







 PolarDETR是一种新的环视图3D物体检测方法,采用极坐标参数化物体位置,解决了基于图像和笛卡尔参数化的缺点。通过中心-上下文特征聚合和像素射线位置编码,提高了检测性能和收敛性。PolarDETR-T在处理时序图像时进一步增强了速度估计的准确性。
PolarDETR是一种新的环视图3D物体检测方法,采用极坐标参数化物体位置,解决了基于图像和笛卡尔参数化的缺点。通过中心-上下文特征聚合和像素射线位置编码,提高了检测性能和收敛性。PolarDETR-T在处理时序图像时进一步增强了速度估计的准确性。
原文链接:https://arxiv.org/abs/2206.10965
1 引言
目前的物体位置参数化方法主要有两种,即基于图像的参数化和笛卡尔参数化。
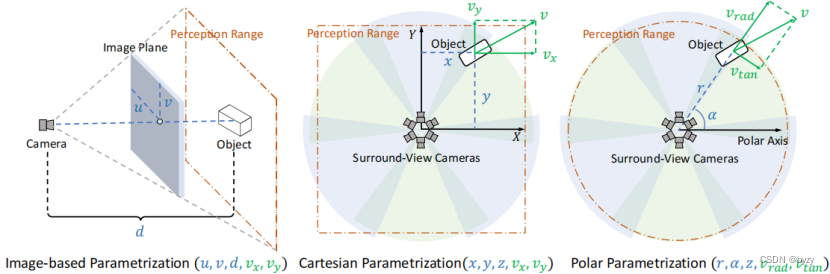
基于图像的参数化(左图):估计物体在图像中的像素索引和深度,再使用相机的内外参将该坐标转移到3D空间。通常用于单目图像。对于环视图像,该方法独立地在每个视角图像中回归边界框位置,然后投影到公共的3D空间。最后使用跨视图后处理如NMS滤除重复检测。
缺点是深度估计误差较大,且多视图方法中相邻视图重叠区域提供的额外信息未被利用;跨视图后处理方法困难而不稳定。
笛卡尔参数化(中图):通常检测范围为矩形。结合多视图的相关性,联合预测物体的3D坐标。
但该方法也存在问题,如下图所示:设物体和
位于不同图像中的相同位置,且有相同图像模式。
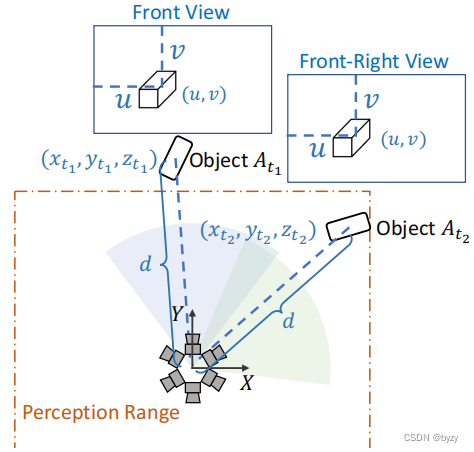
(1)由于检测范围为矩形(即只有检测范围内的物体会被标注),训练时仅考虑,而
被丢弃(即两个视图没有被同等对待),这对网络的收敛性有不利影响。
(2)该方法忽视了视图对称性。上图产生的两张图像,若用基于图像的参数化,学到的模型仅需要预测相同的位置;而使用笛卡尔参数化学到的模型需要预测不同的3D坐标,无疑会增加模型的复杂度,且优化模型更加困难。
本文提出环视图3D检测transformer(PolarDETR),即使用柱坐标(即径向距离、水平角和高度)参数化(称为极参数化;右图)物体位置,并将物体速度参数化为径向速度和切向速度。此外,检测范围、损失函数都是在极坐标下定义的。
PolarDETR能够实现中心-上下文特征聚合,增强目标查询与图像之间的信息交互,并采用像素射线作为位置编码,提供三维空间先验,帮助预测方位角。本文的PolarDETR实现了很好的性能-速度平衡。
3 PolarDETR
3.1 概述
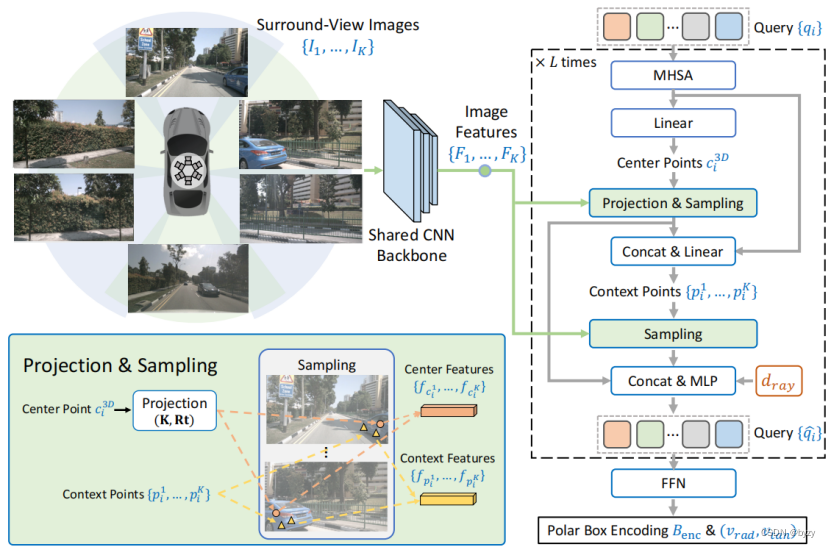
如下图所示。个不同视图的图像首先输入到共享的CNN提取特征,然后使用目标查询来检测物体。每个目标查询编码了相应物体的语义特征和位置信息,然后一系列解码层从环视特征图中聚合特征,迭代地更新目标查询。前馈网络(FFN)基于这些查询,预测类别,以及边界框和速度的极坐标编码。
3.2 极参数化
每个边界框参数被极坐标编码为9元组,可根据其估计边界框极坐标参数
。其中
和
为高度检测范围,
为检测距离最大值;
是sigmoid函数。水平角和朝向角的回归使用正余弦对
,以保证回归空间的连续性。
位置估计的极分解:极参数化将物体位置解耦为径向距离和水平角。距离与物体大小关联,可从图像模式中学习;水平角
与像素索引相关联,可从位置编码中学习。
速度估计的极分解:径向速度与物体大小变化率关联,切向速度与物体在图像平面的运动关联。
极参数化显式地建立了图像模式和预测目标的关联,这些显式关联使得检测器能有更好的收敛性和性能。
3.3 解码层
解码层迭代地聚合特征并更新查询。首先使用一个多头自注意力模块(MHSA)来进行查询间的信息交互,然后使用线性层从查询提取物体位置:
转换为3D坐标即可。
中心-上下文特征聚合:聚合环视图特征图的特征。先将3D中心点投影到各图像平面,得到2D中心点:
其中和
分别是由第
个相机内参和外参推导的投影矩阵。使用双线性插值从图像特征图中获得这些中心点的特征(如果2D中心位置超出图像范围,则特征设置为0)。
引入上下文特征增强查询和环视图特征的交互来促进定位。基于中心点特征和查询嵌入
预测与中心点的偏移量,生成上下文点的集合
:
最后使用双线性插值得到上下文点特征。
像素射线:如下图所示,像素射线从光学中心出发经过像素到达3D点,直接建立了像素与点之间的关系,包含了水平角的显式信息。
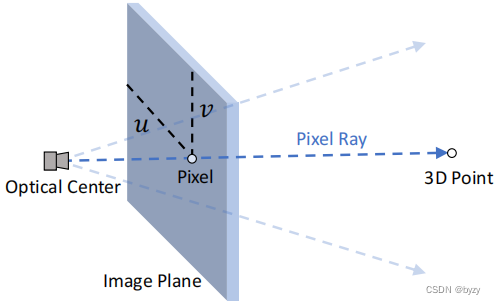
本文使用像素射线作为额外的位置编码,即对于每个中心点或上下文点,像素射线单位方向向量作为额外的特征维度与原特征拼接。
查询更新:
更新后的查询嵌入编码了更精确的位置信息,从而使得下一解码层能更好地进行特征聚合。
3.4 感知范围、标签分配和损失函数
感知范围:以自车为中心的圆形区域。
标签分配:先将标注标签转换为极坐标:,然后使用双向匹配方法为真实边界框匹配唯一的预测值。逐对匹配代价如下:
其中是DETR中定义的类别项。
计算每一对预测和真实边界框的匹配代价后得到代价矩阵,然后使用匈牙利算法寻找最优分配。
损失函数:双向匹配损失由分类损失(focal损失)以及极坐标边界框/速度损失(L1损失)组成。
3.5 时序信息
将PolarDETR扩展为PolarDETR-T以接受时序图像的输入。当前帧的物体中心被投影到之前帧的图像以获得特征,以第
帧为例:
其中为姿态变换矩阵,反应自车从第
到
帧的姿态变化。类似前述方法,从以前帧采样中心和上下文特征。最后所有采样特征被聚合,用于更新查询嵌入。
为进行高效推断,可以缓存过去的图像特征图,这样仅需要处理当前帧的图像,从而PolarDETR-T的推断速度接近PolarDETR。
4 实验
4.2 实验设置
使用检测跟踪算法将PolarDETR扩展为3D目标跟踪,即根据当前帧速度,将物体投影回上一帧,然后使用最近距离匹配方法匹配目标。
4.4 主要结果
PolarDETR-T的性能比PolarDETR要高,特别是对于速度的估计上。
4.5 消融研究
关键组件:极参数化、上下文点和像素射线均对性能有提升,且计算代价可忽略。
速度的极分解:与笛卡尔分解比较,极分解可以提高速度的估计精度。
上下文点:性能随上下文点的数量增加而变强,但一定范围后再增加则有负面效果。用于生成上下文点的查询嵌入和中心特征对性能提升均有帮助。
解码层:解码层数越多性能越好,但会趋于饱和。


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











