







ResNets, Highway, Networks, Stochastic depth, DenseNet他们的共同的特点是:
They create short paths from early layers to later layers.
他们都在创造一些更短路径,使得前面的层的数据可以通过“捷径”传输到后面的层。
而论文作者也借鉴了这种思想,甚至把它发挥到极致:
在每一层都有连接其他不同层的前项传播路径。假设我们具有L层的传统卷积网络具有L个连接 - 每层与其后续层之间的连接 - 我们的网络具有
1
2
L
(
L
+
1
)
\frac{1}{2}L(L+1)
21L(L+1)个直接连接。
Dense Block具有如下图:
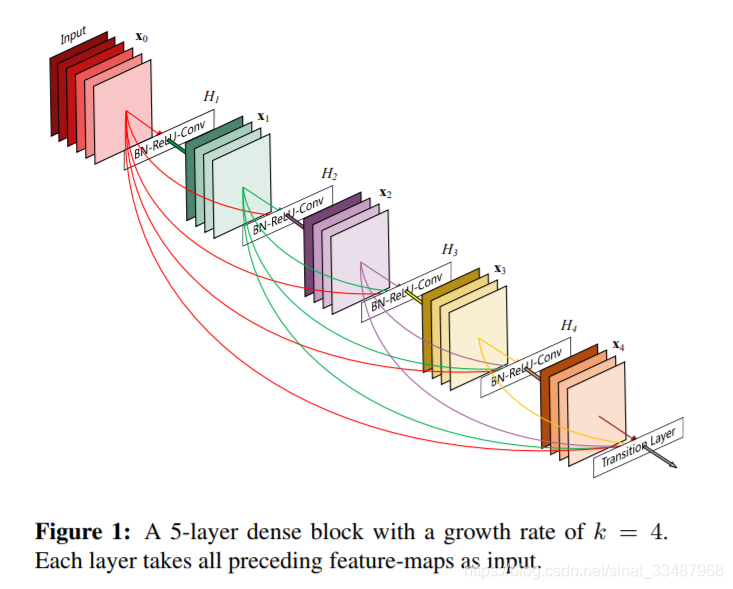
下面就是DenseNet的传播公式,可以看到,每一层的输入都包括之前所有层的输出。
x
l
=
H
l
(
[
x
0
,
x
1
,
.
.
.
,
x
l
−
1
]
)
x_{l} = H_{l}([x_{0}, x_{1}, ..., x_{l-1}])
xl=Hl([x0,x1,...,xl−1])
一个完整的DenseNet的网络结构如下:

DenseNet因此具有的优点是:
- 可以缓解梯度弥散问题
- 加强特征传播
- 加强特征重用
- 大幅减少参数数量
值得注意的是:与ResNet相比,DenseNet从未将features传递到图层之前通过求和来组合特征; 相反,是通过concatenating连接它们来组合features。简单点说,ResNet是直接相加,DenseNet是堆叠。
在这里解释一下,为什么这样能大量减少参数量,明明连接的路径多了?
这种密集连接模式需要比传统卷积网络更少的参数,是因为不需要重新学习冗余特征映射。传统的前馈结构可以被视为具有状态的算法,该状态在层与层之间传递。每个层从其前一层读取状态并写入后续层。在更改状态的同时,还传递需要保留的信息。ResNets通过加性身份转换使这些信息,使它们保持明确。最近的变化表明,许多层贡献很少,实际上在训练期间可以随机丢弃。这使得ResNets的状态类似于(展开的)递归神经网络。但ResNets的参数数量要大得多,因为每个层都有自己的权重。而DenseNet架构明确区分了添加到网络的信息和保留的信息。
DenseNet图层非常窄(例如,每层12个filter),只为网络的“集体信息”添加一小组特征图,并保持其余的特征图不变 - 最终分类器根据feature-maps所有特征做出决策。
论文也给出了多个不同版本的实现,具体结构如下图:
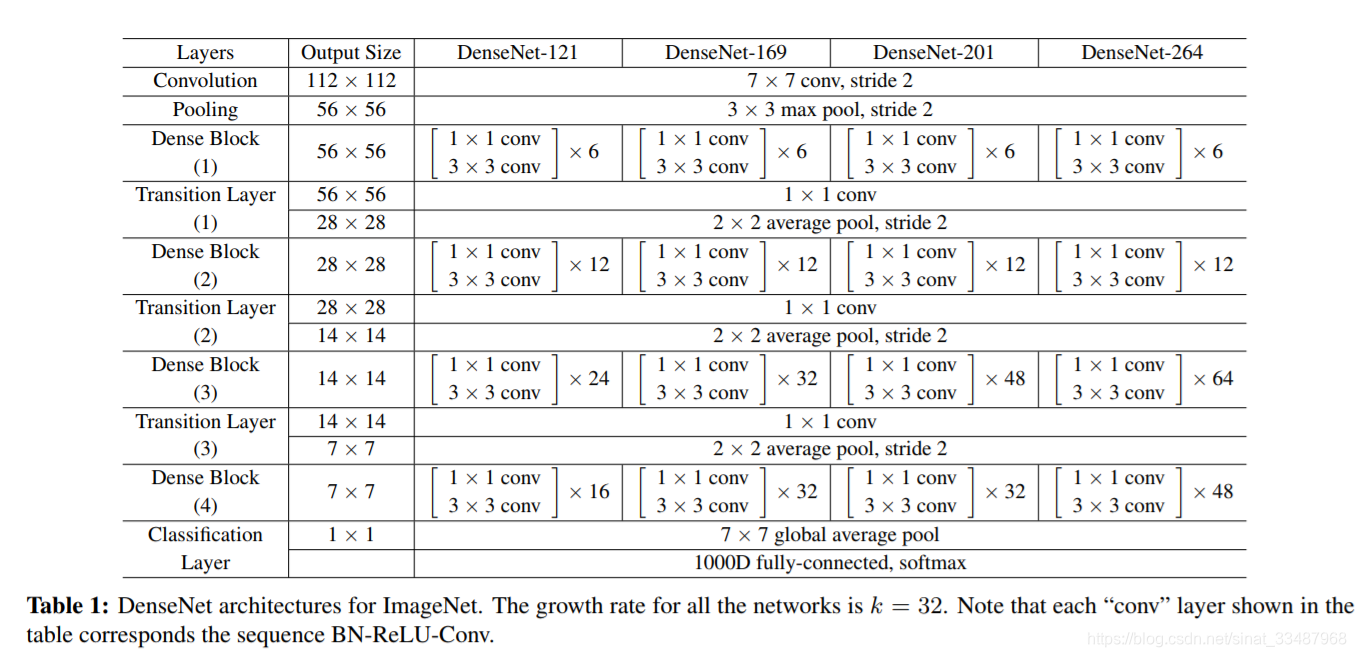
上图中的k就是growth rate,
k
0
k_{0}
k0就是一开始input channels,然后之后的第i层channels就会变成
k
(
i
−
1
)
+
k
0
k(i-1)+k_{0}
k(i−1)+k0
还有两个实现的要点:
- Bottleneck layers: 简单点说就是在3X3 conv 之前使用1X1 conv 来降低输入的feature map的数量。
- Compression:为了进一步提高模型的紧凑性,可以减少过渡层的特征图数量。利用压缩因子 θ ( 0 < θ < = 1 ) \theta (0<\theta<=1) θ(0<θ<=1)压缩feature map。当 θ = 1 \theta = 1 θ=1, 跨过层的特征映射的数量保持不变。
最后来看看结果:整体比ResNet强,参数更少,计算复杂度更小而且错误率降低了。

左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果。

总结一下,DenseNet于建立了不同层之间的连接关系,充分利用了feature,减轻了梯度消失问题。另外,利用bottleneck layer,Comparison以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。
Reference:
https://blog.csdn.net/sinat_33487968/article/details/83684453
torchvision中的实现
DenseNet由Dense Block组成,而Dense Block是由DenseLayer组成,下面就是DenseLayer类:
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__:
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_out > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
可以看到每一层卷积之前都是用了batchnorm和relu, 然后就是1x1的卷积和3x3的卷积。这个1x1的卷积就是bottleneck layer, 它能够降低输入的feature map的数量。bn_size参数是bottleneck_layer瓶颈层数的乘法因子。drop_rate是drop out的概率大小。注意最后的返回值,torch.cat([x, new_features], 1), 也就是包括自己本身和提取的feature层堆叠在一起。
有了DenseLayer之后就可以用它来构建DenseBlock:
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = __DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
解释一下一些参数的含义:growth_rate (int) - 代表每一层有多少个新的feature层添加进去 (paper里面是k),num_input features(int) - 输入的feature层数,num_layers(int)- 代表了Dense Block有多少层DenseLayers。
for循环就是根据num_layers逐层添加Dense Block注意每一层的输入num_input features不一样,是因为每一个DenseLayer之后feature的数目都会增加growth rate。直观一点理解,其实就是每一层的DenseLayer附带了自己学习到的feature还有自己本身一起传入下一个DenseLayer。所以后面的输出的结果会不断的增加,下图不能体现数据流动这一点,因为下图不是数据本身,而是代表卷积层
在DenseBlock之间,还添加了Transition层,这个层的作用是为了进一步提高模型的紧凑性,可以减少过渡层的特征图的数量。这里直接就把num_input_features压缩成num_output_features,使用一层卷积实现的。
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
接下来就可以组合成一个DenseNet:
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
#first convolution
self.features = nn.Sequential(OrderDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# each DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features, bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i+1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) -1 :
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i+1), trans)
num_features = num_features // 2
# final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# linear layer
self.classifier = nn.Linear(num_features, num_classes)
# official init from torch repo
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init..kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
Reference:
https://blog.csdn.net/sinat_33487968/article/details/83687851















 6789
6789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









