







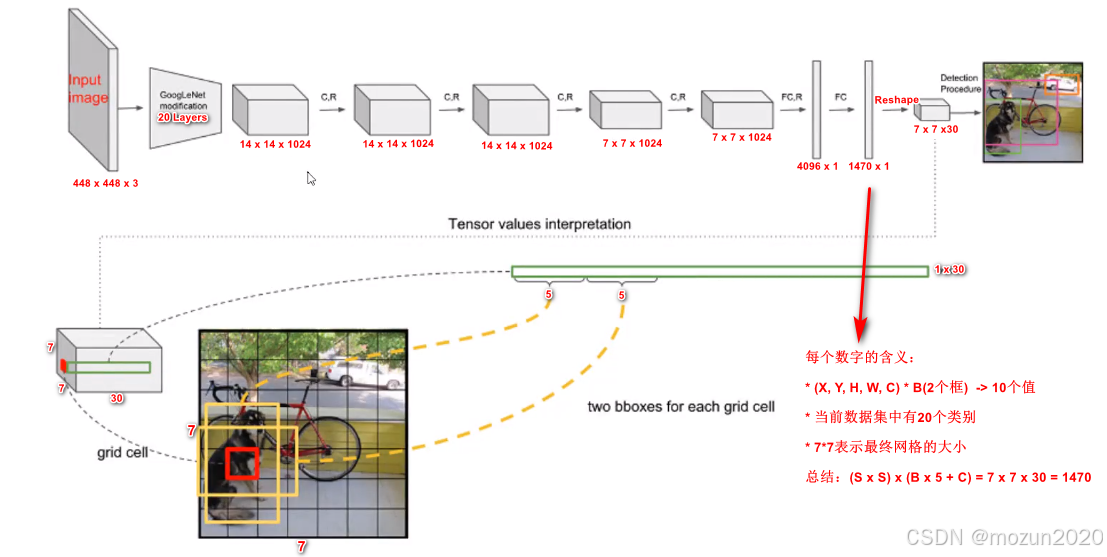
在YOLOv1中,最终的输出张量维度为7×7×30,其中每个网格单元预测两个边界框(Bounding Box)和对应的20个类别概率。这种设计导致每个网格单元的类别概率数量为20,而非每个边界框单独分配20个类别(即总40个),其核心原因如下:
1. YOLOv1的输出结构解析
每个7×7网格单元的输出包含:
- 2个边界框:每个边界框预测以下5个参数:
- 中心坐标偏移量(x, y)
- 宽高缩放比例(w, h)
- 置信度(Confidence):表示该框包含目标的概率,与类别无关。
- 20个类别概率:表示该网格单元属于PASCAL VOC数据集的20个类别的概率。
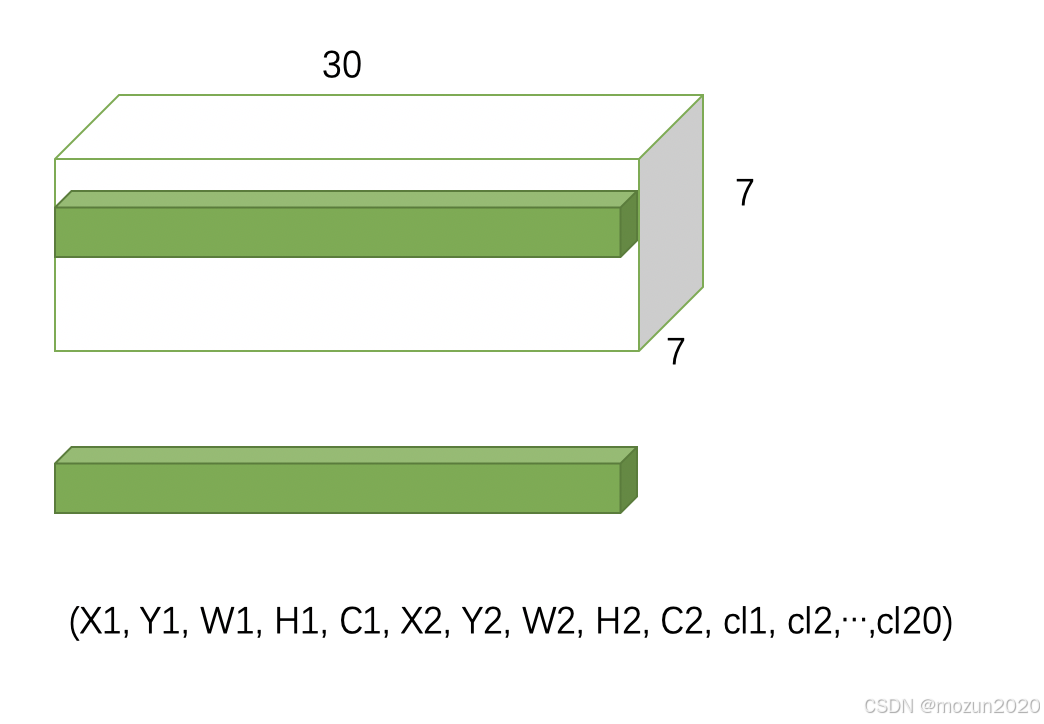
因此,每个网格单元的总输出维度为:
[2* 5 + 20 = 30 {(对应30个通道)}]
2. 类别概率与边界框的绑定关系
-
类别概率与网格单元绑定
YOLOv1的设计假设每个网格单元最多检测一个物体。因此:- 20个类别概率是网格级别的预测,而非针对单个边界框。
- 无论预测多少个边界框,同一网格单元内的所有边界框共享同一组类别概率。
-
置信度的作用
每个边界框的置信度(Confidence)表示:- 是否包含物体(与类别无关,由IoU和物体存在性决定)。
- 定位质量(预测框与真实框的重叠程度)。
3. 设计逻辑与局限性
设计逻辑
-
简化计算与参数数量
若每个边界框独立预测20个类别,每个网格单元需要2×20=40个类别参数,总输出维度将变为:
[2* (5 + 20) = 50 {(而非30)}]
这会导致参数量大幅增加,违背YOLOv1的轻量化设计目标。 -
基于网格单元的物体检测假设
YOLOv1假设一个网格单元仅对应一个主要物体,通过置信度筛选最可靠的边界框,并共享类别概率。这种设计适用于稀疏物体场景(如PASCAL VOC)。
局限性
- 无法处理密集物体:若同一网格内存在多个不同类别的物体,模型无法区分。
- 类别与定位任务耦合:共享特征可能导致分类与定位优化冲突(如高置信度但错误类别)。
4. 与后续版本的对比
从YOLOv2开始,模型逐步改进这一问题:
- YOLOv2/v3:引入Anchor Boxes,允许每个Anchor独立预测类别,支持多物体检测。
- YOLOv5/v8:采用解耦检测头(Decoupled Head),分类与回归任务使用独立分支,避免特征冲突。
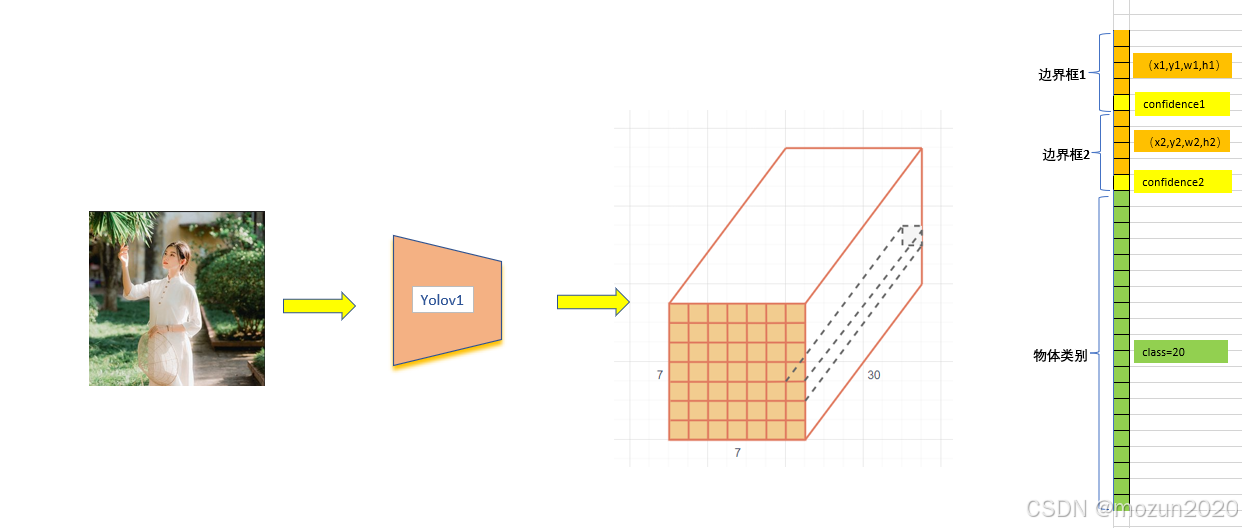
总结
YOLOv1的7×7×30输出中,20个类别概率属于网格单元,而非单个边界框,其设计基于以下原则:
- 参数效率:避免因独立类别预测导致的参数量爆炸。
- 单物体假设:每个网格单元仅检测一个主要物体,通过置信度筛选最佳边界框。
- 实时性优先:牺牲多物体区分能力以保持模型轻量化和高速度。
这一设计体现了YOLOv1在速度与精度之间的权衡,同时也为后续版本的改进指明了方向。



















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











