









-
作者:Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, Bernadette Bucher
-
单位:波士顿动力人工智能研究所,佐治亚理工学院
-
原文链接:VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation (https://openreview.net/pdf?id=gdw1zUTABk)
-
视频演示:https://naoki.io/portfolio/vlfm
-
代码链接:https://github.com/bdaiinstitute/vlfm
主要贡献
-
VLFM提出了一种零样本方法,能够在没有任务特定训练、预构建地图或环境先验知识的情况下进行目标驱动的语义导航。
-
利用预训练的视觉语言模型直接从RGB图像中提取语义值,避免了将环境视觉线索转换为文本的过程。通过结合视觉和语言模型,VLFM实现了空间感知的联合语义推理。
-
使用视觉语言模型生成的语言感知的价值图来识别最有价值的探索前沿,从而更高效地找到目标对象。
-
在Gibson、Habitat-Matterport3D和Matterport3D数据集上均取得了最先进的成果。成功在波士顿动力公司的Spot移动操作平台上部署了VLFM,并在办公室大楼内实现了目标对象的导航。
研究背景
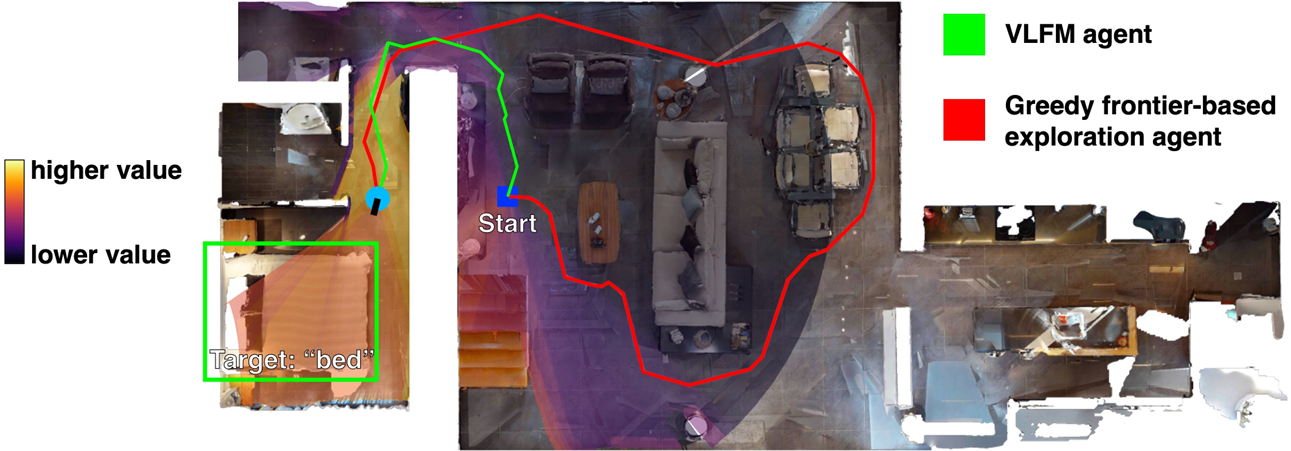
研究问题
论文主要解决的问题是如何在未知环境中实现零样本语义导航,即智能体在没有任务特定训练、预构建地图或环境先验知识的情况下,能够导航到目标语义对象。
研究难点
该问题的研究难点包括:
-
如何在没有任务特定训练的情况下,利用视觉语言模型高效地探索环境;
-
如何在不依赖对象检测器和语言模型的情况下,评估前沿边界;
-
如何在真实世界中部署零样本导航系统。
相关工作
该问题的研究相关工作包括:
-
基于强化学习的语义导航方法、
-
从演示中学习的语义导航方法、
-
预测语义 top-down 地图的方法等。
这些方法通常需要大量的任务特定训练数据,并且在真实世界的部署中存在局限性。
研究方法
论文提出了视觉语言前沿地图( VISION-LANGUAGE FRONTIER MAPS,VLFM),用于解决零样本语义导航问题。
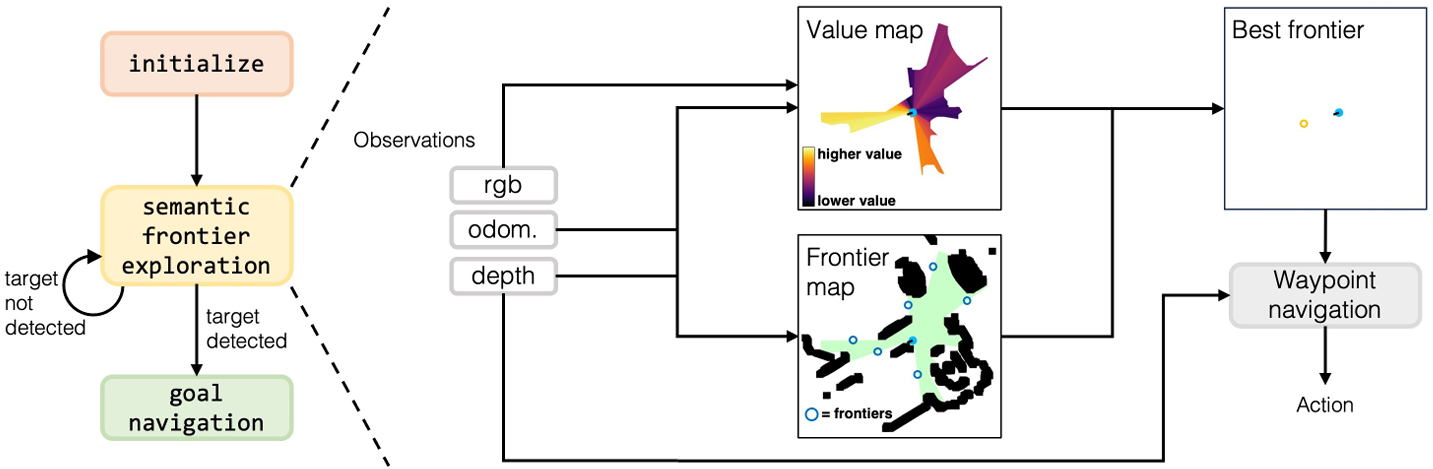
前沿边界生成
利用深度和里程计观测数据构建一个自上而下的2D障碍物地图,识别出已探索区域的边界作为前沿边界。
将当前深度图像转换为点云,过滤掉过短或过高的点,转换到全局坐标系后投影到2D网格上,识别每个边界的中点作为潜在的前沿边界点。
价值地图生成
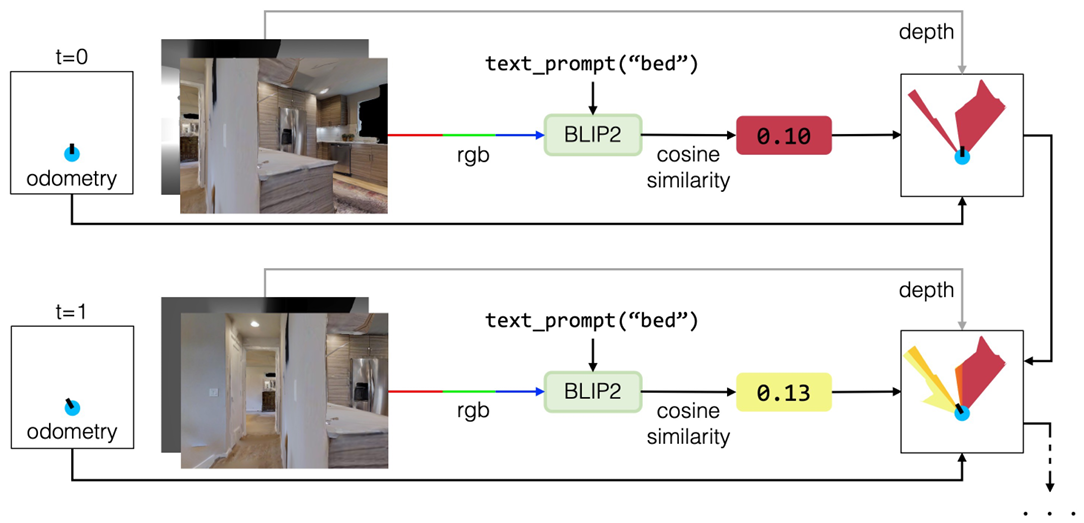
生成一个价值地图,该地图为已探索区域内的每个像素分配一个值,量化其在定位目标对象方面的语义相关性。
使用预训练的BLIP-2视觉语言模型计算当前RGB图像和包含目标对象的文本提示之间的余弦相似度得分,将这些得分投影到价值地图的相应通道上。
目标检测
使用预训练的对象检测器(如YOLOv7和Grounding-DINO)检测目标对象实例。如果检测到目标对象,则使用Mobile-SAM确定对象上距离智能体最近的点作为目标航点。
航点导航
使用Variable Experience Rollout(VER)算法训练的PointNav策略进行航点导航。PointNav策略仅依赖于视觉观测和里程计输入,不需要对环境的语义理解。
实验设计
数据集
在Habitat模拟器中使用三个不同的3D扫描数据集进行评估:Gibson、HM3D和MP3D。
-
Gibson数据集包含1000个场景,分布在5个场景中;
-
HM3D数据集包含2000个场景,分布在20个场景中,涵盖6个对象类别;
-
MP3D数据集包含2195个场景,分布在11个场景中,涵盖21个对象类别。
指标
评估指标包括成功率(SR)和按路径长度加权的成功率(SPL)。SPL通过比较智能体的路径长度与从起点到最近目标对象类别的最短路径长度来评估智能体路径的效率。
基线方法
将VLFM与几种最先进的零样本对象导航方法进行比较,包括CLIP on Wheels(CoW)、ESC、SemUtil和ZSON。
此外,还将VLFM与一些监督学习方法进行比较,如PONI、PIRLNav、RegQLearn和SemExp。
结果与分析
基准结果
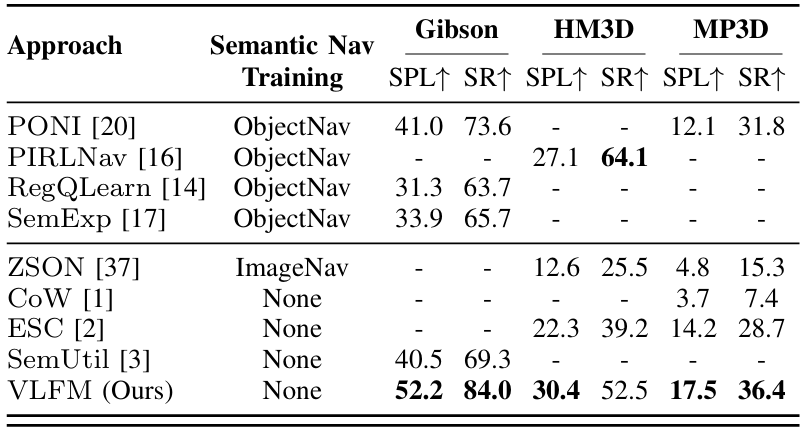
VLFM在所有基准测试中均显著优于其他零样本方法,并在Gibson和MP3D数据集上超越了直接在这些数据集上训练的方法。
-
在Gibson数据集上,VLFM的成功率和SPL分别提高了19.2%和19.0%;
-
在MP3D数据集上,分别提高了5.4%和4.6%。
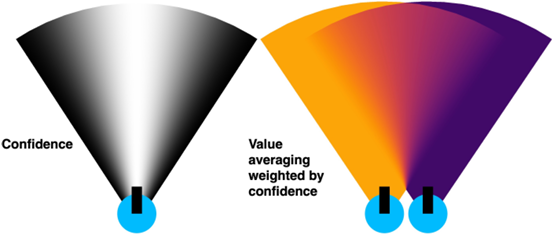
消融实验
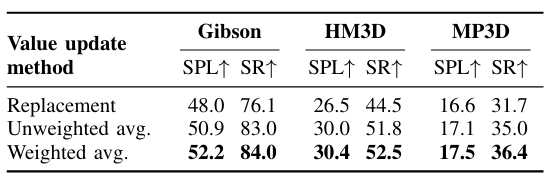
探讨了不同值更新方法对VLFM性能的影响。结果表明,加权平均方法在所有数据集上均优于替换方法和未加权平均方法。
真实世界部署


在波士顿动力公司的Spot移动操作平台上部署了VLFM,成功展示了在真实世界中导航到目标对象的能力。
尽管由于Spot的深度感知范围有限,使用了ZoeDepth深度估计模型来近似检测目标的航点,但VLFM仍能有效地导航到目标对象。
总结
论文提出了VLFM,一种用于新环境中目标驱动语义导航的零样本框架。使用预训练模型进行空间感知的联合视觉语言语义推理,并在新前沿航点选择中进行目标驱动导航。
VLFM在模拟的3D家庭环境中实现了最先进的零样本导航性能,并在Spot机器人平台上证明了其在真实世界场景中的可行性。


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









