






导读
随着智能物流需求日益增长,特别是“最后一公里”配送场景的精细化,传统地面机器人逐渐暴露出适应性差、精度不足等瓶颈。为此,本文提出了LogisticsVLN系统——一个基于多模态大语言模型的无人机视觉语言导航框架,专为窗户级别的终端配送任务设计。
©️【深蓝AI】编译
本文由paper一作——Xinyuan Zhang授权【深蓝AI】编译发布!
论文标题:LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
论文作者:Xinyuan Zhang, Yonglin Tian, Fei Lin, Yue Liu, Jing Ma, Kornelia Sara Szatmary, Fei-Yue Wang
论文地址:https://www.arxiv.org/abs/2505.03460
与现有研究多聚焦于长距离、粗粒度的目标定位不同,LogisticsVLN面向真实住宅场景中的窗户级精细导航任务,无需环境先验地图或特定训练。系统通过语言理解模块解析用户请求,利用轻量化的VLM完成楼层定位、目标窗口识别,并结合深度辅助机制进行视角选择与导航控制,最终实现精准投递。
论文还构建了VLD数据集,模拟复杂住宅环境下的300个任务,涵盖不同楼层、难度与指令风格。实验验证了系统的可行性,并通过模块级消融分析,评估了VLM在各子任务中的表现优劣。
这项研究不仅填补了空中VLN在终端配送中的空白,还为基础模型在真实智能物流系统中的部署提供了可行路径和有益启示。
1. 引入
在电子商务与城市化迅速发展的推动下,物流系统已成为现代社会中愈发关键的组成部分。特别是在终端配送环节,即将商品直接送达用户住所的最后一步,稳定、高效且以用户为中心的配送服务需求日益增长。
该研究认为,一种有前景的解决方案是利用具备智能体能力的无人机(Agentic UAVs)执行视觉-语言导航(VLN)任务,来满足终端配送的需求。
然而,传统的视觉-语言导航方法大多依赖于基于网络的模型,这些方法通常需要大量训练数据来实现泛化。现有基于无人机的VLN研究主要集中在长距离、粗粒度目标的导航任务上,因此难以满足对终端配送任务中高精度、细粒度导航的需求。虽然近期有研究尝试将基础模型用于地面机器人进行楼宇级配送,并取得了无需训练即可实现的零样本导航能力,但这种方法无法实现更精细的窗户级送达目标。
为了解决这些问题,该研究提出了LogisticsVLN系统,这是一个基于轻量级多模态大语言模型(MLLM)的无人机导航系统,具备良好的可扩展性,专为窗户级终端配送任务而设计。
该系统首先通过大语言模型(LLM)解析用户的自然语言请求,提取出目标窗户的关键属性;接着利用视觉-语言模型(VLM)实现楼层定位,引导无人机上升到合适的高度;在抵达目标楼层后,无人机再通过视角选择算法、目标检测VLM与决策VLM,在建筑周围探索寻找目标窗户。同时系统集成了一个深度感知辅助模块,提升操作的安全性。
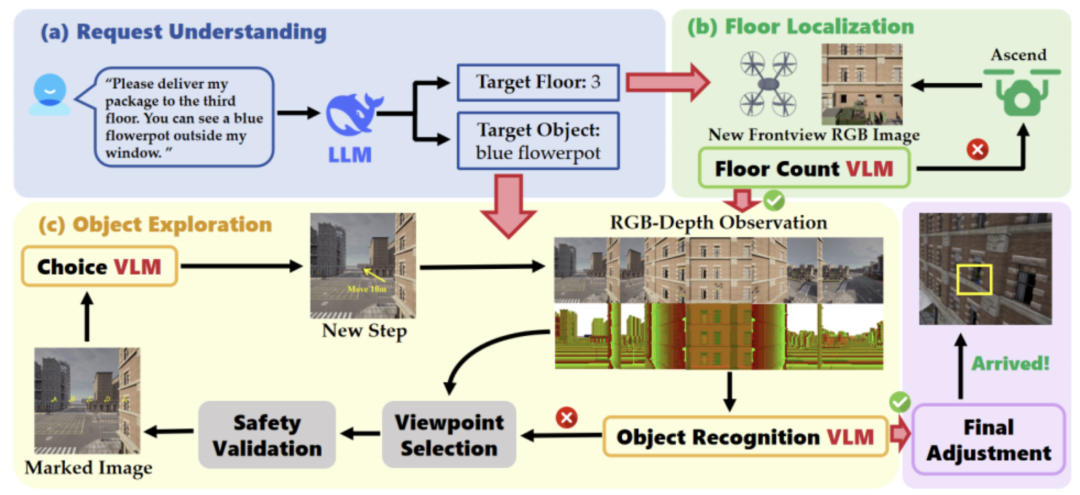
图1|全文方法总览©️【深蓝AI】编译
2. 具体方法与实现
1. 任务定义
该研究聚焦于面向窗户级终端配送的空中视觉语言导航任务。任务场景假设无人机从目标建筑附近出发,仅依据用户提供的自然语言请求,自主导航至指定窗户位置完成配送。整个过程中不依赖预先构建的环境地图,更贴近现实中住宅区域缺乏详尽室内结构信息的实际场景。
在执行任务过程中:
● 无人机以离散时间步推进,每一步都会从传感器(包括多个方向的 RGB-D 摄像头)获取环境观测;
● 系统融合当前观测信息与语言描述,通过策略模型动态规划下一步动作;
● 最终目标是在满足空间安全约束的前提下,使无人机抵达目标窗户附近的邻域区域,实现高精度包裹投递。
2. 系统总览
该系统部署于具备智能体能力的无人机平台上。无人机配备了五组朝向不同角度(前、左前、右前、左侧、右侧)的 RGB-D 摄像头,实现对周围环境的半环绕感知。
配送流程从自然语言请求开始,系统首先使用内嵌的大语言模型解析请求信息;随后由视觉语言模型模块完成楼层定位和目标窗户识别。三个 VLM 被分别用于楼层估计、对象识别和动作决策,并通过一个深度辅助模块增强空间理解能力。当目标窗户被成功检测到后,无人机根据这些模块的引导精准调整位置,完成包裹的窗户级配送。
2.1 请求理解
用户的请求文本通常包含了目标窗户的位置描述、所在楼层、附近的显著物体(例如绿色花盆)以及一些无关或干扰性内容。
该系统采用 DeepSeek-R1-Distill-Qwen-14B 模型,结合三步链式推理(Chain-of-Thought)设计的提示词模板,对请求进行解析。通过这一过程,系统提取出两个关键信息:目标楼层编号和显著参照物,为后续模块的环境感知和决策提供支持。
2.2 楼层定位
该模块旨在引导无人机到达目标所在楼层高度,具备以下特点:
● 使用一个基于视觉语言模型构建的楼层计数器(Floor Count VLM);
● 无人机从建筑底部依次飞行到预设的垂直高度点,并在每个高度拍摄正前方图像;
● 模型分析图像中可见楼层数,实时更新无人机当前位置的楼层估计;
● 基于当前估计结果与目标楼层的对比,系统决定:
○ 继续上升;
○ 或进入楼层内微调阶段;
一旦到达目标高度,无人机锁定该楼层,维持固定飞行高度,进入环绕探索阶段。
2.3 目标探索
由于该任务中没有预构建地图,无人机需依靠自身感知能力探索目标窗户。为此,系统设计了一个探索模块,结合了对象识别 VLM、动作选择 VLM 和深度辅助模块。
对象识别: 系统将五个方向的 RGB 图像输入对象识别 VLM,并结合显著参照物的描述,判断目标窗户是否在视野内。如果识别成功,系统返回目标窗户的边界框,并利用深度信息计算一条安全的接近路径,确保无人机能够精准且安全地靠近目标。
视角选择: 若当前图像中未检测到目标窗户,系统会基于深度图评估各个摄像头视角的探索潜力,选出最有可能发现目标的视角继续移动。该过程通过分析深度图中的显著深度变化区来推断建筑转角等潜在视野突破口。
动作选择: 一旦选定新的视角,系统会在图像上标记若干探索方向,结合深度信息估算每个方向的安全行进距离,并将这些信息连同任务描述送入动作选择 VLM,选择最佳的移动方向与距离,从而实现连续、高效且避障的探索行为。
3.实验
为验证系统性能,该研究在 CARLA 模拟器中构建了一个名为 VLD 的视觉语言配送数据集,覆盖22类建筑,共300个窗户级别配送任务。任务具有多样的目标类别、楼层分布和不同难度等级,通过模拟不同用户请求风格,进一步提升数据集的语言多样性。
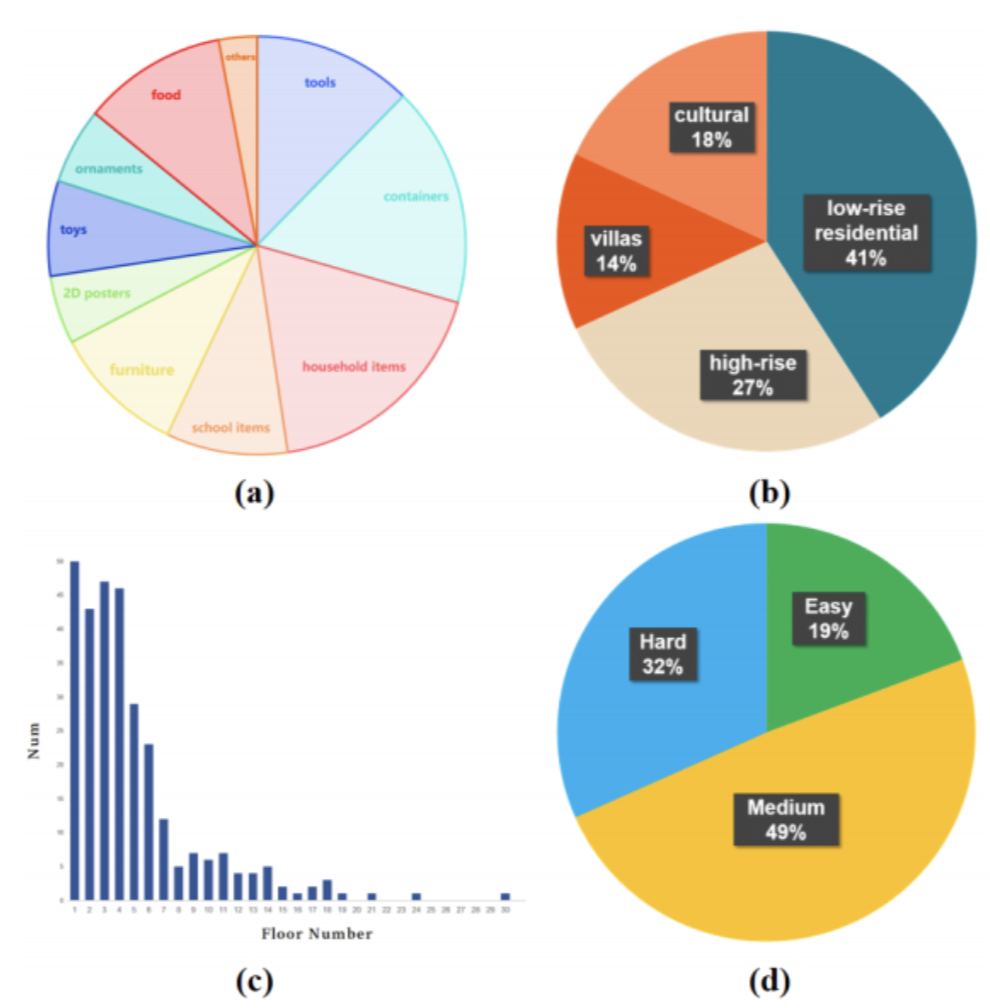
图4|数据集示例©️【深蓝AI】编译
在系统评估中,研究者选用了三种轻量级视觉语言模型(VLM)进行对比。结果显示,Qwen2-VL 模型表现最佳,在任务完成率与导航效率上均优于 LLaMA-3.1 和 Yi-VL 模型。Yi-VL 模型在任务执行中频繁拒绝提供明确的楼层判断,导致定位失败率较高,而 LLaMA-3.1 也在对象识别与楼层判断上表现不稳定,尤其容易被颜色等视觉属性干扰,误识别目标。
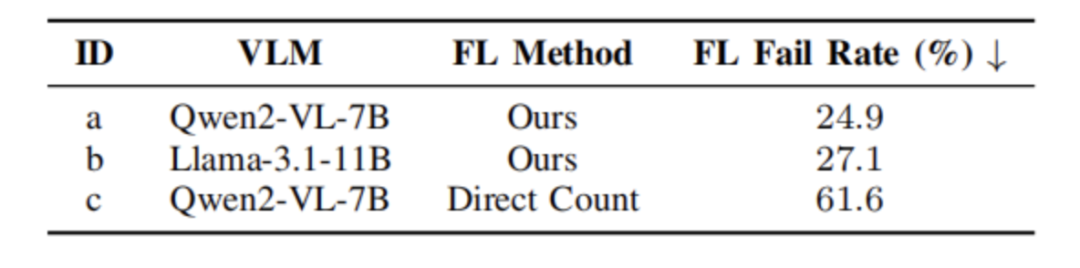
图5|不同楼层定位结果©️【深蓝AI】编译
为进一步验证系统中各模块的效果,该研究还设计了多项消融实验。例如,与传统楼层计数方式相比,自研的楼层定位方法显著降低了定位失败率,提高了系统的稳定性。在探索策略方面,深度驱动的视角选择算法相比于随机或默认策略,在成功率和路径效率上也有明显优势,尤其在需要绕行建筑多面的“困难任务”中表现突出。
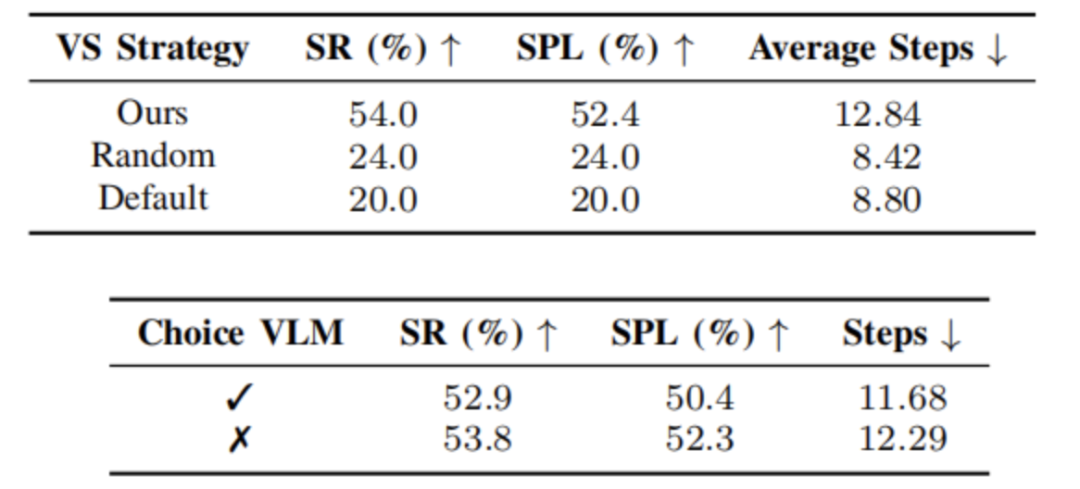
图6|消融实验结果©️【深蓝AI】编译
尽管动作选择模块(Choice VLM)在整体指标上提升有限,但在视角选择不理想的情况下,其策略性判断能有效避免死锁和碰撞,保障任务安全完成。
总结
这项研究提出了一个叫 LogisticsVLN 的系统,目标是让无人机能够自动把包裹送到用户家窗户前,整个过程不需要提前训练、也不需要地图。系统主要依靠“多模态大模型”来理解语言、识别图像,并做出导航决策。
为了测试这个系统是否真的有效,研究团队在一个逼真的虚拟城市环境里,设计了一个专门的数据集,模拟了各种建筑、不同风格的用户请求和复杂的送货场景。实验结果表明,LogisticsVLN 不仅能完成任务,还能较好应对楼层定位、窗户识别等挑战。
更重要的是,研究者还对系统中的每个关键环节做了分析,比如:哪种模型更适合识别楼层?哪种算法能更聪明地选择视角来探索?这些分析帮助大家更清楚地了解大模型在真实配送任务中的优点与不足。
未来,该团队计划继续优化系统结构,让它能更充分地发挥大模型的能力,并探索如何把这套方案真正用在现实中的空中配送服务中。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









