







渲染流水线
本篇参考《Shader入门精要》·冯乐乐女神著;
B站视频 “技术美术百人计划”·霜狼_may ;
本人数媒专业,TA小白,该文章用于自我参考复习,如有问题,请多多指教
一.大致介绍
1.整体流程(渲染管线可分为四个阶段)
- 应用阶段: 粗粒度剔除,进行渲染设置,准备基本数据,输出到几何阶段
- 几何阶段: 顶点着色器,曲面细分,几何着色器,顶点裁剪,屏幕映射
- 光栅化阶段:三角形(点/线)设置,三角形(点/线)遍历,片段着色器
- 逐片元操作:裁剪测试,透明度测试,深度测试,模板测试,混合(一般分法都参考于《Render-Time Rendering》将该操作归入光栅化中)
(后处理)

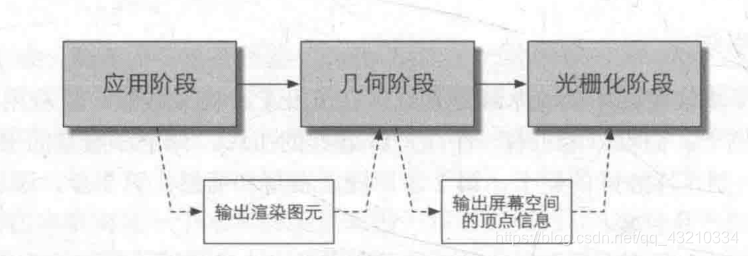
2.渲染流水线最终目的:输入虚拟摄像机(计算机动画课程里也可讲“视点”),光源,shader以及纹理,生成或渲染一张二维纹理;
二.分阶段介绍
1.应用阶段:
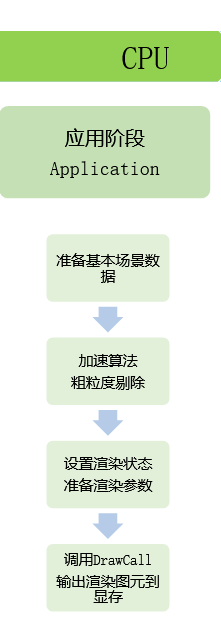
在渲染管线中,应用阶段是在CPU中进行处理的
- 首先是准备场景,从磁盘或是内存上读取模型或者贴图数据,将其加载进应用程序中,对象为基本数据:包括不限于场景中的物体的位置,朝向,大小,物体网格数据,顶点位置,UV贴图,法线,切线等;场景的光源位置朝向,类型,参数属性等;摄像机位置朝向,模式,视口长宽比等等…
补充:光源和阴影
- 设置光源:
1.方向光,颜色,方向等
2.点光源:颜色,位置,范围等
3.聚光源:颜色,位置,方向,内外圆锥角等
- 设置阴影:
1.是否需要阴影:判断该光源可见范围内是否有可投阴影的物体
2.阴影参数:对应光源序号,阴影强度,级联参数,深度偏移,近平面偏移等
- 逐光源绘制阴影范围:
1.近平面偏移
2.逐级联
- 计算当前光源+级联对应的观察矩阵,投影矩阵,以及对应到阴影贴图里的视口区域
- 绘制到阴影贴图
- 加速算法,粗粒度剔除:处理遮挡的问题,不会看到的,就不渲染,降低渲染成本,提高渲染性能
- 可见光裁剪:点光和聚光有衰减,聚光锥体有区域;若离相机距离较远,或者光锥与相机的视锥体不相交,则剔除渲染;
- 可见场景物体裁剪:遮挡啥的,相关算法:八叉树,BSP树,k-D树,PVH包围盒等
说起裁剪就不由想起图形学里的经典裁剪算法:Liang-Barsky算法,Cohen-Sutherland算法(编码裁剪算法)这两个算法是用于将图像裁剪到可见范围内
(遮挡剔除应该不涉及吧,遮挡应该是采用Zbuffer深度缓冲区进行检测 )
- 设置渲染状态,准备渲染参数:渲染UI和场景,其参数和模式可能不一样,通俗解释:场景中的网格如何被渲染,渲染顺序是啥,使用哪个顶点着色器/片元着色器,光源属性,材质,最后会渲染到哪里,渲染模式等等…
-绘制设置:使用着色器,合批方式
- 绘制物体顺序:相对相机距离,材质RenderQueue,UICanvas等
- 渲染目标:FrameBuffer,RenderTexture...
- 渲染模式:前向渲染(ForwardBase ForwardAdd),延迟渲染
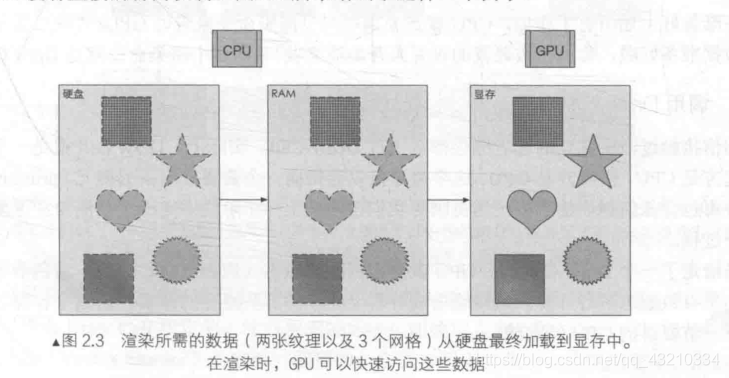
- 调用DrawCall,输出渲染图元到显存:图元从CPU迈向GPU
- 顶点数据:位置,颜色,法线,纹理uv坐标,其他顶点数据
- 其他数据:MVP变换矩阵,纹理贴图,其他数据
2.几何阶段
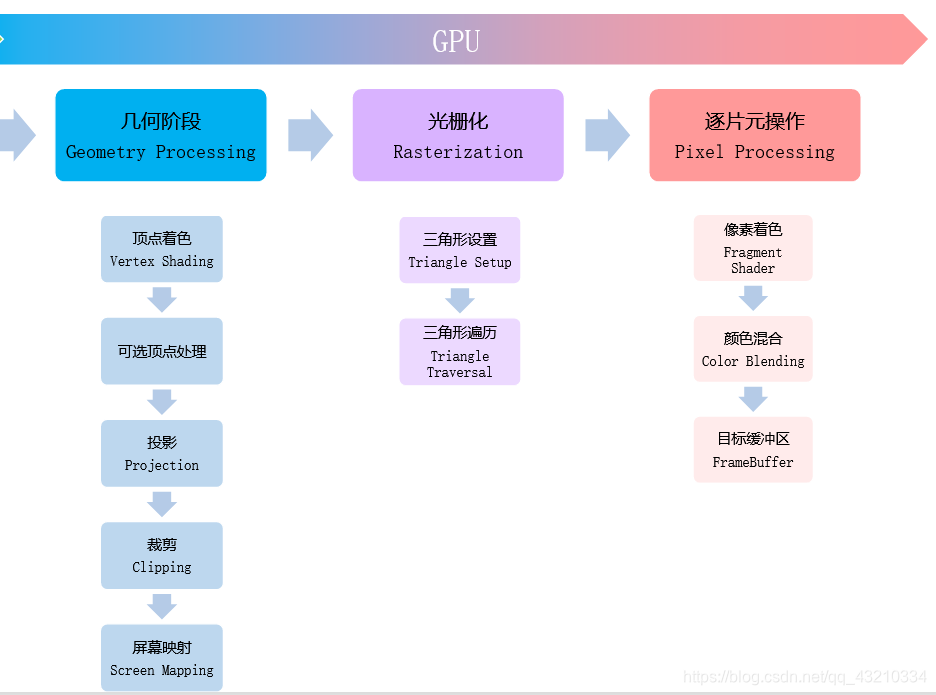 几何阶段,光栅化,逐片元这些操作都是在GPU中进行处理的,那么在讲几何阶段前,我们先聊聊为什么要用GPU渲染?
几何阶段,光栅化,逐片元这些操作都是在GPU中进行处理的,那么在讲几何阶段前,我们先聊聊为什么要用GPU渲染?
答:GPU的特点是并行性较好。当我们在对顶点数据进行处理时,他们虽然数据不同,但光照,几何运算方式啥都一样的时候,那么我们将他们放在GPU的不同工作单元上进行同时执行,速度会更快。

- 顶点着色器:必须完成的一个工作:将顶点坐标从模型空间转换到齐次裁剪空间(投影坐标系),同时它还有计算顶点光照的功能,这需要获取应用阶段中光源位置朝向,摄像机位置朝向,当前顶点的世界位置(获取该位置需知道顶点在模型空间的位置,模型本身的位置旋转缩放…);
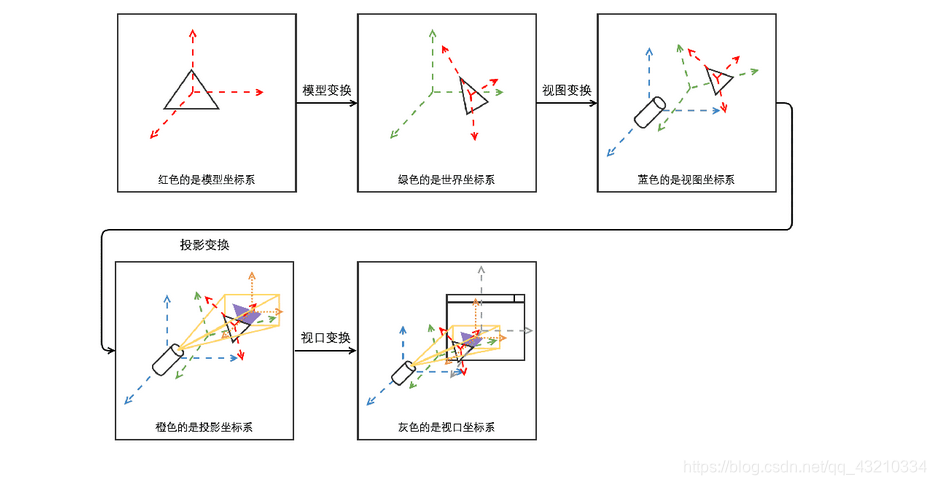
顶点着色器-视图变换:模型坐标系--(模型变换) --> 世界坐标系
--(视图变换)-->视图坐标系 --(投影变换)-->投影坐标系--(视口变换)-->视口坐标系
上图中的前三个变换对应MVP(model view projection)矩阵,在顶点着色器中,顶点从模型坐标系转换到投影坐标系,最后一步由Unity帮忙完成
(碎碎念:看到这一系列变换,第一时间我就想起计算机动画技术课本上那串空间变换,一样的流程,那里面还要多计算坐标系的建立,先旋转还是先平移等问题,左右手坐标系不同,很容易绕晕)
- 曲面细分着色器:通过现有顶点生成更多的顶点,需获取顶点在模型中的位置信息
它是一个可选着色器,使用顶点着色器输出的顶点,按照一定规则算法生成更多顶点,将现有的网格和图元细分(其效果类似于MAYA中的“平滑”效果,模型圆滑了但面数增大了)
- 几何着色器(基于图元):通过现有的图元做些几何方面操作,生成更多顶点和图元,比如对现有图元所在平面生成法线,需获取现有图元顶点位置
-图元是啥?
答:可以为顶点,线段,俩顶点,三角形...基础的几何图形
- 投影:将3D空间投到2D空间
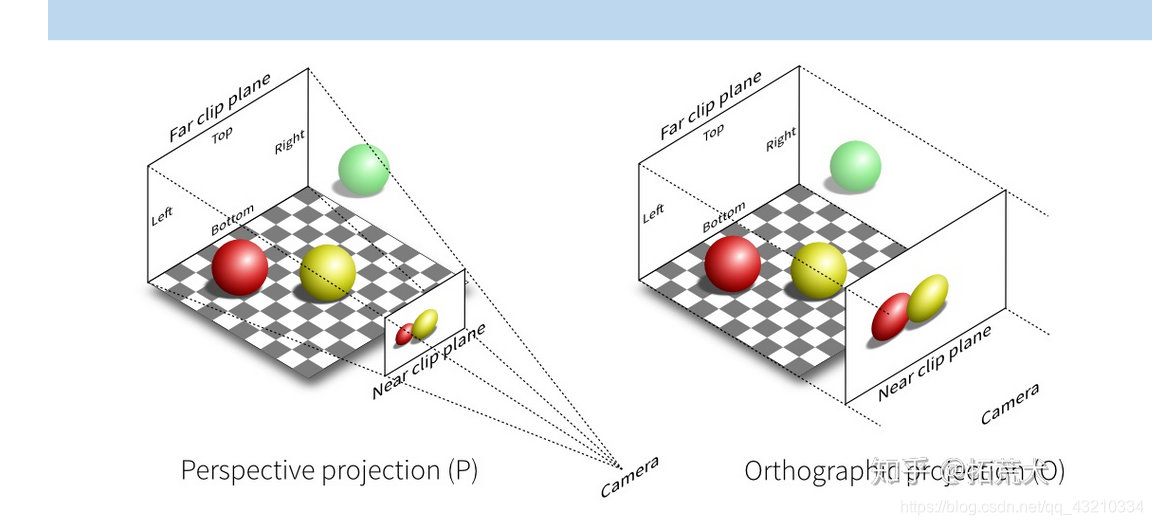
- 对于顶点在裁剪空间里的位置,xyzw进行透视除法:xyz除以w完成投影。使其从投影坐标系转换到标准设备坐标系(NDC);
- 由于正交和透视视角下w值不同,故而呈现效果不同,正交显得像截图,透视则近大远小
- 顶点裁剪:消去屏幕外的顶点;
- 投影里又说要进行除法操作,当xyz超过-1~1范围,则判断其不在范围内,
舍弃进行经典的图形学裁剪算法;
- 投影和顶点裁剪在《Shader入门精要》中都是归属于裁剪一节
中,这个操作过程无法由代码控制,是硬件上固定操作,但可以自定裁剪操作进行配置
(套娃,硬件裁下,Unity里自己再写个二次裁剪,~不是~)
- 设备坐标系在opengl和DirectX中不一样,opengl xyz三维度取值范围都是-1~1,DirectX只有xy是-1~1,z为0~1
- 屏幕映射:将顶点位置从3D坐标空间转换到2D坐标空间;
opengl和DirectX原点不同,opengl左下方,DirectX左上方
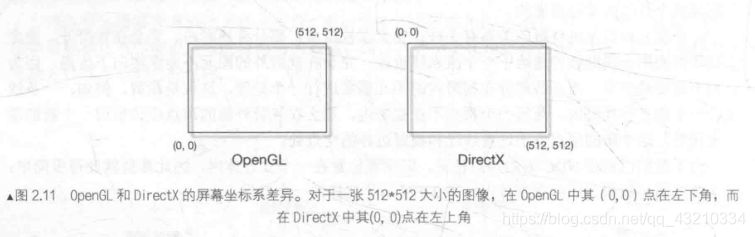
按照《Shader入门精要》所言:屏幕映射任务是把每个图元的x和y坐标转换到屏幕坐标系。
如应用阶段为几何阶段准备数据一样,几何阶段同样会为光栅化阶段准备数据;
3.光栅化阶段:
- 三角形设置:拿到映射于2D空间里的顶点位置,组装成三角形;
- 三角形遍历:寻找被三角形覆盖的所有像素的过程,知晓包含哪些2D空间像素点;
《Shader入门精要》:三角形遍历阶段将检查每个像素是否被一个三角网格所覆盖,若覆盖,则生成一个片元。
片元非像素,它是包含很多状态的集合,这些状态用于计算每个像素的最终颜色,这些状态包含不限于,屏幕坐标,深度信息,从几何阶段输出的顶点信息,法线,纹理坐标等。屏幕同一个像素位置可能有对应多个三角形的不同片元(如两片重叠的交集)
(遍历这一阶段的举例图像,很难不让人想到那些扫描算法)
-
抗锯齿(MSAA):
1.SSAA:- 渲染到一个分辨率放大n倍的buffer:屏幕分辨率1024x1024,渲染得到buffer可为2048x2048,放大四倍,对其采样后再输出屏幕
- 对方打n倍的buffer下采样
2.MSAA
- 只有它发生在光栅化阶段
- 计算多个覆盖样本:覆盖测试看子采样点是否在三角形以内,遮挡测试看这个子采样度的深度和,即与深度缓存中数值进行比较,看能否通过,若能通过两测试,则说明采样点属于三角形,得到覆盖信息并保存,用于之后的着色混合
3.FXAA/TXAA
后处理技术 -
片段着色器:使用这些点的数据进行着色,并为后面片元着色器准备;
4.逐片元操作
主要任务:
1.决定每个片元可见性
2.若通过所有测试,则将其颜色值和已存储在颜色缓冲区中的颜色进行合并混合
- 在逐片元操作中,我们通过裁剪,透明度,深度,模板各种测试来筛选我们所需要的的片元;
- 由于在2D屏幕坐标系中,同一位置的像素点可能存在多个不同的片元(一对多),我们会将筛选过后的片元进行混合以得到一个类似贴图的数据,并将其保存在内存中;
5.后处理
Bloom,HDR,FXAA,景深,边缘检测,径向模糊

















 2229
2229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









