模型(如OpenNMT或tf-seq2seq)的材料,但缺乏教授人们如何轻松构建高质量翻译系统的资料,既包括知识又包括技能。
今天,我们很高兴宣布一个新的TensorFlow神经机器翻译(NMT)教程,该教程让读者完全了解seq2seq模型,并演示如何从头开始构建具有竞争力的翻译模型。该教程旨在使过程尽可能简单,从NMT的一些背景知识开始,然后深入到代码细节,构建一个基本系统。然后,它深入探讨了注意力机制[3, 4],这是使NMT系统能够处理长句子的关键组成部分。最后,该教程提供了如何在多个GPU上训练的复制Google的NMT(GNMT)系统[5]中的关键特性的详细信息。
教程还包含详细的基准测试结果,用户可以自行复制。我们的模型提供了与GNMT结果[5]相媲美的强大的开源基线。我们在流行的WMT'14英语-德语翻译任务上实现了24.4 BLEU分数。其他基准测试结果(英语-越南语,德语-英语)可以在教程中找到。
此外,该教程展示了全动态seq2seq API(与TensorFlow 1.2一起发布),旨在使构建seq2seq模型变得简洁而容易:
>> 使用tf.contrib.data中的新输入流水线轻松读取和预处理动态大小的输入序列。
>> 使用填充批处理和序列长度分桶来提高训练和推断速度。
>> 使用流行的架构和训练计划训练seq2seq模型,包括几种类型的注意力和计划采样。
>> 在seq2seq模型中使用图内波束搜索进行推断。
>> 优化多GPU设置的seq2seq模型。
我们希望这将帮助研究社区创造和尝试许多新的NMT模型。要开始您自己的研究,请查看GitHub上的教程!
核心贡献者
Thang Luong,Eugene Brevdo和Rui Zhao。
致谢
我们特别感谢我们在NMT项目中的合作伙伴Rui Zhao。没有他不懈的努力,这个教程就不可能存在。额外的感谢Denny Britz,Anna Goldie,Derek Murray和Cinjon Resnick为将新功能引入TensorFlow和seq2seq库所做的工作。最后,我们感谢Lukasz Kaiser对seq2seq代码库的最初帮助;Quoc Le对复制GNMT的建议;Yonghui Wu和Zhifeng Chen提供GNMT系统的详细信息;以及Google Brain团队对他们的支持和反馈!
References
[1] Sequence to sequence learning with neural networks, Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. NIPS, 2014.
[2] Learning phrase representations using RNN encoder-decoder for statistical machine translation, Kyunghyun Cho, Bart Van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. EMNLP 2014.
[3] Neural machine translation by jointly learning to align and translate, Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. ICLR, 2015.
[4] Effective approaches to attention-based neural machine translation, Minh-Thang Luong, Hieu Pham, and Christopher D Manning. EMNLP, 2015.
[5] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016.



















 865
865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











