







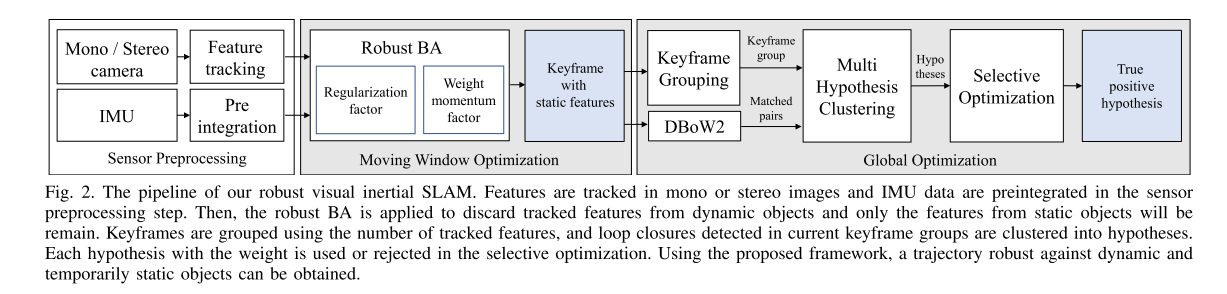
 DynaVINS论文介绍了在动态环境中,如何通过改进的BA方法(增强IMU预积分正则化和动量因子)和关键帧分组策略来解决位姿估计精度下降和假阳性回环检测问题。该方法针对动态物体和临时静态物体,提高了VI-SLAM的性能,但可能牺牲了部分速度。
DynaVINS论文介绍了在动态环境中,如何通过改进的BA方法(增强IMU预积分正则化和动量因子)和关键帧分组策略来解决位姿估计精度下降和假阳性回环检测问题。该方法针对动态物体和临时静态物体,提高了VI-SLAM的性能,但可能牺牲了部分速度。
DynaVINS: A Visual-Inertial SLAM for Dynamic Environments
论文来源:https://arxiv.org/abs/2208.11500
期刊: IEEE RA-L(2022 年 8 月 22 日)
作者:Seungwon Song, Hyungtae Lim, Alex Junho Lee, Hyun Myung
代码:https://github.com/url-kaist/dynavins
DynaVINS论文阅读笔记
快速导读
针对什么问题?
动态环境中的动态物体造成的位姿估计精度的下降和回环检测的假阳性问题。
采用什么方法?
(1)改进BA增加IMU预积分的正则化因子和每个权重的先前状态的动量因子来拒绝动态物体的特征点。
(2)通过关键帧分组和基于多假设的约束分组方法,以减少回环检测中的假阳性。
达到什么效果?
可以处理不能仅通过基于学习或仅视觉的方法来解决的动态对象,减少回环检测中的假阳性。
存在什么不足?
可能运行速度比较慢
摘要
讨论问题
(1)在存在动态物体的环境中,动态物体的移动造成位姿估计精度的降低。
(2)动态物体在视野可见范围内的暂时静止且在视野外的运动(临时静态物体)造成回环检测的假阳性。
提出方法
(1)提出了一种鲁棒的BA,通过利用IMU预积分估计的姿态先验来拒绝来自动态对象的特征点。
(2)提出了关键帧分组和基于多假设的约束分组方法,以减少回环检测中临时静态对象的影响。
Ⅰ、引言
SLAM算法已经广泛应用于各种机器人在 GPS 信号被阻挡的环境中进行精确定位或导航。
目前研究存在问题
(1)大多数研究人员将所有地标假设是静态的,但这样做是在真实的环境中是存在潜在的风险的。
(2)大多是的动态环境中的研究是通过深度聚类、特征重投影或深度学习检测动态对象的区域来解决这些问题。还有将动态对象的动力学纳入优化框架。
基于几何的方法需要准确的相机位姿,因此它们只能处理有限部分的动态对象。
深度学习辅助方法具有仅适用于预定义对象的局限性。
(3)视觉惯性 SLAM框架有来自 IMU 的运动先验有助于 VI-SLAM 算法在一定程度上容忍具有动态对象的场景。但是如果图像中动态对象占大多数,如图 1(b) 所示,则不能仅使用运动先验来解决问题。
(4)在现实世界的应用中,暂时静止的物体在被观察时是静止的,但在不被观察时是运动的。这些物体可能导致闭环过程中的严重失败,如图 1(c)所示。 为了处理临时静态对象,很多研究人员提出了强大的后端方法来减少优化中回环检测误报的影响。 然而,由于这些研究专注于瞬时回环检测误报,但他们无法处理由临时静态对象引起的持续回环检测误报。

贡献点
(1)提出了鲁棒的VI-SLAM方法来处理占主导地位,可以处理不能仅通过基于学习或仅视觉的方法来解决的动态对象
(2)提出了一种新的光束法平差(BA)方法,用于同时估计相机位姿和丢弃与运动先验显著偏离的动态对象的特征。
(3)提出了一种将约束分组为多个假设的鲁棒全局优化,以拒绝来自临时静态对象的回环检测。
Ⅱ、相关工作
A.视觉惯性SLAM
基于滤波的方法
MSCKF是一种基于扩展卡尔曼滤波器(EKF)的VI-SLAM算法。
ROVIO 也使用了 EKF,但提出了一个完全以机器人为中心且实时运行的直接 VI-SLAM 框架。
基于优化的方法
OKVIS 提出了一个基于关键帧的框架,并在优化中融合了 IMU 预积分残差和重投影残差。
ORB-SLAM3 使用 ORB 描述符进行特征匹配,并通过优化校正姿势和特征位置。
VINS-Fusion 是 VINS-Mono 的扩展版本,支持立体摄像头,采用特征跟踪,而不是描述符匹配,使算法更快速、更鲁棒。
这些VI-SLAM方法在处理占主导地位的动态对象和暂时静态对象方面仍然具有潜在的局限性。
B.动态物体剔除视觉和视觉惯性SLAM
基于几何的方法
Fan等人(Dynamic objects elim-
ination in SLAM based on image fusion)提出了一种使用 RGB-D 相机的基于多视图几何的方法。通过最小化重投影误差得到相机位姿后,通过相机运动与特征之间的几何关系确定每个特征点的类型是动态的还是静态的。
Canovas等人(Speed and memory efficient dense RGB-D SLAM in dynamic scenes) 提出了类似的方法,但采用了类似于多边形的surfel,通过减少要计算的项目数来实现实时性能。但是,基于多视图几何的算法假设相机姿势估计足够准确,从而导致由于主要的动态对象而导致相机姿势估计不准确时失败。
该问题的解决方案之一是采用轮式编码器。 G2P-SLAM 拒绝了与车轮里程计估计姿态误差马氏距离较高的闭环匹配结果,但受到动态和临时静态物体的影响是不变的。 虽然车轮编码器具有优势,但这些方法高度依赖于车轮编码器,限制了它们自身的适用性。
基于深度学习的方法
另一种可行的方法是采用深度学习网络来识别预定义的动态对象。
DynaSLAM中,使用深度学习网络消除了预定义动态对象的掩蔽区域,并通过多视图几何确定了其余区域。
在动态 SLAM 中,采用了一种补偿方法,使用序列数据来弥补少数关键帧中的漏检。尽管深度学习方法可以成功地丢弃动态对象,即使它们是暂时静态的,但由于以下两个原因,这些方法有些问题:
a) 必须预先定义动态对象的类型
b) 有时,如图1(b) 所示,只有一部分动态对象是可见的。由于这些原因,偶尔可能无法检测到物体。
另一方面,提出了用于跟踪动态对象的运动的方法。
RigidFusion假设环境中只有一个动态对象,并估计动态对象的运动。邱等人(Tracking 3-D motion of dynamic objects using monocular visual-inertial sensing)结合了深度学习方法和Vins-Mono[3]来同时跟踪相机和物体的姿态。DynaSLAM II 识别动态对象,类似于 DynaSLAM,然后在 BA 因子图中,估计静态特征和相机的位姿,同时估计动态对象的运动。
C.鲁棒的后端
在图 SLAM 领域,一些研究人员试图丢弃错误创建的约束。例如,max-mixture 采用单个集成贝叶斯框架来消除不正确的回环,而提出可切换约束来调整每个约束的权重以消除优化中的误报回环。
但是,可以预测假阳性回环检测是一致的,并且由于临时静态对象的存在持续发生。这些鲁棒的内核不适合处理这种持续的回环检测错误。
另一方面,提出了 Black-Rangarajan (B-R) 对偶性来统一鲁棒估计和异常值拒绝过程。一些方法在点云配准和位姿图优化 (PGO) 中利用 B-R 对偶性来减少假阳性匹配的影响,即使假阳性匹配占主导地位。这些方法对于拒绝 PGO 中的异常值很有用。但是,没有考虑来自类似对象的重复检测到的误报闭环。此外,B-R 对偶性尚未在 VI-SLAM 的 BA 中使用。
为了解决上述局限性,我们通过不仅在图结构中而且在BA框架中通过反映IMU先验和特征跟踪信息,改进了VI-SLAM,以最小化动态对象和临时静态对象的影响。
Ⅲ、鲁棒的BA
A.符号
在这篇文章当中,定义了以下符号。
C
i
:
第
i
个相机帧
\ C_i :第i个相机帧
Ci:第i个相机帧
f
j
:
第
j
个跟踪特征点
\ f_j :第j个跟踪特征点
fj:第j个跟踪特征点
T
B
A
∈
S
E
(
3
)
表示
C
A
相对
C
B
的位姿
\ T^A_B\in SE(3)表示C_A相对C_B的位姿
TBA∈SE(3)表示CA相对CB的位姿
T
W
A
表示
C
A
在世界坐标系的位姿
\ T^A_W表示C_A在世界坐标系的位姿
TWA表示CA在世界坐标系的位姿
B
是
\ \Beta 是
B是IMU 预积分的一组指标
P
是是一组视觉对
(
i
,
j
)
\ \Rho是是一组视觉对 (i, j)
P是是一组视觉对(i,j)
其中
i
对应于帧
C
i
,
j
对应于特征
f
j
其中 i 对应于帧 Ci,j 对应于特征 f_j
其中i对应于帧Ci,j对应于特征fj
因为跟踪特征
f
j
\ f_j
fj跨多个相机帧,所以不同的相机帧可以包含相同的特征
f
j
\ f_j
fj。因此,将当前移动窗口中所有跟踪的特征的一组索引表示为
F
P
\ F_\Rho
FP,并且将包含特征
f
j
\ f_j
fj的相机帧的一组索引表示为
P
(
f
j
)
\ \Rho(f_j)
P(fj)。
在当前滑动窗口的视觉惯性优化框架中,
χ
\chi
χ表示包含关键帧的姿态和速度集、IMU 的偏差(即加速度和陀螺仪偏差)以及估计的特征深度的完整状态向量。
B.常用的BA
在传统的视觉惯性状态估计器中,视觉惯性BA公式定义如下:
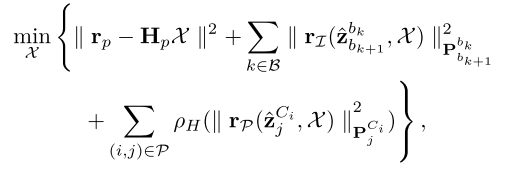
其中
ρ
H
(
⋅
)
\rho_H( · )
ρH(⋅) 表示 Huber 损失;
r
p
,
r
L
\ r_p,r_L
rp,rL 和
r
P
\ r_\Rho
rP 分别代表边缘化、IMU 和视觉重投影测量的残差;
z
^
b
k
+
1
b
k
\ \hat {z}_ {b_{k+1}}^ {b_k}
z^bk+1bk和
z
^
j
C
i
\ \hat {z}_ {j}^ {C_i}
z^jCi 代表对 IMU 和特征点的观察;
H
p
\mathbf{H}_p
Hp表示边缘化的测量估计矩阵,P表示每一项的协方差。为方便起见,
r
L
(
z
^
b
k
+
1
b
k
,
χ
)
\ r_ {L} ({\hat {z}_ {b_{k+1}}^ {b_k} }, \chi)
rL(z^bk+1bk,χ)和
r
P
(
z
^
j
C
i
,
χ
)
\ r_ {\Rho} ({\hat {z}_ {j}^ {C_i}}, \chi)
rP(z^jCi,χ)分别简化为
r
L
k
\ r_L^{k}
rLk和
r
P
j
,
i
\ r_{\Rho}^{j,i}
rPj,i。
一旦异常值的比率增加,Huber损失就不能成功地工作。这是因为Huber损失并不完全排除异常值的残差。另一方面,重降M估计量,如GemanMcClure(GMC),由于其零梯度,一旦残差超过特定范围,就会完全忽略异常值。不幸的是,这种截断引发了一个问题,即被认为是离群点的特征永远不会成为内点,即使这些特征源自静态对象。
为了解决这些问题,我们的BA方法由两部分组成:
a) 利用IMU预积分的正则化因子
b) 用于考虑每个权重的先前状态的动量因子,以包括预积分暂时变得不准确的情况。
C.正则化因子
首先,为了在稳健估计姿态的同时剔除异常特征,我们受B-R对偶的启发,提出了一个新的损失项:
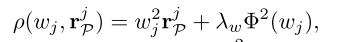
r
P
j
\ r_{\Rho}^j
rPj为
∑
i
∈
P
(
f
j
)
∥
r
P
j
,
i
∥
2
\sum_{i\in \Rho(f_j)}\| r_{\Rho}^{j,i}\|^2
∑i∈P(fj)∥rPj,i∥2,简单起见
w
j
∈
[
0
,
1
]
w_j \in [0,1]
wj∈[0,1]表示每个特征
f
j
\ f_j
fj对应的权重,将
w
j
\ w_j
wj接近 1 的
f
j
\ f_j
fj确定为静态特征; λw ∈ R+ 是一个常数参数; Φ(wj) 表示权重
w
j
\ w_j
wj 的正则化因子,定义如下:
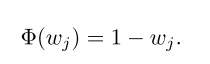
然后,采用公式(2)中的
ρ
(
w
j
,
r
P
j
)
\rho(w_j,r_\Rho^j)
ρ(wj,rPj)代替公式(1)中的视觉重投影项中的Huber范数。因此,BA公式可以表示为:
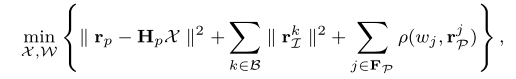
其中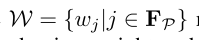
表示所有权重的集合。
通过采用由b-r对偶启发的权重和正则化因子,可以在保持状态估计性能的同时减少与估计状态相比具有高重投影误差的特征的影响。
公式(4) 使用交替优化来解决。 因为当前状态
χ
\chi
χ可以从 IMU 预积分和先前优化的状态中估计出来,与其他方法 [17, 18] 不同,W 首先用固定的
χ
\chi
χ更新。然后,用固定的 W 优化
χ
\chi
χ。
在优化W时,除权重外的所有项都是常数。因此,用于优化权重的公式可以表示如下:
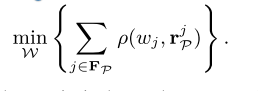
因为权重
w
j
\ w_j
wj是相互独立的,所以 (5) 可以针对每个
w
j
\ w_j
wj独立优化如下:
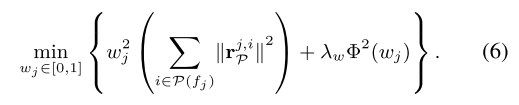
因为 (6) 中的项是二次形式 w.r.t.
w
j
\ w_j
wj,所以最优
w
j
\ w_j
wj可以推导出如下:
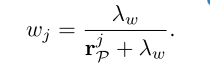
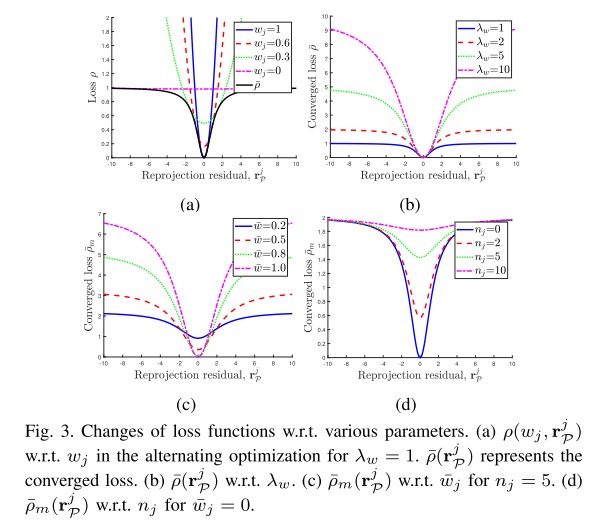
如前所述,权重首先根据估计的状态进行优化。 因此,具有高重投影误差的特征的权重从较小的值开始。 然而,如图 3(a) 所示,特征
ρ
(
w
j
,
r
P
j
)
\rho(w_j,r_\Rho^j)
ρ(wj,rPj)的损失是一个凸函数,除非权重为零,不仅在离群特征的损失中存在非零梯度,而且在离群特征的损失中也存在非零梯度,这意味着新特征对BA的影响与最初的类型无关。
在重复优化步骤直到状态和权重收敛的同时,离群特征的权重被降低,其损失也更加扁平化。因此,离群特征的损失接近零梯度,不会影响BA的结果。
收敛后,可以用(7)中的重投影误差来表示权重。因此,收敛后的损失
ρ
‾
(
r
P
j
)
\ \overline{\rho}(r_\Rho^j)
ρ(rPj)可以通过将(7)应用于(2)得出,如下:
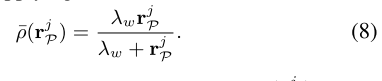
如图3(b)所示,增加λw会在两个方向上影响
ρ
‾
(
r
P
j
)
\ \overline{\rho}(r_\Rho^j)
ρ(rPj):增加梯度值和凸性。通过增加梯度值,视觉重投影残差对BA的影响要大于边缘化和IMU预积分残差。而通过增加凸度,一些离群的特征会影响BA。
综上所述,通过自适应调整权重,提出的因子受益于 Huber loss 和 GMC;我们的方法有效地过滤了异常值,但在优化过程中并没有完全忽略异常值。
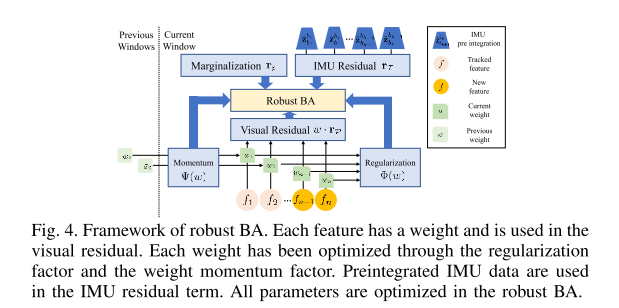
D.权重动量因子
当运动变得激进时,IMU 预积分变得不精确,因此估计的状态变得不准确。在这种情况下,来自静态对象的特征的重投影残差变得更大;因此,通过正则化因子,即使之前的权重接近 1,这些特征也会在 BA 过程中被忽略。
如果增加λw来解决这个问题,即使是动态对象的高重射残差的特征也会被使用。因此,BA的结果将是不准确的。因此,增加λw并不足以解决这个问题。
为了解决这个问题,我们提出了一个附加因子,即权重动量因素,以使先前估计的特征权重不受激进运动的影响。
由于特征是连续跟踪的,每个特征
f
j
\ f_j
fj都要用它以前的权重
w
‾
j
\overline{w}_j
wj优化
n
j
\ n_j
nj次。为了使当前权重趋于保持在
w
‾
j
\overline{w}_j
wj,并随着nj的增加而增加趋向程度,权重动量因子Ψ(wj)设计如下:
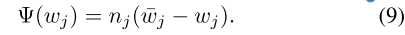
然后,将(9)添加到(2),修改后的损失项可以得到如下:
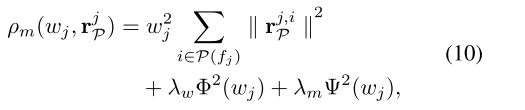
其中 λm ∈ R+ 表示一个常数参数,用于调整动量因子对 BA 的影响。
综上所述,提出的鲁棒BA可以如图4所示。权重动量因子使用之前跟踪特征的权重,正则化因子使用当前窗口中所有特征的权重。因此,稳健的 BA 表示如下:
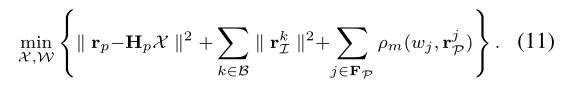
(11) 可以通过与 (4) 相同的方式使用交替优化来解决。迭代交替优化,直到
χ
\chi
χ和
W
\ W
W收敛。然后,可以推导出收敛损失
ρ
‾
(
r
P
j
)
\ \overline{\rho}(r_\Rho^j)
ρ(rPj)。
ρ
‾
(
r
P
j
)
\ \overline{\rho}(r_\Rho^j)
ρ(rPj)w.r.t.
w
‾
j
\overline{w}_j
wj 和
n
j
\ n_j
nj分别如图 3© 和 (d) 所示。
如图 3© 所示,如果
w
‾
\overline{w}
w较低,即使
r
P
j
\ r_\Rho^j
rPj接近 0,损失的梯度也很小。因此,可能来自动态对象的特征对 BA 没有太大影响即使当前步骤中的重投影误差在很低。
此外,如图3(d)所示,如果
w
‾
j
\overline{w}_j
wj 为零,随着
n
j
\ n_j
nj的增加,梯度会变小;因此,跟踪的离群特征对BA的影响较小,而且跟踪的时间越长,对BA的影响越小。
对于立体相机的配置,除了在一台相机上的重投影外,在同一关键帧的另一台相机上的重投影,
r
P
s
t
e
r
e
o
\ r_\Rho^{stereo}
rPstereo ,或另一关键帧,
r
P
a
n
o
t
h
e
r
\ r_\Rho^{another}
rPanother 都存在。在这种情况下,权重也适用于重投影
r
P
a
n
o
t
h
e
r
\ r_\Rho^{another}
rPanother ,因为它也受到特征移动的影响,而
r
P
s
t
e
r
e
o
\ r_\Rho^{stereo}
rPstereo 对特征的移动是不变的,只被作为深度估计的标准。
Ⅳ 选择性全局优化
在 VIO 框架中,漂移不可避免地沿着轨迹累积,因为优化只在移动窗口内执行。因此,为了优化所有的轨迹,有必要进行回环检测,例如使用DBoW2。
在一个典型的视觉SLAM中,所有的回环检测都被利用,即使其中一些是来自暂时静止的物体。这些假阳性的回环检测导致SLAM框架的失败。此外,来自临时静态物体和静态物体的特征可能存在于同一个关键帧中。因此,在本节中,我们提出了一种方法来消除假阳性回环检测,同时保持真阳性回环检测。
A.关键帧分组
与传统的单独处理回环的方法不同,在本研究中,来自相同特征的回环被分组,即使它们来自不同的关键帧。因此,每组只使用一个权重,允许更快的优化。
如图5(a)所示,在对回环进行分组之前,必须对至少共享最低数量跟踪特征的相邻关键帧进行分组。从第i个摄像机帧
C
i
\ C_i
Ci开始的分组定义如下。
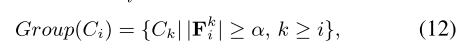
其中,α代表被追踪特征的最小数量,
F
i
k
\ F_i^k
Fik代表从
C
i
\ C_i
Ci到
C
k
\ C_k
Ck的被追踪特征集合。为简单起见,下文中Group(
C
i
\ C_i
Ci)将被表示为
C
i
\ C_i
Ci。
B.多重假设聚类
在上一小节中对关键帧进行分组后,DBoW2被用来识别与当前组
G
i
\ G_i
Gi中每个关键帧Ck相似的关键帧
C
m
\ C_m
Cm,从
C
i
\ C_i
Ci开始(
C
k
∈
G
i
\ C_k\in{G_i}
Ck∈Gi且m<i)。注意,如果没有相似的关键帧,则跳过
C
k
\ C_k
Ck。在确定了最多三个不同的k的m后,在Ck和这些关键帧之间进行特征匹配,可以得到相对姿势
T
m
k
\ T_m^k
Tmk。利用
T
m
k
\ T_m^k
Tmk,可以得到
C
k
\ C_k
Ck在世界帧中的估计姿势,
m
T
W
k
\ _ {m}T_W^k
mTWk,如下所示。

其中
m
T
W
k
\ _ {m}T_W^k
mTWk表示
C
m
\ C_m
Cm在世界坐标系中的位姿。
然而,很难直接计算当前组中不同关键帧的闭环之间的相似度。假设
C
k
\ C_k
Ck和
C
i
\ C_i
Ci之间的相对位姿
T
k
i
\ T_k^i
Tki 足够准确,则
C
i
\ C_i
Ci在世界坐标系中的估计位姿可以表示为:
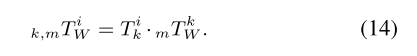
如果用于匹配的特征来自同一个对象,即使匹配的
C
k
\ C_k
Ck和
C
m
\ C_m
Cm不同,估计的匹配
T
W
i
T_W^i
TWi 也会彼此靠近。因此,在计算回环估计的
T
W
i
T_W^i
TWi 之间的欧几里得距离之后,具有小欧几里得距离的类似回环可以被聚类,如图 5(c)所示。
根据选择的闭环簇,图优化的轨迹结果会有所不同。因此,每个簇都可以称为一个假设。为了降低计算成本,通过比较假设中闭环的基数,采用了前两个假设。当前组
G
i
\ G_i
Gi的这两个假设表示为
H
i
0
\ H_i^0
Hi0和
H
i
1
\ H_i^1
Hi1。
然而,目前还无法区分真假阳性假设。因此,下一节将描述在候选假设中确定真阳性假设的方法。
C. 约束组的选择性优化
大多数最近的视觉 SLAM 算法都使用图优化。让 C、T、L 和 W 分别表示关键帧、姿势、闭环和所有权重的集合。那么图优化可以表示为:
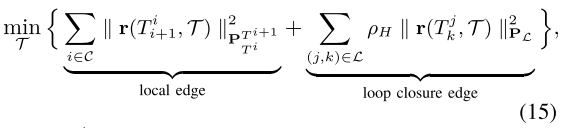
T
i
+
1
i
\ T_{i+1}^i
Ti+1i是
C
i
\ C_i
Ci 和
C
i
+
1
\ C_{i+1}
Ci+1 之间的局部位姿;
T
k
j
\ T_{k}^j
Tkj是回环
C
i
\ C_i
Ci和
C
k
\ C_k
Ck之间的相对位姿;
P
T
i
T
i
+
1
\ P_{T^i}^{T^{i+1}}
PTiTi+1和
P
L
\ P_L
PL 分别表示局部位姿和闭环的协方差。对于组 的两个假设,权重表示为
w
i
0
\ w_i^0
wi0和
w
i
1
\ w_i^1
wi1权重之和表示为
w
i
\ w_i
wi,假设集表示为
H
\ H
H。使用与第 III.C 节中类似的过程,Black-Rangarajan 对偶是应用于 (15) 如下:

其中
λ
l
∈
R
+
\ λ_l ∈ R_+
λl∈R+是一个常数参数。闭环的正则化因子
Φ
l
\ Φ_l
Φl 定义如下:
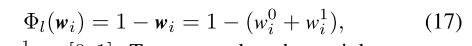
其中
w
i
0
\ w_i^0
wi0,
w
i
1
\ w_i^1
wi1,
w
∈
[
0
,
1
]
\ w ∈ [0, 1]
w∈[0,1]。为了确保权重不受假设中回环数量的影响,权重除以每个假设的基数。
然后,以与(11)相同的方式优化(16)。因此,在优化中只采用具有高权重的假设。此外,由于多个临时静态对象,当所有假设都是误报时,所有权重都可以接近 0。因此,可以防止由假阳性假设引起的失败。
由于优化后关键帧姿势发生了变化,因此对所有组再次进行第 IV.B 节中的假设聚类以进行下一次优化。
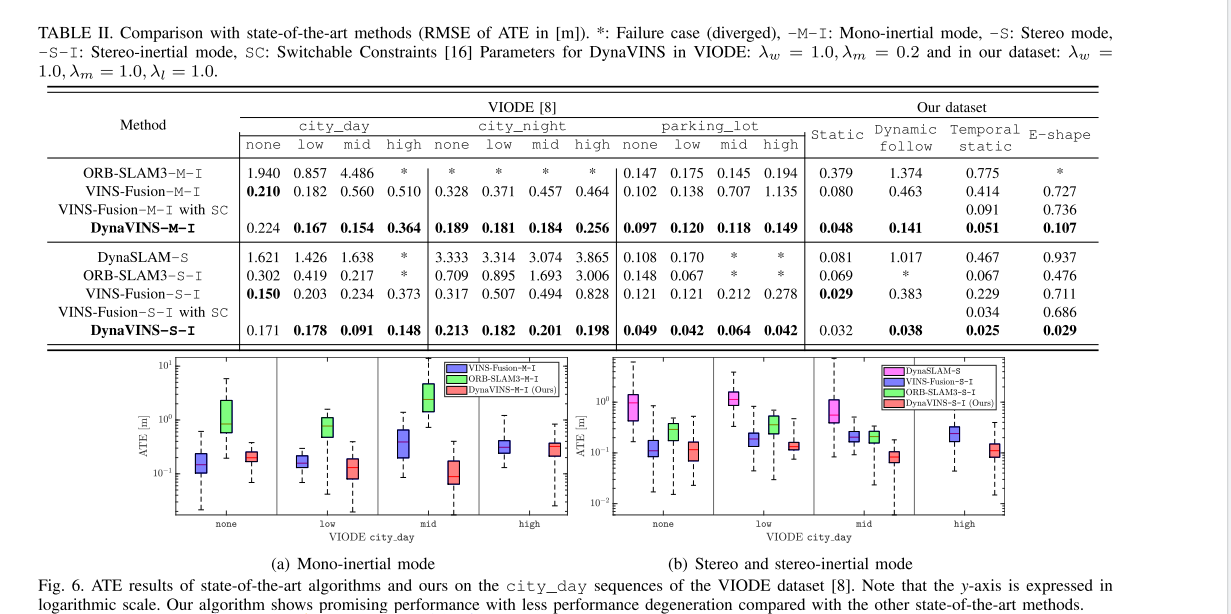
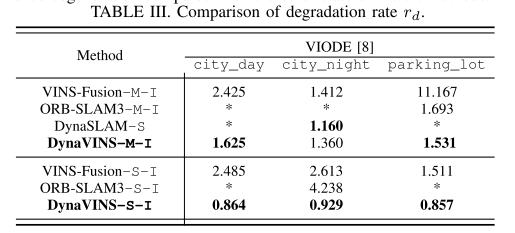
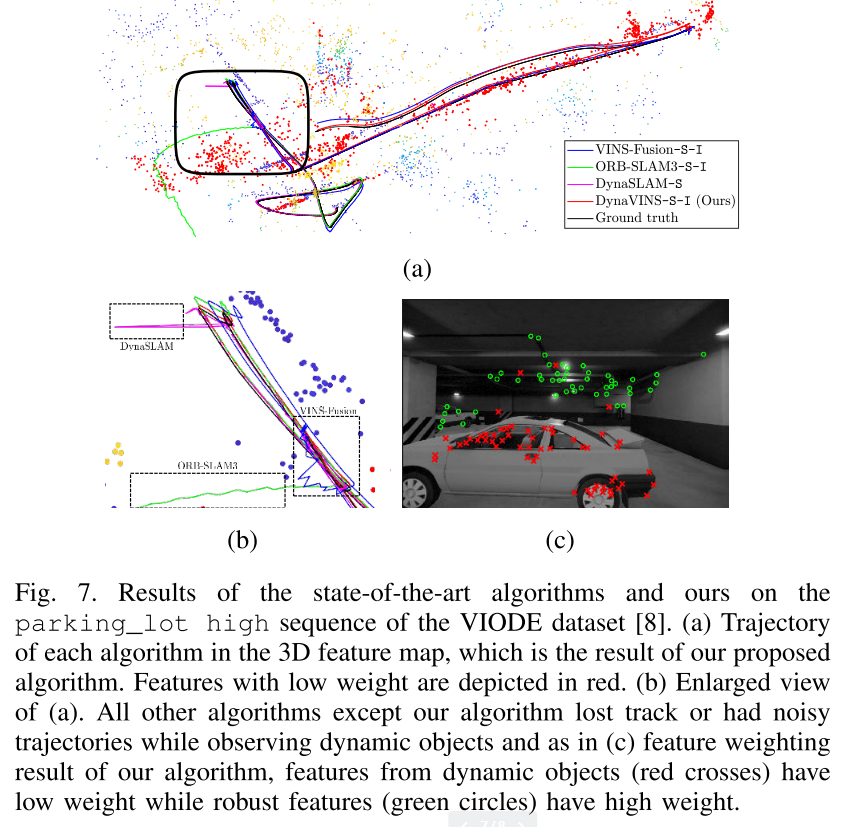
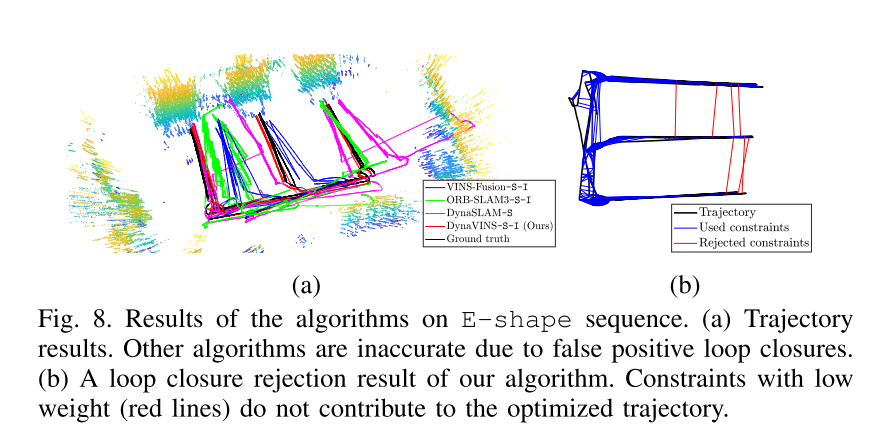
Ⅴ、实验结果
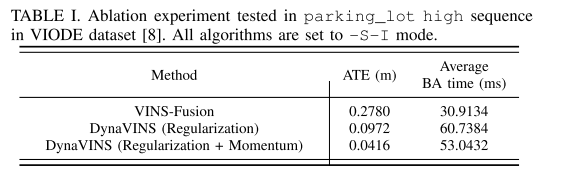
对比算法:VINS-Fusion、ORBSLAM3 和 DynaSLAM
均在单目惯性和双目惯性下了测试(DynaSLAM无IMU为了强调在处理动态环境时 IMU 的必要性。)
数据集:
VIODE:是一个模拟数据集,与传统数据集相比,它包含许多移动物体,例如汽车或卡车。此外,数据集包括整体遮挡情况,其中图像的大部分部分被主要动态对象遮挡,如图 1 所示。
自己的数据集:不幸的是,VIODE 数据集不包含由临时静态对象引起的严酷的闭环情况。因此,我们获得了具有四个序列的数据集来评估我们的全局优化。首先,静态序列验证数据集。在动态跟随序列中,一个主要的动态对象在相机前面移动。接下来,在时间静态序列中,从多个位置观察同一对象。换句话说,物体在被观察时是静止的,然后它会移动到不同的位置。最后,在E形序列中,相机沿字母E的形状移动。棋盘在不被观察的情况下移动,因此将在相机视角的E形轨迹的三个末端顶点处观察到,这会触发误报闭环。请注意,实验中使用了功能丰富的棋盘格来解决错误闭环的影响。
Ⅵ 结论
在本研究中,提出了 DynaVINS,它是一种基于鲁棒 BA 和动态环境中的选择性全局优化的鲁棒视觉惯性 SLAM 框架。实验证据证实,DynaVINS算法在模拟和具有各种动态对象的实际环境中比其他算法效果更好。在未来的工作中,我们计划提高速度和性能。此外,将在 LiDAR-Visual-Inertial (LVI) SLAM 框架中采用 DynaVINS 的概念。
如有错误欢迎指正!



















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











