







上期学习了怎样汇总单因素 Cox 回归的结果,这期学习单因素 Logistic 回归分的汇总,由于使用的是 coxph****和 glm 两个函数结果的展示有所不同,因此整理过程略有不同,但是提取的信息是一致的。
01 单因素 Logistic 回归分析方法
Logistic 回归模型是一种概率模型它是以某一事件发生与否的概率 P 为因变量,以影响 P的因素为自变量建立的回归模型,分析某事件发生的概率与自变量之间的关系,是一种非线性回归模型。
Logistic 回归模型适用适用于因变量为:
-
二项分类
-
多项分类(有序、无序)的资料。
library(rms)#可实现逻辑回归模型(lrm)
library(survival)
library("survminer")
data("lung")
head(lung)
table(lung$status)
1 2
63 165
#Error in eval(family$initialize) : y values must be 0 <= y <= 1
lung$status=ifelse(lung$status==1,0,1)
table(lung$status)
0 1
63 165
fit<-glm(status~sex,family = binomial, data =lung)
summary(fit)
Call:
glm(formula = status ~ sex, family = binomial, data = lung)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.8271 -1.3333 0.6462 0.6462 1.0291
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.5614 0.4852 5.279 1.3e-07 ***
sex -1.1010 0.3054 -3.605 0.000312 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 268.78 on 227 degrees of freedom
Residual deviance: 255.46 on 226 degrees of freedom
AIC: 259.46
Number of Fisher Scoring iterations: 4
将 glm 的结果与 coxph 的结果对比,glm 的结果没有在 summary() 之后显示出来,需要我们单独计算,在之前 Logistic 回归分析中已经介绍过了,这里再次追述一次,如下:
fit<-glm(status~sex,family = binomial, data =lung)
sum<-summary(fit) ##提取所有回归结果放入sum中
OR<-round(exp(coef(fit)),2) ##1-计算OR值保留两位小数
(Intercept) sex
10.43 0.37
sum<-sum$coefficients[,2] ##提取所有回归结果放入sum中
Intercept) sex
0.5513927 0.3529752
SE<-sum$coefficients[,2] ##2-提取SE
(Intercept) sex
0.5513927 0.3529752
lower<-round(exp(coef(fit)-1.96*SE),2) # #3-计算CI保留两位小数并合并
(Intercept) sex
3.54 0.19
upper<-round(exp(coef(fit)+1.96*SE),2)
(Intercept) sex
30.74 0.75
P<-round(sum$coefficients[,4],2) # #4-提取P值
(Intercept) sex
0.00 0.01
下面是单因素 Cox 回归的 summary(),显然有很大区别,因此在整理结果时我们需要重写一个简单函数来获取批量回归的结果。
02 批量单因素 Logistic 分析
根据上述求出每个单因素 Logistic 回归分析的各种指标,如 OR,95%自信区间,P 值等,整理成为一张表格,写一个简单的函数,获得各种指标,如下:
univ_formulas<-
function(x){
#拟合结局和变量
fml<-as.formula(paste0("status==0~",x))
#glm()逻辑回归
glm<-glm(fml,data=lung,family = binomial)
#提取所有回归结果放入sum中
sum<-summary(glm)
#1-计算OR值保留两位小数
OR<-signif(exp(coef(glm)),2)
#2-提取SE
SE<-sum$coefficients[,2]
#3-计算CI保留两位小数并合并
lower<-signif(exp(coef(glm)-1.96*SE),2)
upper<-signif(exp(coef(glm)+1.96*SE),2)
CI<-paste0(lower,'-',upper)
CI <- paste0(OR, " (",
lower, "-", upper, ")")
#4-提取P值
P<-signif(sum$coefficients[,4],2)
#5-将变量名、OR、CI、P合并为一个表,删去第一行
univ_formulas<- data.frame('Variants'=x,
'CI' = CI,
'P-value' = P,
'OR' = OR,
'lower' = lower,
'upper' = upper)[-1,]
#返回循环函数继续上述操作
return(univ_formulas)
}
这里我们选择除了 time, status 的8个协变量来做单因素 Logistic 回归分析,之后在对结果进行整理,达到一张表格,即为单因素 Logistic 回归分析的结果,也是文章经常出现的表格,整理数据,如下:
covariates <- c("inst","age", "sex", "ph.karno", "ph.ecog", "wt.loss","meal.cal","pat.karno")
univ_logistic_result <- lapply(covariates, univ_formulas)
univ_logistic_result
library(plyr)
univ_logistic_result <- ldply(univ_logistic_result,data.frame)
#最后,将P值=0的变为p<0.0001
univ_logistic_result$P.value[univ_logistic_result$P==0]<-"<0.001"
names(univ_logistic_result)=c("Variants","Hazard Ratio (95%CI)","P-value","","","")
univ_logistic_result #########最后三列的列名赋值为空
Variants Hazard Ratio (95%CI) P-value
1 inst 1 (0.99-1.1) 0.1 1.00 0.99 1.10
2 age 0.96 (0.93-1) 0.042 0.96 0.93 1.00
3 sex 2.7 (1.3-5.3) 0.0054 2.70 1.30 5.30
4 ph.karno 1 (1-1.1) 0.04 1.00 1.00 1.10
5 ph.ecog 0.46 (0.28-0.76) 0.0027 0.46 0.28 0.76
6 wt.loss 0.99 (0.97-1) 0.53 0.99 0.97 1.00
7 meal.cal 1 (1-1) 0.75 1.00 1.00 1.00
8 pat.karno 1 (1-1.1) 0.018 1.00 1.00 1.10
#保存为Excel
write.csv(univ_logistic_result ,"univ_logistic_result.csv",row.names = F)
03 单因素 Logistic 可视化
这里我们仍然利用 R 包 forestplot 来绘制可视化图,跟单因素 Cox 回归的一样,但是得到的结果却不相同,根据上述结果我们已经保存输出结果,下面我们在利用 read.csv() 读取结果文件作为输入文件,森林图的代码就跟 Cox 回归一样,如下:
#install.packages("forestplot")
library(forestplot)
rs_forest <- read.csv('univ_logistic_result.csv',header = FALSE)
rs_forest
# 读入数据的时候大家一定要把header设置成FALSE,保证第一行不被当作列名称〿
tiff('Figure 2.tiff',height = 1800,width = 3000,res= 600)
forestplot(labeltext = as.matrix(rs_forest[,c(1,2,3)]),
#设置用于文本展示的列,此处我们用数据的前四列作为文本,在图中展示
mean = rs_forest$V4, #设置均倿
lower = rs_forest$V5, #设置均值的lowlimits陿
upper = rs_forest$V6, #设置均值的uplimits陿
#is.summary = c(T,T,T,T,T,T,T,T,T),
#该参数接受一个逻辑向量,用于定义数据中的每一行是否是汇总值,若是,则在对应位置设置为TRUE,若否,则设置为FALSE;设置为TRUE的行则以粗体出现
zero = 1.5, #设置参照值,此处我们展示的是HR值,故参照值是1,而不昿0
boxsize = 0.3, #设置点估计的方形大小
lineheight = unit(8,'mm'),#设置图形中的行距
colgap = unit(2,'mm'),#设置图形中的列间跿
lwd.zero = 2,#设置参考线的粗绿
lwd.ci = 2,#设置区间估计线的粗细
col=fpColors(box='#458B00', summary= "#8B008B",lines = 'black',zero = '#7AC5CD'),
#使用fpColors()函数定义图形元素的颜色,从左至右分别对应点估计方形,汇总值,区间估计线,参考线
xlab="The estimates",#设置x轴标筿
lwd.xaxis=2,#设置X轴线的粗绿
lty.ci = "solid",
graph.pos = 3)#设置森林图的位置,此处设置为4,则出现在第四列
dev.off()
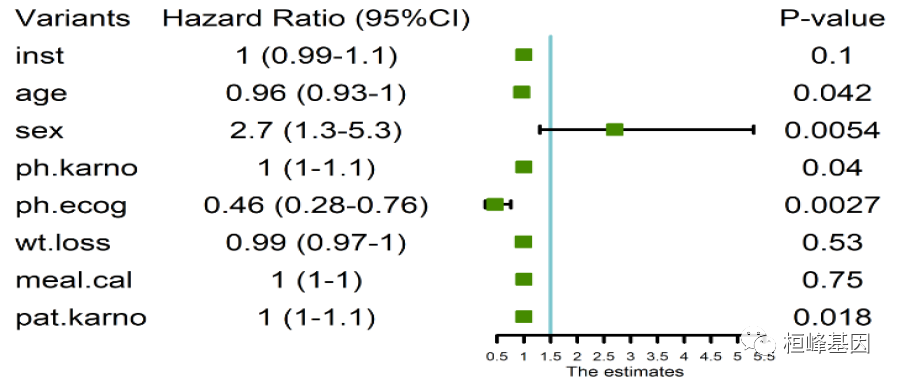
这样对比单因素 Cox 回归分析的结果,可以看出使用的模型不同,得到的结果大相径庭,我这里只是做个例子,所以说在模型选择上,一定需要我们清晰的知道自己的目的是什么,数据类型才能准确快速的选择模型。
单因素完成,下期需要将单因素与多因素整理到一张表格中,有时还需要加一列数据本身的分组信息,下期将进行讲解。
关注公众号,每天有更新,记得扫码进群,每天有讨论,免费交流哦!
Reference:
-
Liu Y, Zhao P, Cheng M, Yu L, Cheng Z, Fan L, Chen C. AST to ALT ratio and arterial stiffness in non-fatty liver Japanese population:a secondary analysis based on a cross-sectional study. Lipids Health Dis. 2018 Dec 3;17(1):275.
-
Hosmer, D. & Lemeshow, S. (2000). Applied Logistic Regression (Second Edition). New York: John Wiley & Sons, Inc.
-
Long, J. Scott (1997). Regression Models for Categorical and Limited Dependent Variables. Thousand Oaks, CA: Sage Publications.
桓峰基因
生物信息分析,SCI文章撰写及生物信息基础知识学习:R语言学习,perl基础编程,linux系统命令,Python遇见更好的你
31篇原创内容
公众号


















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









