






导读:
这篇工作是首一个脱离了ASR和TTS的端到端语音对话模型,同时也将之前LLM大规模数据预训练的成功经验应用到了语音语言大模型上,得到了一个完全基于语音对话的模型,具有重要的意义。研究人员提出的text to token模型有效的缓解了纯语音数量不足无法像文本语料那样进行大规模预训练的问题。同时,将语音信息也建模成一种文本token使得模型不仅可以利用之前在语料库中预训练习得的知识,而且可以更好的对齐语音和文本模态,是语音文本大模型发展历史上里程碑式的工作,值得学习。
论⽂题目:SCALING SPEECH-TEXT PRE-TRAINING WITH SYNTHETIC INTERLEAVED DATA
论文作者:Aohan Zeng, Zhengxiao Du, Mingdao Liu, Lei Zhang, Shengmin Jiang, Yuxiao Dong, Jie Tang
论文地址:https://arxiv.org/abs/2411.17607
摘要:
语音语言模型(SpeechLMs)旨在实现更自然的语音交互,但传统训练受限于有限的无监督语音数据和语音-文本配对数据。这篇研究突破了这些限制,提出了一种新方法,通过从大规模文本语料库合成数据来扩展语音-文本预训练,无需实际的语音-文本配对。研究者从文本语料库采样文本片段,并用文本-语音模型合成对应的语音token,构建了语音token-文本交叉数据。此外,研究还开发了一种有监督的语音编码器,即使在低帧率下也能保持语音重建质量,并编码出强语义信息的离散语音token。预训练模型扩展到1万亿个token,包括6000亿合成语音-文本数据,显著提升了语音语言建模和口语问答的性能,将口语问题任务的评估结果从13%提升至31%。研究进一步展示了通过微调预训练模型,可以开发出与现有基线相当的端到端口语聊天机器人,即使完全在语音领域内操作。
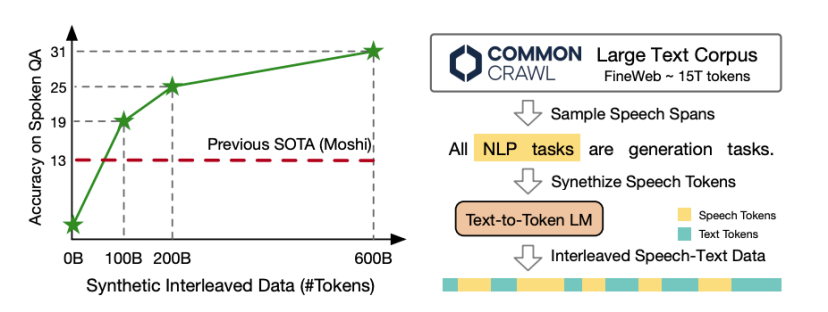
图1:(左)随着合成交叉数据量的增加,口语问答的得分持续提高,显著超过之前的最佳结果(由Moshi获得)。(右)合成语音文本交叉数据的流程。
1、介绍:
大型语言模型(LLMs)推动了自然语言处理技术的发展,展现出超越传统语言任务的能力,使得交互式聊天机器人和个性化数字助理等应用成为可能。然而,理想的人工智能助理不应仅仅依赖于文本,而基于声音的交互模式可以提供一种更自然、更直观的人机交互入口。传统的基于声音的对话系统将自动语音识别(ASR)、大型语言模型(LLMs)和文本到语音(TTS)模型以串行级联的方式组合,但这种方法在ASR和TTS过程中会存在信息损失,限制了模型捕捉和表达语音丰富细微差别的能力。
语音语言模型(SpeechLMs)已经成为达到构建能够端到端处理语音输入和输出的通用语音助手目的极为可能的方法。为了构建SpeechLMs,前人已经探索了几种方法,但存在一个主要挑战:与文本数据相比,语音数据规模相对较小。例如,FineWeb文本语料库提供了15万亿的高质量token,而VoxPopuli这样的大型无监督语音数据集则只能提供40万小时的语音,相当于360亿个token。这种差异限制了SpeechLMs相对于LLMs的能力。
为了解决这个问题,研究人员提出了一种通过从文本语料库合成语音-文本交叉数据来扩大语音-文本预训练规模的新方法。交叉数据是通过从文本语料库中采样文本并使用文本到token模型将其转换为语音token而得到的。这个方案避免了生成实际语音的过程,使得模型在不依赖大量语音数据集的情况下能够对语音语言模型进行大规模预训练。为了合成大规模的交叉数据,这篇工作使用现有的TTS数据集训练一个文本到token模型,生成了6000亿个交叉的语音-文本token数据,并将预训练数据规模扩展到1万亿个token。最后,通过在语音对话数据上对模型进行微调,研究人员开发了一个完全在语音领域运行的端到端语音聊天机器人。
本文的主要贡献包括:
- 创新性地提出了一种方法,可以从文本语料库中有效合成高质量的语音文本交叉数据,从而解决语音文本预训练中的数据规模限制问题。
- 将预训练扩充至1万亿个token,使用合成的交叉语音文本数据,显著提升了模型对语音语言建模和口语问题回答的能力。
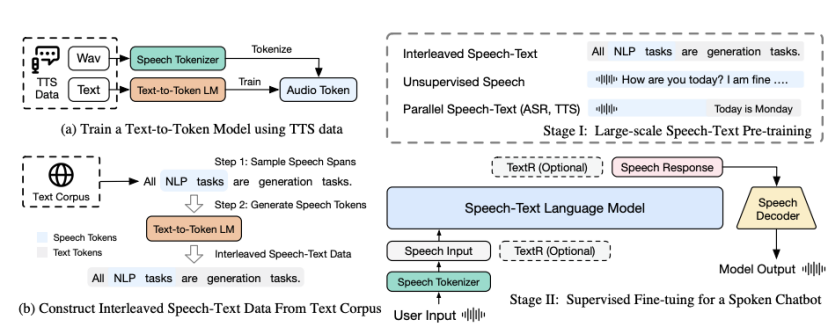
图2|这篇工作所提出方法的概览。首先,训练一个文本到token的模型来构建交叉的语音文本数据。其次,语音语言模型的训练包含两个阶段。在第一阶段,模型使用合成的交叉语音文本数据进行预训练。在第二阶段,模型通过使用语音对话数据集进行微调。
2、方法:
在本节中,将会介绍一个利用统一语音文本建模框架开发的端到端语音对话chatbot的方法。这个方法包含一个用于合成语音文本交错数据的技术,一种可以把预训练LLM拓展到语音领域的两阶段训练方法。这一套组合拳使得我们可以把大规模文本数据用于语音建模,高效地实现在一个模型里对齐语音和文本两种模态的信息。
2.1合成语音文本交叉数据
语音文本交叉数据指的是由语音和文本序列在词汇层面交错组成的token序列。例如:“今天是 <Speech 24> <Speech 5> ... <Speech 128> 天”。在语音文本交错数据上进行训练可以鼓励模型对齐语音和文本模态信息,从而有助于将基于文本的知识迁移到语音表征中。这篇工作提出了一种新颖且高效地使用现有文本数据集构建语音文本交叉数据的方法。该过程分为两个主要步骤:首先,训练一个文本到语音token的模型,该模型直接将文本转换成相应的语音token,从而免去了合成实际语音的必要,并显著提高了合成效率,使其成为一种实用且可扩展的大规模数据生成方法。接着,从现有的文本数据集中提取文本片段,并使用经过训练的文本到token模型转换成语音token。这一过程无需依靠对齐的语音文本配对数据集,即可高效且可扩展地创建语音文本交叉数据。
文本到token模型
研究人员基于标准的Transformer架构训练了一个1.5B的文本到token模型,以将文本转换成相应的语音token。为了准备训练数据,首先将文本到语音数据集中的音频转化为离散的语音token。然后训练文本到token模型,根据输入的文本预测这些语音token序列。优化目标是最小化基于相应文本输入的预测语音token的负对数似然:
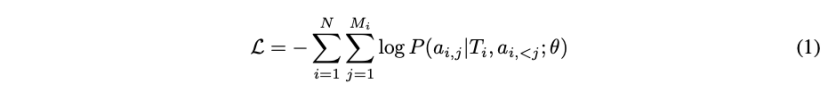
其中Ti是第i个输入文本,ai,j表示第i个样本中的第j个音频token,Mi是第i个语音token序列的长度,θ代表模型参数,N是训练样本的数量。
2.2模型训练
模型训练过程包含两个阶段。在第一阶段,模型在合成的交叉数据上进行预训练,以学习文本和语音之间的对齐任务。在第二阶段,使用语音对话数据进行微调,使得模型能够处理语音交互。
语言文本预训练
为了扩展LLM在语音文本任务中的能力,研究人员引入了一个语音文本预训练阶段。这个阶段使模型能够处理和表征离散的语音token。研究人员利用了以下四种数据类型:
• 交错语音文本数据:正如前文所描述的,这些数据集有助于文本和语音之间的跨模态知识转移。
• 无监督文本数据:研究人员使用了与GLM类似的多样化语料库,包含来自网页、维基百科、书籍、代码和研究论文的10T token,以保持模型的语言理解能力。
• 无监督语音数据:使用Emilia管道,研究人员收集了700k小时的高质量英语和中文语音数据,通过DNSMOS P.835得分高于2.75进行筛选,确保语音输入的多样性和清晰度。
• 监督语音文本数据:这包括自动语音识别(ASR)和文本到语音(TTS)数据,教会模型学习语音和文本之间的双向关系。
文本和语音均以离散token的形式表示。研究人员将每个批次中的文本数据量设置为30%,以保持语言能力。无监督语音和监督语音文本数据各训练一个epoch,而交叉数据填补了剩余的容量,实现了语言理解和语音处理的平衡。
总结:
这篇工作介绍了一种使用监督语义标记和合成交叉数据来扩展语音文本预训练新颖的方法。通过采用监督语音分词器和生成6000亿交叉数据标记,将语音预训练扩展到了1万亿标记,实现了语音语言建模和口语问答任务的最先进性能。研究人员还通过微调预训练模型开发了一个端到端的口语聊天机器人,展示了在对话能力和语音质量方面的优秀表现。

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









