






论文标题:
3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of
Photo-Realistic Free-Viewpoint Videos
论文作者:
Jiakai Sun, Han Jiao, Guangyuan Li, Zhanjie Zhang, Lei Zhao, Wei Xing
导读:
渲染动态场景的自由视角高质量视频一直是个难题,现有的方法要么耗时长,要么质量差。NeRF提出后,训练时间从几天变为了几十小时,渲染质量也有了一定程度的提升,但与“高效实用”相比还差了不是一星半点。本文推出了3DGStream:一种能够高效重建真实世界动态场景的创新方法。3DGStream能够在12秒内快速完成每帧的重建,并以每秒200帧的速度实现实时渲染,将训练与渲染速度分别提升近10倍和100倍,快到令人难以置信!©️【深蓝AI】编译
1. 问题引入
构建自由视角视频一直是计算机视觉和图形学的前沿挑战,尤其是从多个已知姿态的相机视角捕捉视频来实现这一目标。虽然这个任务在虚拟现实(VR)、增强现实(AR)和扩展现实(XR)领域具有巨大的应用前景,但传统方法往往难以应对复杂的几何形状和外观。传统方法为了能够尽可能的还原场景的真实纹理,常常以时间为代价,进行长时间的训练,偏向于“慢工出细活”。
近年来NeRF因在合成新视角方面的强大能力而广受关注,它主要解决的是视频质量问题,通过使用神经辐射场学习场景的光线表达,能够在训练之后最大程度的还原场景纹理,虽然训练时间依旧很长,但是在最终的重建和渲染质量上有了很大的提升,并且支持多视角的渲染,比起传统方法已经提升了一个档次。但大多数NeRF方法需要完整的视频序列进行耗时的离线训练,无法实现实时渲染,限制了其实用性。
这里笔者解释一下为什么一直强调“实时渲染”,如果渲染不是实时的会怎么样?实际上在AR和VR等需要重建动态场景和渲染视频的领域,视频的渲染都是一个查看结果的过程,比如程序员对场景中的物体进行了编辑,或者改变了场景的各种属性,都需要进行渲染之后才能够查看到编辑的效果,那么对于开发人员来说,大家都希望“所写即所得”,写完代码之后立刻就能看到效果,而不是等待漫长的渲染时间,才能够查看。因此实时的渲染能够大大提高开发的效率。
为了解决这些问题,本文受到实现静态场景即时合成的启发,提出了3DGStream。这种方法利用3DGS作为baseline来重建动态场景并进行视频的渲染,显著提高了训练速度和渲染效率。具体来说,他们首先在时间步0的多视角帧上训练初始3DGS,然后在每个时间步使用前一个时间步的3DGS作为初始化,将训练过程分为了两个两阶段:
●第一阶段:训练神经转换缓存(NTC)来将场景表达为3DGS;
●第二阶段:使用自适应高斯添加策略处理动态场景中的新物体。
这一设计不仅减少了存储需求,还能够实时渲染高质量的动态场景视频。实验结果表明,与当前最先进的动态场景重建技术StreamRF相比,3DGStream在渲染速度、图像质量、训练时间和模型存储方面都具有竞争力,下面笔者将具体介绍实现的方法和原理。
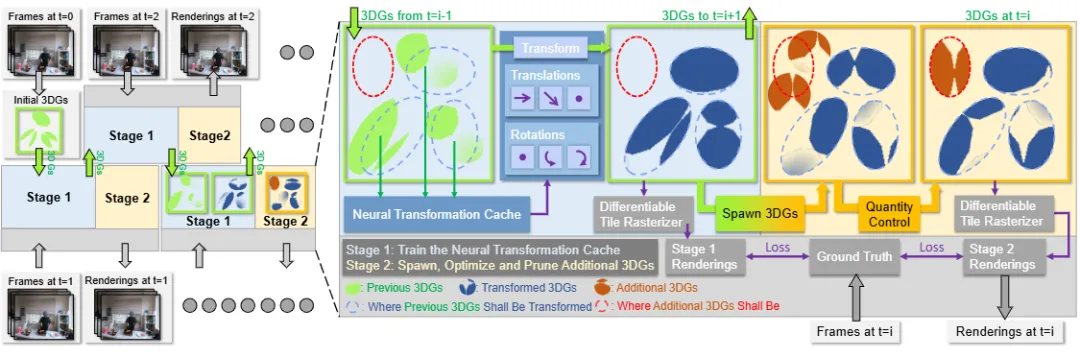 ▲图1|方法流程图©️【深蓝AI】编译
▲图1|方法流程图©️【深蓝AI】编译
2. 实现细节
给定一组多视角视频流,3DGStream旨在即时构建高质量的捕捉动态场景的视频。起初,3DGStream优化了一组3DGS来表示时间步0的场景。对于每个后续的时间步i,使用时间步i-1的3DGS作为初始化,然后进行两阶段的训练过程:
●第一阶段:训练神经转换缓存(NTC)来建模3DGS的平移和旋转。在训练之后,NTC转换3DGS,为下一个时间步和当前时间步的下一个阶段做准备;
●第二阶段:在潜在位置生成特定帧的额外3DGS,并对其进行优化,同时定期进行分裂和修剪。经过两阶段的过程后,转换后的3DGS和额外的3DGS都用于渲染当前的时间步i,只有转换后的3DGS被带入下一个时间步。
结合图2,笔者对训练过程进行一个概述解读:训练是两个阶段交替进行的,第一阶段的训练通过当前场景的输入,建立了属于当前场景的3DGS表达,第二阶段中,结合下一时间的场景即将发生的变形,进行了可能发生变形的3DGS估计,也就是作者说的“添加额外的3DGS”。这个过程相当于为下一帧的正式训练打好了基础,生成了一个先验信息,因此在下一帧开始训练的时候,只需要将先验信息进行进一步的优化即可,相当于在每一次的训练过程中,避开了从0-1的重建,而是做从1-2的优化,相信大家都明白0-1的生成和1-2的优化之间的差距。通过这个过程,作者极大程度地提升了训练的时间,这也是12秒能够实现的重要原因。
■2.1 一阶段训练
在第一阶段,作者主要进行的是当前场景的3DGS重建。作者希望寻求一种结构紧凑、高效且适应性强的模型来重建场景的3DGS。紧凑性有助于减少模型存储空间,高效性提升训练和推理速度,适应性确保模型更多关注动态区域。此外,考虑到动态场景的某些先验知识(如相邻部分的相似运动趋势)也是有益的。受到Neural Radiance Caching和I-NGP的启发,作者采用多分辨率哈希编码结合浅层完全融合的MLP作为NTC,用于生成场景的高斯表达。
具体来说,遵循I-NGP,作者使用多分辨率体素网格表示场景。每个分辨率的体素网格映射到存储d维可学习特征向量的哈希表。对于给定的3D位置x,其在分辨率任意处的哈希编码是周围网格八个角点特征向量的线性插值。多分辨率哈希编码满足作者对NTC的所有要求:
●紧凑性:哈希有效减少了编码整个场景所需的存储空间;
●高效性:哈希表查找操作在O(1)时间内完成,并且与现代GPU高度兼容;
●适应性:哈希冲突发生在较细分辨率的哈希表中,使得具有较大梯度的区域(在上下文中表示动态区域)驱动优化;
●先验:线性插值和体素网格结构的结合确保了转换的局部平滑性。此外,多分辨率方法巧妙地融合了全局和局部信息。
此外,为了在尽量减少开销的情况下提升NTC性能,作者使用浅层完全融合的MLP。这将哈希编码映射到7维输出:前三维表示3DGS的平移,其余维度使用四元数表示3DGS的旋转。通过这个过程,作者使用NTC完成了3DGS的高效表达,这也是整个第一阶段做的事情。
■2.2 二阶段训练
第二阶段的主要作用是在潜在位置生成特定帧的额外3DGS,并进行优化,这一过程的目的是因为当面对初始帧中不存在的物体,如短暂的火焰或烟雾,以及新出现的持久物体(例如从瓶子里倒出的液体)时,能够更好地表达场景。由于3DGS是一种非结构化的显式表示,必须添加新的3DGS来建模这些新出现的物体。考虑到模型存储需求和训练复杂性的限制,生成大量额外的3DGS或允许它们在后续帧中使用是不切实际的,因为这会导致3DGS随着时间的推移积累。这就需要一种策略,快速生成有限数量的帧特定3DGS,精确建模这些新出现的物体,从而在当前时间步增强场景的完整性。
首先,作者观察到,对于新出现的物体,附近的3DGS表现出较大的视点位置梯度。这是由于优化试图通过变换3DGS来“伪装”新出现的物体。基于上述观察,作者认为在这些高梯度区域引入额外的3DGS是合适的。此外,为了全面捕捉新物体可能出现的每个位置,作者采用了一种自适应的3DGS生成策略。
具体来说,在第一阶段的最终训练轮次中跟踪视点位置梯度。一旦这一阶段结束,作者选择视点位置梯度平均幅度超过较低阈值3DGS。对于每个选择的3DGS,会对其进行插值,从而生成新的3DGS。在生成后,3DGS使用与第一阶段相同的损失函数进行优化。注意,这里只有额外3DGS的参数被优化,而转换后的3DGS保持不变,这种方式同样提升了速度,因为和原有的3DGS相比,新生成的3DGS数量是很少的,因此这样子的优化策略能够极大程度的缩短3DGS的训练时间。
以上即为第二阶段实现的具体细节,笔者做个总结,第二阶段通过预测生成可能出现的新的3DGS并进行优化,为下一个训练帧的3DGS生成了可靠的先验,同时在优化过程通过特定的优化更新策略,只优化生成的少部分3DGS,提升了整体的训练速度。
3. 实验效果
实验部分作者主要对比了训练时间和图像质量,首先是训练时间的实验,作者基本上选择了所有相关的方法作为对比方法,可以看到本文提出的方法可谓“傲视群雄”,站在图像的最最最顶端。
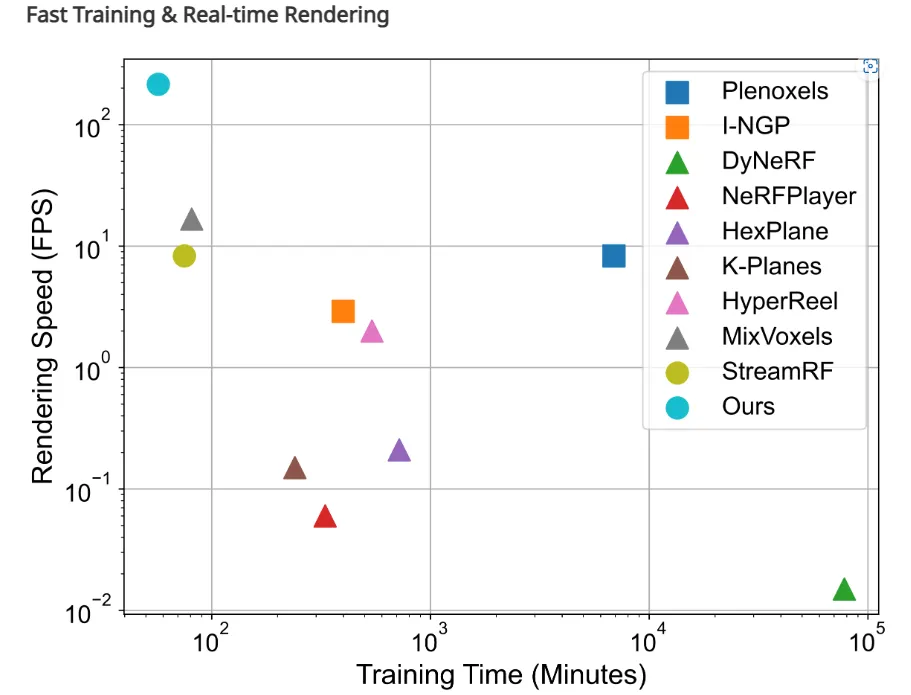 ▲图2|训练时间对比实验©️【深蓝AI】编译
▲图2|训练时间对比实验©️【深蓝AI】编译
随后作者进行了图像质量实验,通过可视化以及计算评价矩阵来验证了方法的可靠性,实验结果显示,3DGStream在渲染速度、图像质量、训练时间和模型存储方面均优于现有的SOTA方法。简而言之,3DGStream不仅能快速重建和渲染动态场景,还能以更少的资源实现更高的图像质量,使得自由视角视频的渲染更加高效和实用,先来一张图看看效果!

▲图3|渲染效果展示©️【深蓝AI】编译
 ▲图4|视频渲染可视化©️【深蓝AI】编译
▲图4|视频渲染可视化©️【深蓝AI】编译

▲图5|视频渲染可视化©️【深蓝AI】编译
如图3所示,本文提出的方法和GT基本上能够说是纹理一致,与其他对比方法在细节的重建上有较大的领先,图4则展示了动态视频重建和渲染的一个比较难的场景,就是出现了新的东西,比如火焰和液体,由于本文方法在第二阶段预先生成了这部分物体的高斯,因此能够将其进行更好的优化,从而实现更好的效果,可以从图4中看到两个阶段的对比,明显第二阶段生成了新的3DGS后,其渲染效果更接近GT。
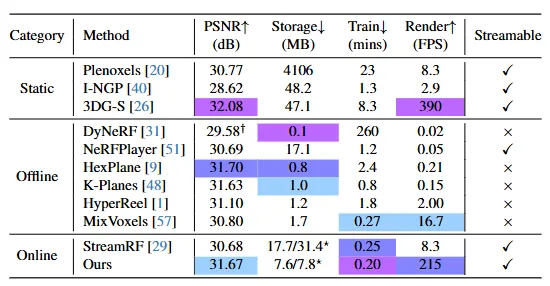
▲图6|数值实验结果©️【深蓝AI】编译
从图5可以看到,本文方法的数值实验结果并不比强调图像质量的NeRF-based方法差,即便是比起一些静态重建的方法(一般拥有更好的图像质量)也不遑多让。
4. 总结
3DGStream引入了一种高效的自由视角视频重建与渲染方法。该方法利用有效的神经转换缓存 (NTC) 捕捉物体运动,确保从多视角视频流中高质量地重建动态场景。此外,适应性 3DGS添加策略准确建模了动态场景中出现的新物体,实现了大约每帧12秒的即时训练和每秒约 200 帧的实时渲染,同时保持了照片级逼真的图像质量和适中的存储需求。
编译|阿豹
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态。

















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









