







介绍
场景流(Scene Flow)可以理解为空间中场景的三维运动场,即空间中每一点的位置信息和其相对于摄像头的移动。场景流估计的一种方式是光流估计和深度估计的结合。光流是一种二维运动场,是空间中每一点沿摄像头平面的运动状态,深度信息表达是空间中每一点到摄像头的距离,其变化量是物体沿垂直摄像头方向的变化。光流和深度变化可以理解为对三维运动场的一种分解。对光流和深度估计的实现可以使我们对空间中任意点的三维运动状态都掌握。同时,场景流的潜在应用很多,可以补充和改进视觉测距和SLAM算法,上述算法一般是假定在刚性或准刚性环境中。额外需要注意的是,场景流只关注深度变化量,不关注深度的绝对值。
深度估计
深度估计是指获取图像上每一点距离测量平面的深度信息,在无人驾驶中可以用于障碍物的识别和定位。由于它能够获取障碍物与测量点的距离信息,可以用于三维重构、即时定位和地图构建(SLAM)等。
基于激光雷达的深度估计
一种直接的方法就是通过激光雷达采集点云数据,这些点云数据可以代表深度信息。这种方法采集到的深度信息直接、可靠,但是部分问题无法避免。点云数据的稀疏性需要使用插值等方式进行稠密化。同时还受限于采集范围、固定的采集角度、车速限制等。如下图所示,这是一张激光雷达采集到的深度图。可以看到的是,这个深度图由多条线构成。这是因为激光雷达是多线的(32线/64线)。这样就导致了扫面结果以线的形式呈现,不是连续致密的结果。而且从图中可以看到,部分区域是没有数据的,这也是因为激光雷达的扫描范围限制。

基于光学图像的深度估计
双目深度估计
此方法是类人感知环境深度的方法。通过两个具有一定相对位置的摄像头来采集光学图像,然后通过两张光学图像来确定深度信息,这可以归纳为一个立体匹配的问题。也就是找到左图与右图中对应点,利用对应点的视差(空间中同一点在左图和右图中成像位置的变化量)来确定该点的深度。

如图所示,要确定空间中的一点p到两摄像头主点(Ol, Or)连线的距离Z。从图中几何关系可知,由于左摄像头和右摄像头的位置是不同的,导致p点分别在左摄像头焦平面和右摄像头焦平面上成像,在ul和ur点,定义视差
d
=
u
l
0
−
u
r
0
d=u_{l0} - u_{r0}
d=ul0−ur0,它为P在左图和右图中成像位置的差异。焦距为f,两摄像头距离为
T
=
O
l
−
O
r
T=O_l - O_r
T=Ol−Or。图中存在相似三角形
p
u
l
u
r
pu_lu_r
pulur和
p
O
l
O
r
pO_lO_r
pOlOr,即有:
Z
−
f
Z
=
T
−
d
T
\frac{Z-f}{Z}=\frac{T-d}{T}
ZZ−f=TT−d
进而得到
f
Z
=
d
T
\frac{f}{Z}=\frac{d}{T}
Zf=Td
Z
=
f
∗
T
d
Z=\frac{f*T}{d}
Z=df∗T
由上式可知,在摄像头焦距f和两摄像头布置位置相对固定时,空间中的一点的成像视差和其到摄像头平面的距离成反比。这样既可以把深度转化成视差,所以只需要确定左图和右图上对应的点,就可以根据视差确定深度。
单目深度估计
单目深度估计装置简单,便于安装,应用前景也比较大。单目深度估计包括基于图像内容理解、基于聚焦、基于散焦、基于明暗变化等方式。理论上来讲,单目深度估计的信息量是不够的,因为图像上一点对应于空间中的一条射线,无法直接通过一张图片定位空间中点的位置。
早期的单目深度估计采用直接回归深度的方法,通过卷积神经网络直接回归深度信息。流程大致可以理解为输入一张图片经过CNN生成一个粗略的结果,因为CNN中存在卷积层和下采样,感受野很大,输出全局的整体结果。然后将这个粗略的结果与原始图片一起输入到精细网络中。由于精细网络中没有下采样过程,我们可以根据原图和粗略结果提取到细节和边缘信息,从而得到精细结果。这种方法实际效果一般,而且深度信息难以获得,标准数据获取难,最终决定了它的应用场景存在较大局限。
除了直接估计外,单目深度估计往往会使用到重构的方法,通过与原图空间相关或者时序相关的另一张图进行估计。这种模型较为复杂,需要利用空间关系进行重新采样,但是效果比直接估计要好很多。另外,重构的方法不需要真实的深度信息,这就降低了数据获取的成本。基于重构的深度估计方法有两种:
1. 基于视频的方法,重构视频中的前后帧;
2. 给定左图重构右图的方法(在训练的过程中需要成对的图像,但是在测试过程中仅需要一张图)
基于视频的单目深度估计方法
此方法可以分解为两个子问题 —— 预测每一帧的深度图和车辆自身的运动姿态。由此可以推断出,实现的模型可以分为两个子网络。空间坐标系中一点到摄像头坐标系的映射关系为:
Z
[
x
y
1
]
=
K
M
[
X
Y
Z
1
]
Z\begin{bmatrix}x \\ y \\ 1 \end{bmatrix} = KM\begin{bmatrix}X \\ Y \\ Z \\ 1\end{bmatrix}
Z
xy1
=KM
XYZ1
其中,(X,Y,Z)是空间坐标系中的一点,(x,y)是该店在摄像头坐标系中的坐标,M是摄像头外参,K是摄像头内参。假设t时刻某张图的深度信息,即已知该图上某点坐标(x,y),以及该点对应的深度值Z,则有
M
[
X
Y
Z
1
]
=
Z
K
−
1
[
x
y
z
]
M\begin{bmatrix}X \\ Y \\ Z \\ 1\end{bmatrix} = ZK^{-1}\begin{bmatrix}x \\ y \\ z\end{bmatrix}
M
XYZ1
=ZK−1
xyz
若已知 t 时刻到 t+1 时刻摄像头的运动状态,则此运动可表示为一转移矩阵
T
t
=
[
R
t
T
t
0
1
]
T^t = \begin{bmatrix} R^t & T^t \\ 0 & 1 \end{bmatrix}
Tt=[Rt0Tt1],则 t+1 时刻的摄像头外参可表示为
M
t
+
1
=
M
T
t
M^{t+1} = MT^t
Mt+1=MTt,则 t+1 时刻的映射关系可表示为
Z
t
+
1
[
x
t
+
1
y
t
+
1
1
]
=
K
M
t
+
1
[
X
Y
Z
1
]
Z^{t+1}\begin{bmatrix}x^{t+1} \\ y^{t+1} \\ 1\end{bmatrix} = KM^{t+1}\begin{bmatrix}X \\ Y \\ Z \\ 1\end{bmatrix}
Zt+1
xt+1yt+11
=KMt+1
XYZ1
=
K
T
t
M
[
X
Y
Z
1
]
= KT^tM\begin{bmatrix}X \\ Y \\ Z \\ 1\end{bmatrix}
=KTtM
XYZ1
=
K
T
t
Z
K
−
1
[
x
y
1
]
= KT^tZK^{-1}\begin{bmatrix}x \\ y \\ 1 \end{bmatrix}
=KTtZK−1
xy1
整理可得:
[
x
t
+
1
y
t
+
1
1
]
=
1
Z
t
+
1
K
T
t
Z
K
−
1
[
x
y
1
]
\begin{bmatrix}x^{t+1} \\ y^{t+1} \\ 1\end{bmatrix} = \frac{1}{Z^{t+1}} KT^tZK^{-1}\begin{bmatrix}x \\ y \\ 1 \end{bmatrix}
xt+1yt+11
=Zt+11KTtZK−1
xy1
从上式可知,当知道了 t 帧、t+1帧的深度信息,以及从t 帧到 t+1帧的摄像头自身运动状态,那么就可以找到 t+1帧中的某一点(xt+1, yt+1)在 t帧中的位置(x,y)(需要保证环境相对于世界坐标系静止),进而可以从t 帧的图像中采样得到 t+1帧图像的重构图。
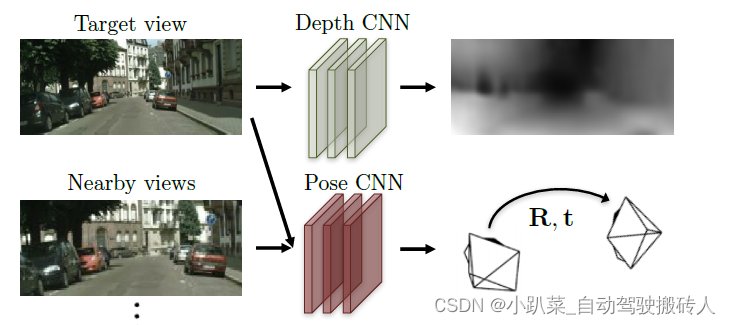
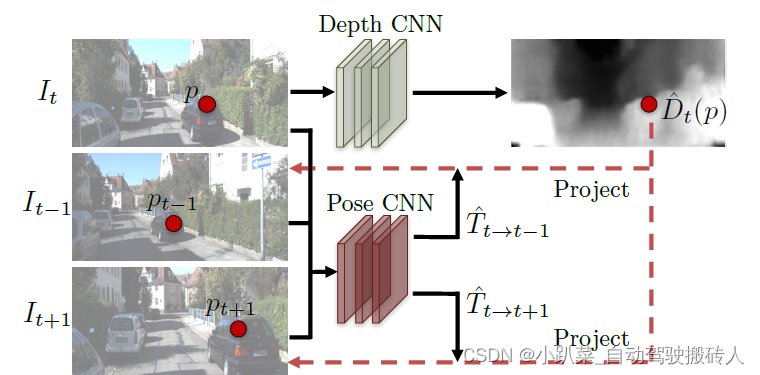
完整过程如图所示。
I
t
I_t
It表示t 时刻的输入图像,有深度CNN网络生成深度信息。
I
t
−
1
I_{t-1}
It−1、
I
t
+
1
I_{t+1}
It+1 分别为t-1 和 t+1时刻的图像,分别与
I
t
I_t
It经过姿态CNN网络预测出t-1 到 t、t 到 t+1的外参转移矩阵
T
t
−
1
→
t
T_{t-1 \rightarrow t }
Tt−1→t、
T
t
→
t
+
1
T_{t \rightarrow t+1 }
Tt→t+1。然后根据上文的公式可以得到
I
t
−
1
I_{t-1}
It−1、
I
t
+
1
I_{t+1}
It+1与、
I
t
I_t
It的采样关系,从而得到重构的两张图
I
t
−
1
′
I_{t-1}^{'}
It−1′、
I
t
+
1
′
I_{t+1}^{'}
It+1′。
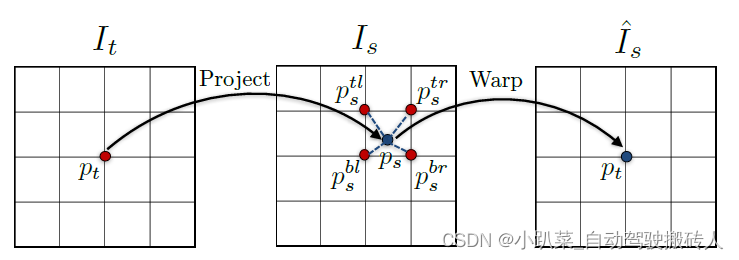
采样重构的具体过程如下图所示,表示的式从
I
s
I_s
Is中采样,重构
I
t
I_t
It。已知
I
t
I_t
It与
I
s
I_s
Is中点的映射关系:
p
t
→
p
s
p_t \rightarrow p_s
pt→ps,那么在
p
s
p_s
ps处采用双线性插值的方法,取其临近的四个点的像素值,根据
p
s
p_s
ps点到每一个点的距离进行加权平均,得到
p
s
p_s
ps点处的像素值,作为重构图中
p
t
p_t
pt处的像素值。这种方法既能使重构的图像连续平滑,又能保证重构图可到,进行反向传播。
给定左图重构右图
此方法训练所使用的数据不再是连续的视频,而是成对的图像。虽然此方法在训练的时候使用了成对的图像,但是在测试的过程中只需要使用其中的一张图。当然,此方法也是用到了重构,但重构的是同一时间不同摄像头拍摄的图像,并且不需要对深度信息进行标定。该方法的过程如下:
1. 给定一组输入图片左图(L)、右图(R);
2. L图经过CNN得到预测的两个视差图
L
d
L_d
Ld(左图相对于右图的视差)、
R
d
R_d
Rd(右图相对于左图的视差);
3. 采用双线性差值方法,由L图和
R
d
R_d
Rd采样重构出右图
R
′
R^{'}
R′;
4. 使用同样的方法,由R图和
L
d
L_d
Ld采样重构出左图
L
′
L^{'}
L′;
5. 分别使用L和R对
L
′
L^{'}
L′、
R
′
R^{'}
R′进行估计。
由于深度信息与视差的固定关系,在测试时只需要得到视差图就可以。所以在测试过程中可以简化,对于给定的左图L,由训练好的CNN得到一张左视差图
L
d
L_d
Ld,然后由
Z
=
f
∗
B
d
Z=\frac{f*B}{d}
Z=df∗B得到深度信息。其中Z为深度信息,f为焦距,d是视差,B是两摄像头的光心距离。
光流估计
光流是指图像中每个像素点的二维瞬时速度场,其中的二维速度指的是物体空间中三维速度向量在成像平面上的投影。换句话说就是图像中的每一个像素点在途中的移动速度。光流信息可以应用于动作识别、物体轨迹预测、动目标识别等。
LK算法
LK(Lucas-Kanade)算法是一种稀疏的光流算法。在此之前,需要先说明LK算法的几条假设:
1. 运动物体的灰度值在短时间内保持不变,这是寻找两帧之间对应点的关键所在;
2. 图像随时间变化较慢,也就是可以使用相邻像素点的灰度差异来表征某一点的梯度。这个假设也是光流法中及其重要的假设。
3. 图像的每一个小邻域中光流近似一致。
现在介绍LK算法的流程。首先,假设图像上的一个像素点(x,y),在某时刻的灰度为I(x,y,t),用u和v分别表示该点的光流在水平和垂直方向上的分量。那么
u
=
d
x
d
t
v
=
d
y
d
t
u=\frac{dx}{dt} \quad \quad \quad v=\frac{dy}{dt}
u=dtdxv=dtdy
经过一段时间Δt 后,该点在t+Δt 时的对应位置的灰度为I(x+Δx, y+Δy, t+Δt),利用泰勒展开式可得:
I
(
x
+
Δ
x
,
y
+
Δ
y
,
t
+
Δ
t
)
=
I
(
x
,
y
,
z
)
+
∂
I
∂
x
Δ
x
+
∂
I
∂
y
Δ
y
+
∂
I
∂
t
Δ
t
+
H
.
O
.
T
I(x+\Delta x, y+\Delta y, t+\Delta t) = I(x, y, z) + \frac{\partial I}{\partial x}\Delta x + \frac{\partial I}{\partial y}\Delta y + \frac{\partial I}{\partial t}\Delta t + H.O.T
I(x+Δx,y+Δy,t+Δt)=I(x,y,z)+∂x∂IΔx+∂y∂IΔy+∂t∂IΔt+H.O.T
其中,H.O.T是指更高阶的量,可忽略。在基于之前的假设,运动物体的灰度值在短时间内保持不变,也就是
I
(
x
+
Δ
x
,
y
+
Δ
y
,
t
+
Δ
t
)
≈
I
(
x
,
y
,
z
)
I(x+\Delta x, y+\Delta y, t+\Delta t) \approx I(x, y, z)
I(x+Δx,y+Δy,t+Δt)≈I(x,y,z),即
∂
I
∂
x
Δ
x
+
∂
I
∂
y
Δ
y
+
∂
I
∂
t
Δ
t
=
0
\frac{\partial I}{\partial x}\Delta x + \frac{\partial I}{\partial y}\Delta y + \frac{\partial I}{\partial t}\Delta t = 0
∂x∂IΔx+∂y∂IΔy+∂t∂IΔt=0
当Δt趋近于0时,可得到
−
∂
I
∂
t
Δ
t
=
∂
I
∂
x
d
x
d
t
+
∂
I
∂
y
d
y
d
t
=
∂
I
∂
x
u
+
∂
I
∂
y
v
-\frac{\partial I}{\partial t}\Delta t =\frac{\partial I}{\partial x}\frac{dx}{dt} + \frac{\partial I}{\partial y}\frac{dy}{dt} = \frac{\partial I}{\partial x}u + \frac{\partial I}{\partial y}v
−∂t∂IΔt=∂x∂Idtdx+∂y∂Idtdy=∂x∂Iu+∂y∂Iv
−
I
t
=
[
I
x
I
y
]
[
u
v
]
-I_t = \begin{bmatrix}I_x & I_y\end{bmatrix}\begin{bmatrix}u \\ v\end{bmatrix}
−It=[IxIy][uv]
其中,
I
t
、
I
x
、
I
y
I_t、I_x、I_y
It、Ix、Iy分别时灰度相对于时间、横坐标、纵坐标的导数。基于前面的假设,可以用一点在两帧之间的灰度变化来代表
I
t
I_t
It,用相对于其临近点的灰度差异代表
I
x
、
I
y
I_x、I_y
Ix、Iy。再加上第三个假设,我们可以联立n(为一个邻域内的总点数)个方程如下:
{
I
1
x
u
+
I
1
y
v
=
−
I
1
t
I
2
x
u
+
I
2
y
v
=
−
I
2
t
⋮
I
n
x
u
+
I
n
y
v
=
−
I
n
t
\left\{ \begin{array}{c} I_{1x}u + I_{1y}v = -I_{1t} \\ I_{2x}u + I_{2y}v = -I_{2t} \\ \vdots \\ I_{nx}u + I_{ny}v = -I_{nt} \end{array} \right.
⎩
⎨
⎧I1xu+I1yv=−I1tI2xu+I2yv=−I2t⋮Inxu+Inyv=−Int
 对于上面的方程组,可用最小二乘法求得最优解:
[
−
I
i
t
]
=
[
I
i
x
I
i
y
]
[
u
v
]
\begin{bmatrix}-I_{it}\end{bmatrix} = \begin{bmatrix}I_{ix} I_{iy}\end{bmatrix} \begin{bmatrix}u \\ v \end{bmatrix}
[−Iit]=[IixIiy][uv]
[
u
v
]
=
(
[
I
i
x
I
i
y
]
T
[
I
i
x
I
i
y
]
)
−
1
[
I
i
x
I
i
y
]
[
−
I
i
t
]
\begin{bmatrix}u \\ v \end{bmatrix} = ( {\begin{bmatrix}I_{ix} \quad I_{iy}\end{bmatrix}}^T \begin{bmatrix}I_{ix} \quad I_{iy}\end{bmatrix})^{-1}\begin{bmatrix}I_{ix} \quad I_{iy}\end{bmatrix}\begin{bmatrix}-I_{it}\end{bmatrix}
[uv]=([IixIiy]T[IixIiy])−1[IixIiy][−Iit]
=
[
∑
i
=
1
n
I
i
x
2
∑
i
=
1
n
I
i
x
I
i
y
∑
i
=
1
n
I
i
x
I
i
y
∑
i
=
1
n
I
i
y
2
]
−
1
[
−
∑
i
=
1
n
I
i
x
I
t
−
∑
i
=
1
n
I
i
y
I
t
]
={\begin{bmatrix} \sum\limits_{i=1}^n I_{ix}^2 & \sum\limits_{i=1}^n I_{ix}I_{iy} \\ \sum\limits_{i=1}^n I_{ix}I_{iy} & \sum\limits_{i=1}^n I_{iy}^2 \end{bmatrix}}^{-1} {\begin{bmatrix} -\sum\limits_{i=1}^n I_{ix}I_t \\ -\sum\limits_{i=1}^n I_{iy}I_t \end{bmatrix}}
=
i=1∑nIix2i=1∑nIixIiyi=1∑nIixIiyi=1∑nIiy2
−1
−i=1∑nIixIt−i=1∑nIiyIt
此算法只能解决运动较小的情况。对于运动较大的情况,可采用金字塔分层的方式,缩小原图,使得LK算法继续适用。
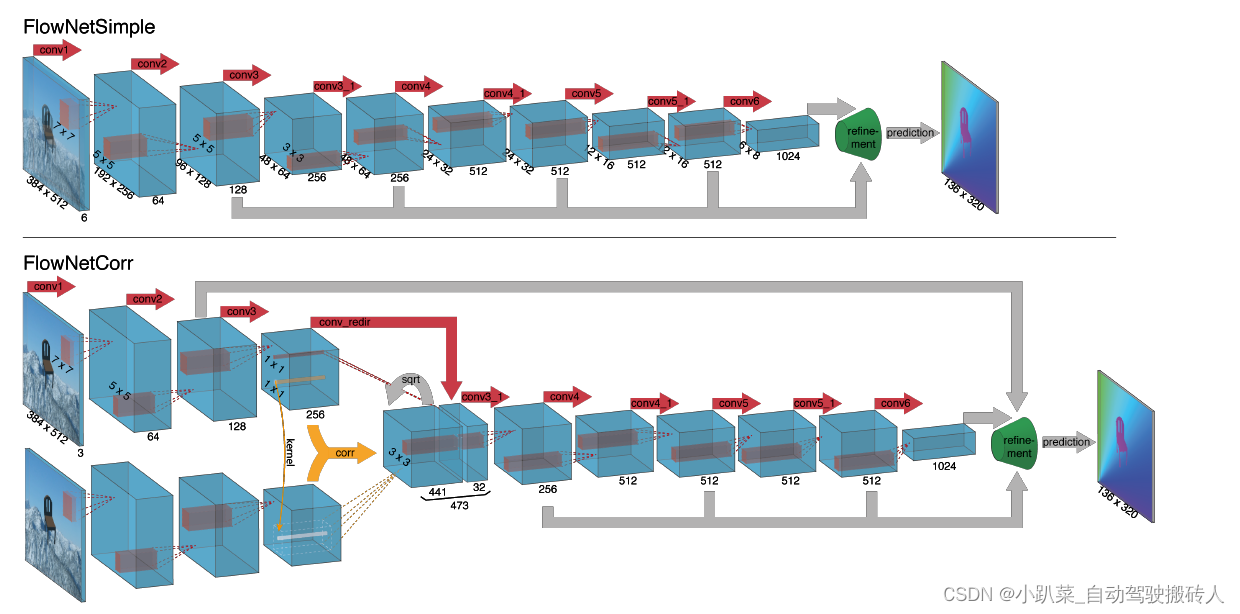
FlowNet
FlowNet是一种基于深度学习的光流计算方法,如图所示。
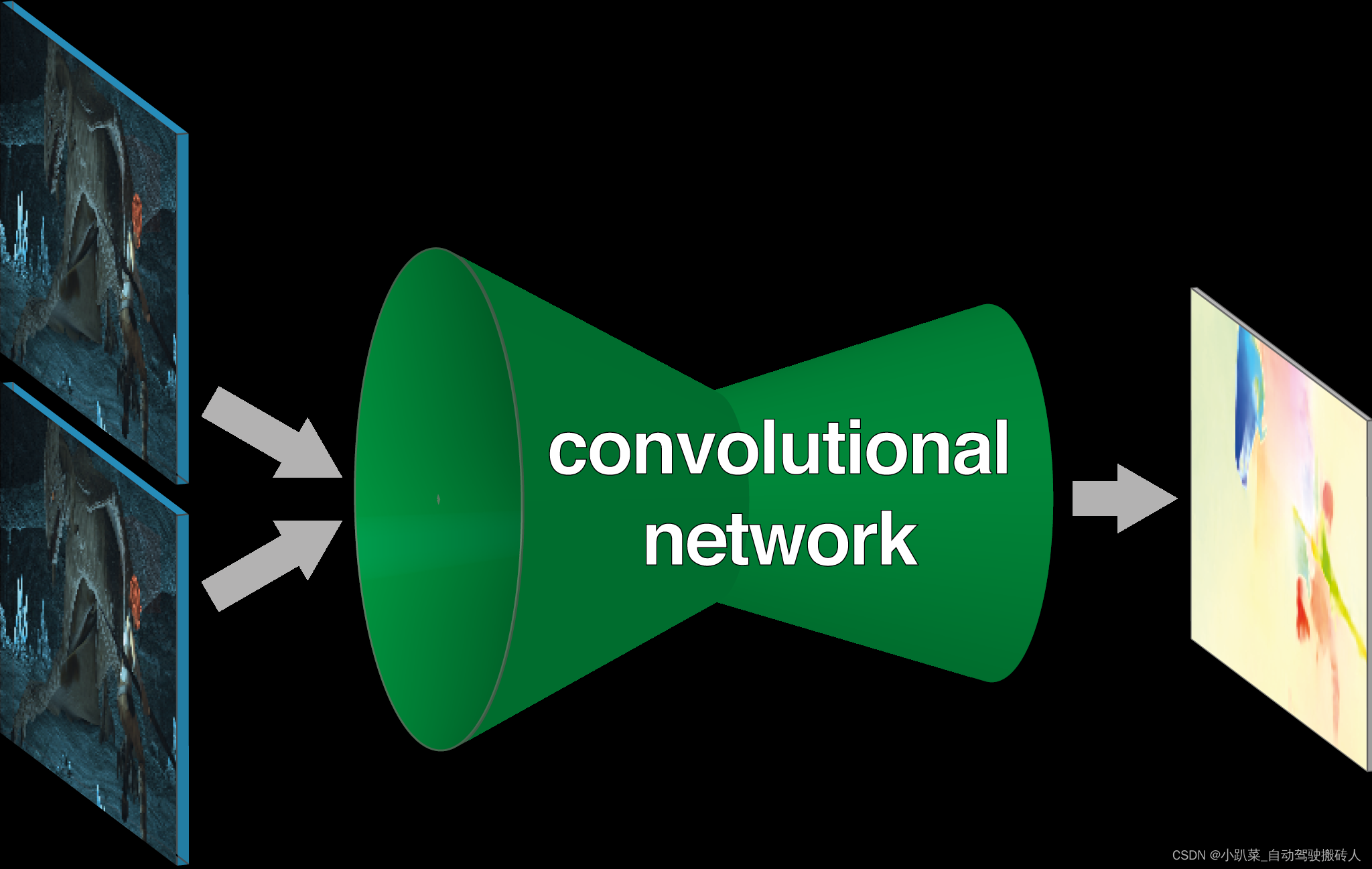
给定一对时序相关的图像,通过卷积神经网络得到两张图片之间的光流信息。光流问题与深度估计问题类似,两者的关键点都是在于立体匹配。只要能够匹配一对图片中的对应点,那么深度和光流都可以比较容易得到。FlowNet有两种实现方式:
1. 直接将成对的图片拼在一起,将输入通道数变成6,通过一个卷积神经网络学习其特征和相关性,然后经过细化网络得到光流信息。
2. 将两张图分别经过一个参数共享的卷积神经网络提取特征,分别得到对应两张输入图的特征图,然后经过一个计算相关性的层,得到两张特征图上每一点在空间上的相关性,将此相关性矩阵与原特征图进行拼接,用于后续的预测。
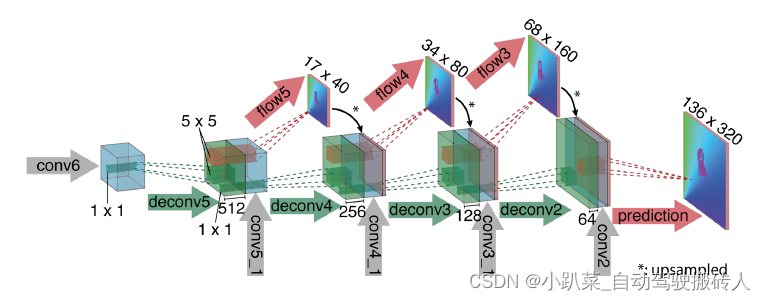
细化网络如下图所示。其作用是对结果进行上采样,得到高分辨率的结果图。这里使用到了深度监督的方法,在上采样的每一步中,都会由一个卷积层输出该尺寸的结果并进行监督训练。并且,此结果进行上采样后会拼接到下一个维度的特征图中,参与更大尺寸的预测。
















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











