









3 经常问的问题
3.1 一般的
对对象进行排序的最佳方法是什么?是否需要从前到后的对象提交,或者考虑到平铺架构,这是否没有必要?
通过 A5X 和更新的 Adreno GPU 中包含的 LRZ 和其他分箱优化,排序对性能的影响较小。也就是说,仍然建议尽可能从前到后排序,并在所有 Adreno 平台上保持最佳性能。
是否有可用于其他 Snapdragon 硬件模块的“无复制”路径?
通过 Android 本机硬件缓冲区 ( https://developer.android.com/ndk/reference/group/a-hardware-buffer )可用于 CPU <-> GPU <-> DSP 的路径。
TEX 与 ALU 的最佳比例是多少?
在 A5X GPU 上,全速率下每个片段一 (1) 个纹理相当于 16 个全精度 ALU。
什么是三角形建立率?
一 (1) 个主/时钟。
VS 中的顶点流和属性获取哪个更好?
首选顶点流。Adreno GPU 具有用于获取和解码这些数据的专用硬件。
可以使用专用视频内存吗?
没有应用程序开发人员可以控制的专用视频内存。图形驱动程序将分配它拥有和管理的系统内存部分。
我应该使用多少个遮挡查询?
活动数量不应超过 512 个。结果通常会有三 (3) 帧延迟。
遮挡查询性能如何?
查询的性能与 bin 的数量有关。bin 计数(来自分辨率、MSAA 等)越高,查询的成本就越高。
Adreno GPU 中遮挡查询的建议用法是尽可能以直接模式运行它们。确保发生这种情况的一种方法是在刷新后一批中发出对帧的所有查询,例如渲染不透明 -> 渲染半透明 -> 刷新 -> 渲染查询 -> 切换 FBO。
驱动程序具有启发式功能,可以理解仅向地面发出了查询并切换到直接模式。查询的开销将在Snapdragon Profiler中显示为较高的“% CP Busy”指标。
在某些向分箱表面发出多次查询的测试用例中,CP 开销可能会跃升至 20-40%,而在直接模式下则降至 4-6%。
Adreno GPU 中的计时器查询是如何计算的?
计时器查询是在整组图块和分箱上计算的。例如,假设我们有 50 个绘制调用,并且渲染目标的分辨率需要 8 个图块才能渲染。我们还假设我们想要测量绘制调用 10 并使用计时器查询来检测它。
50 个绘制的整个命令流将被捕获并通过分箱过程运行以生成可见性流(请参阅基于图块的渲染)。在渲染过程中,绘制调用将根据每个图块的可见性流进行渲染。即使绘制调用 10 的几何图形仅对一个图块有贡献,它也会在每个图块上产生少量开销(在处理可见性流时)。此开销和实际渲染时间将累积并显示在生成的计时器查询中。
笔记
上面提到的开销很小(2-5μs),但如果绘制调用计数很高并且绘制存在于许多图块中,则开销可能会增加。从 A5X 开始,添加了对可见性流的 GPU 优化,通过“修剪”对图块没有贡献的绘制调用流的末尾来减少这种开销。如果像全屏通道这样的东西作为对渲染目标的最后一次绘制调用发出,则这种优化可能会无效。
用户剪辑平面的性能如何?
坏的。如果必须剪辑基元,一 (1) 个基元/时钟将变成 50 个周期。它还将使整个管道停顿。
alpha 测试与 alpha 混合哪个性能更好?
从吞吐量的角度来看,它们是相同的。对于单个样本,它们都被保守地拒绝。不过,由于 BW 限制,一旦打开 MSAA,tjeu 就不会被拒绝,只能进行后期 Z 测试。
最好的单通道立体声?纹理数组?需要GS吗?
GL_OVR_多视图。驱动程序将为您捕获命令并重播它们。没有 GPU 优势;这可以节省 CPU 时间。
片段着色器中动态分支的行为是什么?
波将停止,直到其中的每个线程都准备好进行。一旦每个线程准备好,两个分支都会被采用。结果是使用从分支生成的掩码进行的选择。
3.2 LRZ
有关 LRZ 的更多信息,请参阅低分辨率 Z 通道。LRZ 在 A5X 及更高版本上可用。
LRZ被禁用的原因是什么?
-
在片段着色器中写入深度
-
任何需要直接渲染的情况
-
使用辅助命令缓冲区 (Vulkan)(Snapdragon 865 及更新版本不会根据此标准禁用 LRZ)
LRZ 缓冲区和可见性流可以存储和重用吗?
LRZ 缓冲区无法通过 Vulkan、DirectX 或 OpenGL ES 显式创建或导出。
如果使用discard/clip,对LRZ有何影响?
在LRZ中不会有任何影响。在所有情况下都会达到全分辨率 Z。
3.2 纹理和格式
哪种深度缓冲区格式可提供最佳性能?
如果可能,请使用 D16。如果需要更高的精度并且不使用模板,建议使用 D32 作为 D24。D24_S8 将在 GMEM 中占用与 D32 相同的空间,但精度较低。否则,也建议使用 D24_S8。UBWC 支持所有这些格式。
纹理保持压缩/解压缩的缓存级别是多少?
ASTC 在 L2 中压缩并在 L1 中解压缩。ETC 格式在 L1 中保持压缩状态。
对于 8 位纹理查找,浮点还是半浮点性能更高?
过滤示例指令后,它将具有 8 位纹理的 16 位每个组件值。如果将纹理查找的结果分配给 highp 向量,它将是全精度的。然而,过滤后从纹理管道出来的仍然是16位。
从一半转换为浮动不需要花费任何东西。
1010102 与 111110 格式的性能如何?
两种格式的性能均优于 FP16。
1010102 有一个硬件“快速路径”,这将使其性能比 111110 稍好一些。
3.3 平铺建筑
您是否了解平铺和分箱过程如何工作的详细信息?
有关 Adreno 中平铺的高级概述,请参阅基于平铺的渲染。
哪些条件会触发使用 FlexRender 进行直接渲染?
GPU 硬件修订版和驱动程序版本之间存在一些细微差异,但以下是常见的:
-
使用曲面细分或几何着色器
-
少量顶点和/或绘图
-
顶点着色器中纹理样本与顶点的高比例
笔记 跟踪捕获中的Snapdragon Profiler “渲染阶段”指标可以显示每个表面的信息,其中包括用于给定表面的渲染模式。
执行分箱时是否使用完整的顶点着色器?
在合并过程中,使用了专门的着色器。这是由编译器从原始着色器生成的,并且仅使用接触位置相关数据的部分。完整的 VS 着色器稍后在渲染通道中执行。
分箱是否受到片段 Z 遮挡的影响?
合并不会受到全分辨率 Z 遮挡的影响。从 A5X GPU 开始,LRZ 传递发生在分箱中,并且可以丢弃图块范围内的贡献。
分箱的 CPU 成本是多少?
CPU 成本可以忽略不计。分箱过程在 GPU 中执行,生成的可见性流(指示哪些绘制调用影响哪些分箱)被放置在系统内存中,以便 GPU 在渲染通道中使用。
如果图元跨越多个图块,GPU 是否会在图块边界处插入合成顶点?
完整的图元将按图块进行光栅化(图块边界处不添加顶点)。
如果存在大量此类情况(可能在地面渲染中等),建议对对象进行抽取。
3.4 Vulkan
使用 Vulkan 辅助命令缓冲区是否会对性能产生影响?
是的。在 A5X 及更高版本的 GPU 上,辅助命令缓冲区会导致 LRZ 被禁用。
使用推送常量是否有性能优势或成本?
在 A5X 上,不建议使用 GPU 推送常量。
A6X GPU 上的硬件更改解决了许多问题,并且在处理频繁更改的数据时,推送常量的性能会更好。
静态与动态?
使用动态状态时,性能没有显着差异,因此可以根据需要使用任一状态。
SSBO、UBO、纹理获取的推荐用法是什么?
这取决于缓冲区的使用情况和大小。
如果着色器用法为“只读”,切勿使用描述符类型或 STORAGE_BUFFER 或 STORAGE_IMAGE。从 SSBO 或图像缓冲区读取数据实际上变成了纹理获取,因此性能/延迟将相似。
每个 SP 有 8k 的恒定内存,因此从适合该 8k 的 UBO 读取的性能比 SSBO 或图像更好。然而,如果 UBO 数据大于 8k,情况就会发生变化,因为 UBO 数据将由每个波形直接从系统内存读取,而没有 SSBO 和图像所具有的纹理缓存的优势。
推荐的采样器类型是什么?
建议使用 VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER 因为 Adreno GPU 在 Bindless 模式下的工作方式。
当使用组合图像采样器时,GPU可以使用性能更高的Bindless模式。当使用单独的采样器时,它将回落到较慢的模式。
性能增量显示单独采样器的填充率下降了 2-5%。
如何确保 Vulkan 子通道正确合并?
必须使用特定的设置和访问标志,以便子通道可以正确合并。访问Vulkan 子通道以了解有关这些标志的更多信息。
要验证子通道是否正确合并,请使用Snapdragon Profiler “渲染阶段”指标和/或启用Vulkan Adreno 层,该层将标记无法合并的子通道。
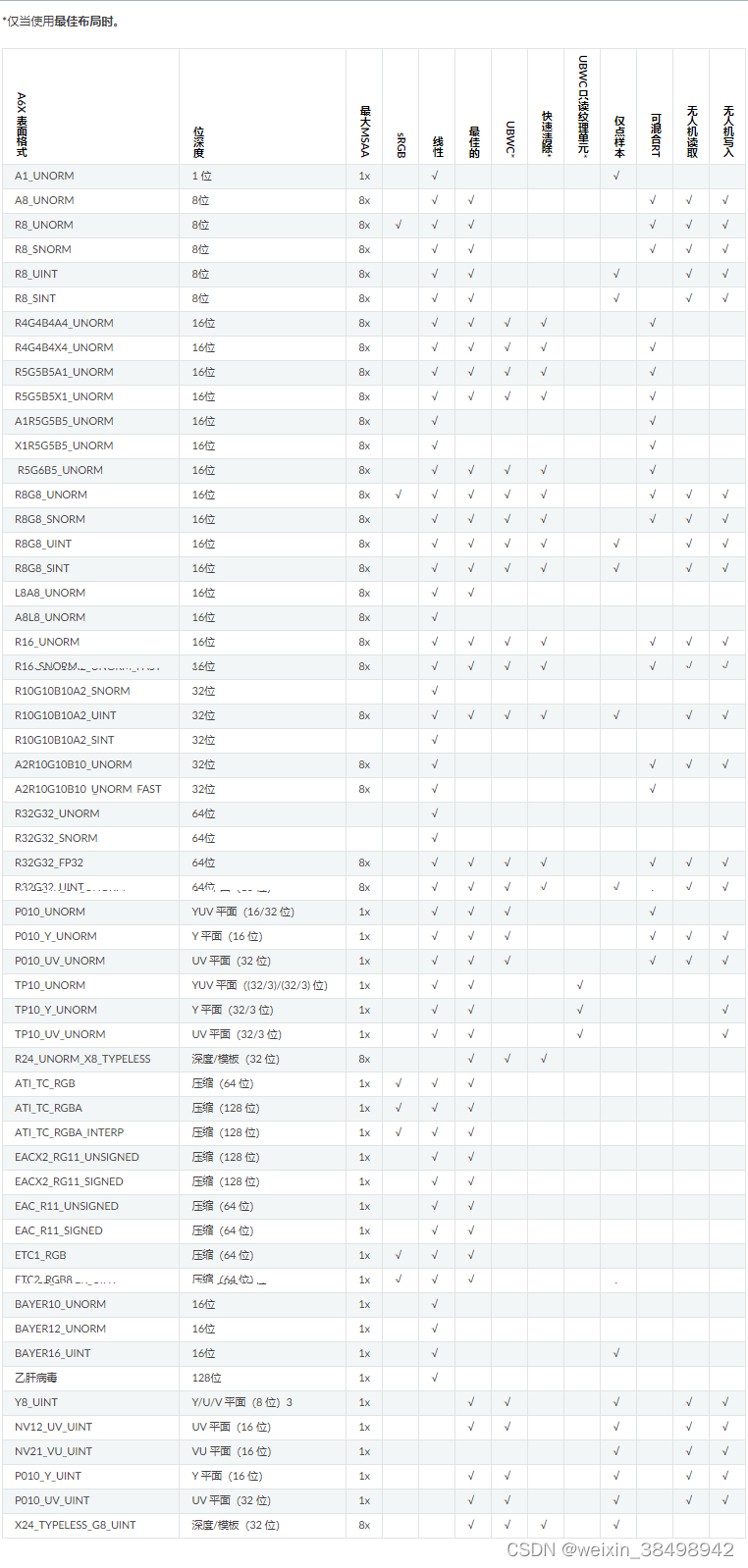
4 规格表
4.1 纹理格式
下表描述了每种支持的纹理格式的可用功能。
A5X:

A6X:














 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









