











论文地址:https://navila-bot.github.io/static/navila_paper.pdf
项目地址:https://navila-bot.github.io/
本文提出了一种名为NaVILA的机器人导航模型,旨在解决视觉语言导航问题,并允许机器人在更具挑战性和杂乱的场景中进行导航。
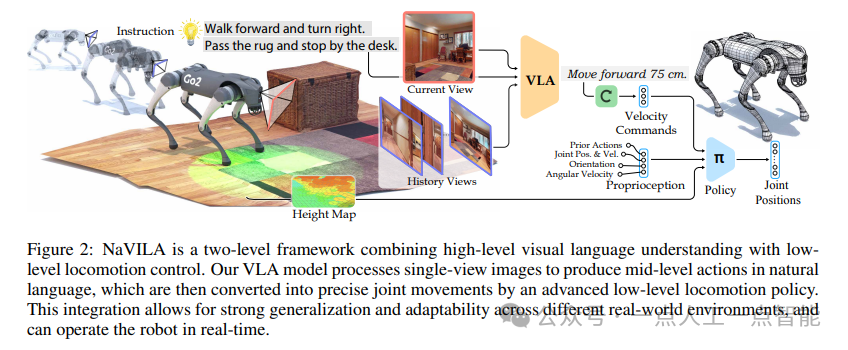
该模型采用了两层框架,将视觉、语言和行动模型(VLA)与运动技能相结合。通过预先生成具有空间信息的语言中间动作(例如,“向前移动75厘米”),然后将其作为输入传递给视觉运动强化学习策略以执行任务。
实验结果表明,NaVILA在现有基准测试上取得了显著改进,并且在新的IsaacLab基准测试中也表现出了相同的优势,这些基准测试包括更真实的场景、低级控制和真实世界中的机器人实验。
01 论文方法
1.1 方法描述
本文提出的NaVILA模型是一种结合了视觉语言理解和低级运动控制的系统,用于实现在现实世界中的导航任务。该模型采用了高效的预训练视觉语言模型(VLM)来处理视频输入,并将其与低级运动控制器相结合,以实现精确的关节运动控制。这种模型设计的优势在于其能够适应不同的环境并具有较强的泛化能力。
1.2 方法改进
在本文中,作者通过以下方式改进了传统的视觉语言导航模型:
1)使用图像编码器:传统的视觉语言导航模型通常使用图像编码器来处理视频输入。然而,由于缺乏大规模、高质量的视频文本数据集,这些模型的性能受到了限制。因此,本文采用了基于图像的语言模型(如VILA),它们在理解连续视频序列方面表现出色。
2)基于历史观察的导航指令:本文提出了一个基于历史观察的导航指令,将当前观察和历史观察分别表示为不同类型的标记。这样可以更准确地捕捉到导航任务中不同类型信息的重要性。
3)数据融合:为了提高模型的泛化能力和避免过拟合,本文利用多种来源的数据进行了融合,包括真实人类行为视频、仿真数据以及辅助导航数据等。
1.3 解决的问题
本文主要解决了以下几个问题:
1)提高视觉语言导航模型的泛化能力:通过引入基于历史观察的导航指令和多源数据融合策略,使得模型在不同场景下表现更加出色。
2)实现连续动作的预测:通过将连续动作分解成多个离散的动作,降低了模型的复杂度,提高了实际应用的效果。
3)提高模型的效率:通过单阶段训练策略,减少了训练时间,并且可以直接在环境中探索新的策略,从而提高了模型的效率。


02 论文实验
本文介绍了NaVILA在虚拟和真实环境中的导航性能的三个实验,并与现有方法进行了比较。
第一个实验是在虚拟环境中评估NaVILA的导航性能。
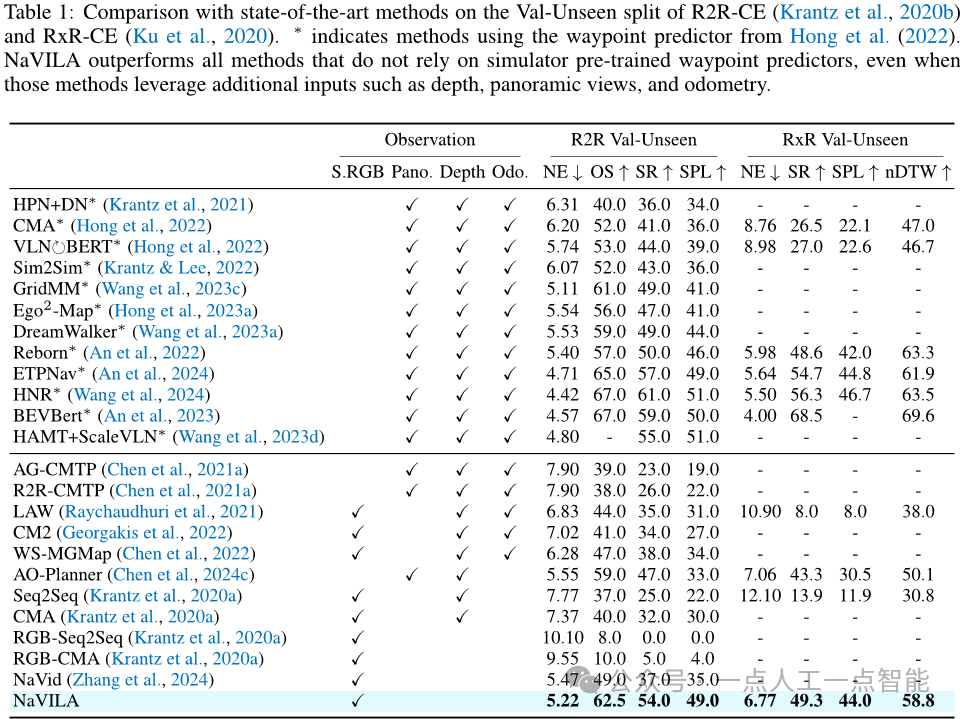
作者使用了两个广泛使用的基准数据集:R2R和RxR。他们使用了常用的评价指标来评估NaVILA的表现,包括导航误差(NE)、成功率(SR)、路径长度加权成功率(SPL)等。
结果表明,NaVILA在单个模型下显著优于所有基线方法,在两个基准测试中都取得了更好的表现。此外,该实验还展示了NaVILA的泛化能力,即使仅使用单个RGB视图输入,也可以实现与使用全景视图、机器人位姿或仿真预训练的路标预测器相当甚至更好的效果。
第二个实验是在模拟器中评估NaVILA的足式机器人导航性能。
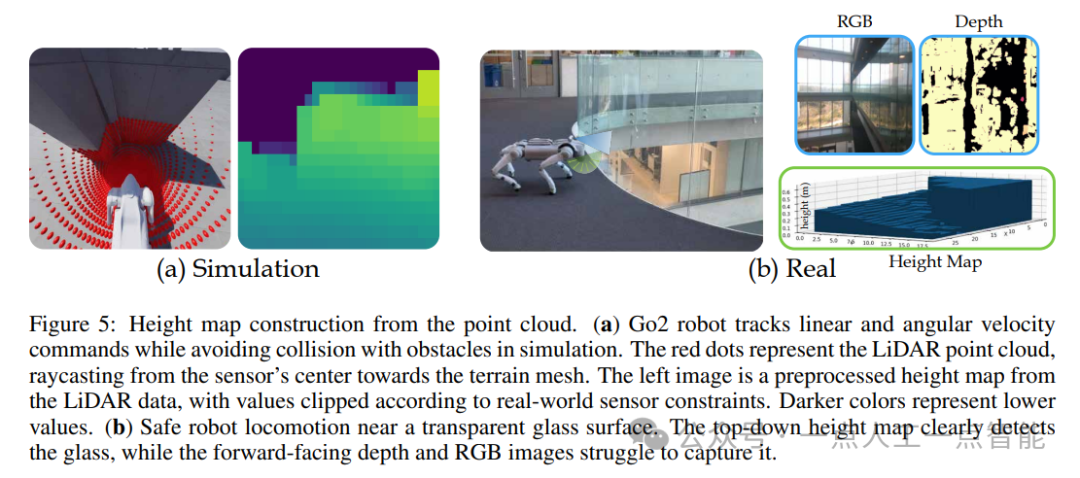
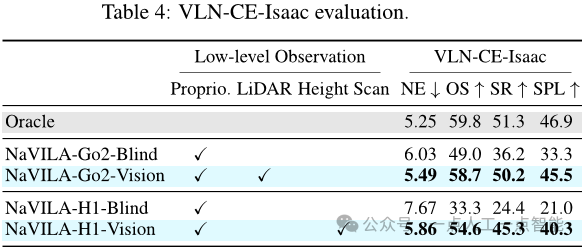
由于现有的足式机器人导航基准不适用于足式机器人,因此作者创建了一个新的高保真度基准,名为VLN-CE-Isaac。该基准使用Isaac Sim模拟器捕捉了详细的机器人关节运动和与环境的交互,可以全面评估整个导航Pipeline,从高级规划到精确的机器人执行。作者在Isaac Sim上部署了相同场景,并选择了高质量的可通行轨迹以确保现实的导航场景。他们使用相同的指标对性能进行评估,并将NaVILA模型应用于Unitree Go2和H1机器人。
结果表明,NaVILA的视觉策略比盲策略具有更高的成功率,这归因于其优越的障碍物避免能力。此外,与Oracle低级策略相比,NaVILA的成功率也有所下降,这突显了基准的挑战和现实性增加。
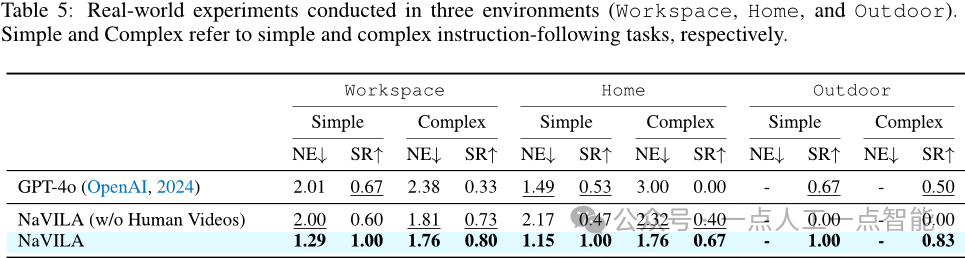
第三个实验是在真实世界中评估NaVILA的导航性能。
作者在一个真实的环境中进行了25个指令的实验,每个指令重复三次,涵盖了简单和复杂的任务,并覆盖了三种类型的环境:工作区、家庭和户外开放环境。他们使用标准指标(成功率和导航误差)并将其与GPT-4o进行了比较,后者是一种著名的VLM,以其强大的泛化能力而闻名。
结果表明,NaVILA在所有环境下都显著优于GPT-4o,并且通过添加人类视频的帮助,NaVILA可以在户外场景中更好地泛化并实现更高的成功率。他们的定性结果也在文中展示。
综上所述,本文展示了NaVILA在虚拟和真实环境中的导航性能,并证明了它在不同场景下的优势。
03 方法创新点
本文的方法创新点在于提出了NaVILA这一两层框架,它能够将视觉语言动作模型(VLAs)与行走技能相结合,用于通用导航任务。
具体来说,NaVILA使用了以下三个方面的创新:
1)分离低级执行:通过将低级执行从VLAs中分离出来,同一组VLAs可以应用于不同的机器人,只需更换低级策略即可。
2)中级语言指令:将动作表示为中级语言指令,使得训练数据来源更加丰富,包括真实人类视频和推理问答任务等,从而增强了推理能力并促进了泛化。
3)双频率设计:NaVILA采用了双频率设计,其中VLAs是一个大型且计算密集型的模型,在较低的频率下运行;而实时的低级行走策略则负责处理复杂的障碍避免问题,增加了整体的鲁棒性。
此外,本文还提出了一些策略来训练VLAs,例如整合历史上下文和当前观察到的信息、创建专门的导航提示以及引入精心挑选的数据集组合等,这些策略有助于将通用的图像基VLM细调为专门用于导航的代理,并同时在通用的视觉语言数据集上进行训练,保持其广泛的一般化能力。
04 未来展望
本文提出的方法具有很高的实用性和可扩展性,但仍有一些未来的研究方向值得探索。例如,可以进一步研究如何提高NaVILA的效率和速度,以适应更多的应用场景。此外,还可以探索如何将NaVILA与其他技术结合,如强化学习或深度强化学习,以实现更高水平的自主导航。最后,可以考虑将NaVILA扩展到其他类型的机器人,如四足机器人或人形机器人,以满足更多实际应用的需求。


















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











