







原文链接:https://arxiv.org/abs/2211.14710
1. 引言
早期的多视图图像3D目标检测方法对每个视图分别检测,然后组合各视图的检测结果。但这样不能利用相邻相机的重叠区域,且分别检测会引入较大计算负担。后来的方法使用类似LSS的方法将多视图图像转化为BEV表达,但这一不适定的视图变换会导致误差积累,影响检测精度。
同时,基于Transformer的方法(如DETR)使用一组可学习的3D物体查询进行目标检测,而不需要显式的视图变换。3D查询与2D图像特征的交互方法有两种:基于投影的方法和基于位置编码的方法。前者将3D查询投影到图像平面上采样特征,需要额外部署工作;且仅提取局部特征,不能利用全局相干性提高性能。后者首先在PETR中提出,通过位置编码(PE)将3D查询整合到2D图像特征中。
3D PE的增强有望提高检测精度,但其设计还未被充分探索。典型的3D PE是3D相机射线PE(如下图(a)所示),编码从相机光学中心到图像像素的射线方向,但射线方向仅提供粗糙的定位信息,因为没有深度先验。此外,物体查询是从随机生成的3D参考点转变为嵌入向量的,参考点和相机射线PE的嵌入空间不一致性会阻碍Transformer解码器中注意力机制的有效性。因此,需要重新设计带深度先验的3D PE来定位2D特征和统一表达。

本文引入3D点位置编码(3DPPE)来提升基于Transformer的多相机3D目标检测性能。通过引入位置先验,3DPPE对3D相机射线PE进行了改进。此外,3DPPE还能提供更好的表达相似性。首先,设计了一个混合深度模块,将直接深度和分类深度组合细化每个像素的深度。然后,使用相机参数和预测深度将像素转换为3D点,并送入位置编码器得到3DPPE。上述3D点和参考点的位置编码器共享权重,以建立统一的嵌入空间。
3. 位置编码的准备知识
3.1. 基于射线的位置编码
PETR系列引入了将3D坐标信息编码到多相机图像特征中的方法,产生3D位置感知的特征。3D坐标信息来自沿相机射线的一组点,该方法称为相机射线PE。给定深度范围 R D = [ D min , D max ] R_D=[D_{\min},D_{\max}] RD=[Dmin,Dmax],首先使用线性增长离散化(LID)将深度离散化为 N D N_D ND个区间,然后沿相机射线在每个区间的中心取点,得到 N D N_D ND个点。各视图图像产生的点经过坐标变换后,位于同一坐标系下。将各像素对应的点拼接后输入嵌入层得到PE。
3.2. 3D点位置编码
最优的位置编码需要获得平面点真正的3D位置,而基于射线的位置编码仅编码了射线方向,而缺乏深度信息。
为确认上述观点的正确性,使用图像的真实深度将像素投影到3D空间。真实深度是将点云投影到图像平面获取稀疏深度图后进行深度补全的结果。结果表明,该方法的性能比起像素射线PE有了大幅提升,证明了精确的3D位置是提高性能的关键。
但正常情况下,基于相机的方法无法获取真实深度,因此使用轻型的深度估计模块来代替产生深度值。
4. 方法
本文使用统一深度指导的3DPPE将多视图图像的2D特征转换到3D空间。
4.1. 框架概述
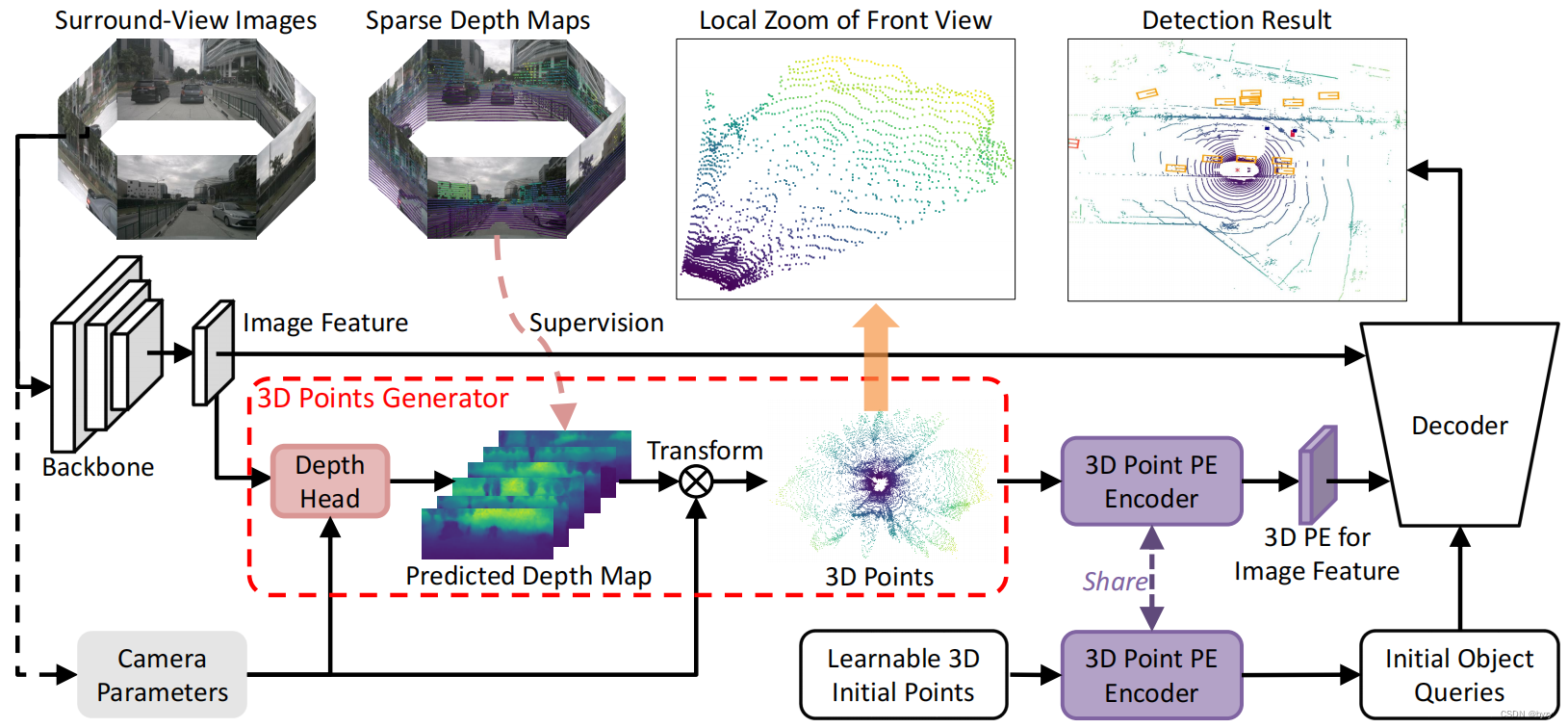 如上图所示,给定
N
N
N个环视图图像
I
=
{
I
i
∈
R
3
×
H
I
i
×
W
I
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{I}=\{I_i\in\mathbb{R}^{3\times H_{I_i}\times W_{I_i}},i=1,2,\cdots,N\}
I={Ii∈R3×HIi×WIi,i=1,2,⋯,N},输入主干得到图像特征
F
=
{
F
i
∈
R
C
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{F}=\{F_i\in\mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
F={Fi∈RC×HFi×WFi,i=1,2,⋯,N}。进一步输入3D点生成器中的深度估计头得到密集深度图
D
=
{
D
i
∈
R
1
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{D}=\{D_i\in\mathbb{R}^{1\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
D={Di∈R1×HFi×WFi,i=1,2,⋯,N},并通过相机参数转化为3D点
P
3D
=
{
P
i
3D
∈
R
3
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{P}^\text{3D}=\{P^\text{3D}_i\in\mathbb{R}^{3\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
P3D={Pi3D∈R3×HFi×WFi,i=1,2,⋯,N}。共享的3D点PE生成器将这些点编码为
PE
=
{
PE
i
∈
R
C
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\text{PE}=\{\text{PE}_i\in\mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
PE={PEi∈RC×HFi×WFi,i=1,2,⋯,N}。3D点PE生成器还将可学习的3D参考点编码为物体查询
Q
=
{
Q
i
∈
R
C
×
1
,
i
=
1
,
2
,
⋯
,
K
}
\mathbf{Q}=\{Q_i\in\mathbb{R}^{C\times 1},i=1,2,\cdots,K\}
Q={Qi∈RC×1,i=1,2,⋯,K},这样
Q
\mathbf{Q}
Q与
PE
\text{PE}
PE有统一的3D表达。最后,3D查询能在解码器中通过3DPPE直接与图像特征交互,进行3D目标检测。
如上图所示,给定
N
N
N个环视图图像
I
=
{
I
i
∈
R
3
×
H
I
i
×
W
I
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{I}=\{I_i\in\mathbb{R}^{3\times H_{I_i}\times W_{I_i}},i=1,2,\cdots,N\}
I={Ii∈R3×HIi×WIi,i=1,2,⋯,N},输入主干得到图像特征
F
=
{
F
i
∈
R
C
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{F}=\{F_i\in\mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
F={Fi∈RC×HFi×WFi,i=1,2,⋯,N}。进一步输入3D点生成器中的深度估计头得到密集深度图
D
=
{
D
i
∈
R
1
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{D}=\{D_i\in\mathbb{R}^{1\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
D={Di∈R1×HFi×WFi,i=1,2,⋯,N},并通过相机参数转化为3D点
P
3D
=
{
P
i
3D
∈
R
3
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\mathbf{P}^\text{3D}=\{P^\text{3D}_i\in\mathbb{R}^{3\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
P3D={Pi3D∈R3×HFi×WFi,i=1,2,⋯,N}。共享的3D点PE生成器将这些点编码为
PE
=
{
PE
i
∈
R
C
×
H
F
i
×
W
F
i
,
i
=
1
,
2
,
⋯
,
N
}
\text{PE}=\{\text{PE}_i\in\mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}
PE={PEi∈RC×HFi×WFi,i=1,2,⋯,N}。3D点PE生成器还将可学习的3D参考点编码为物体查询
Q
=
{
Q
i
∈
R
C
×
1
,
i
=
1
,
2
,
⋯
,
K
}
\mathbf{Q}=\{Q_i\in\mathbb{R}^{C\times 1},i=1,2,\cdots,K\}
Q={Qi∈RC×1,i=1,2,⋯,K},这样
Q
\mathbf{Q}
Q与
PE
\text{PE}
PE有统一的3D表达。最后,3D查询能在解码器中通过3DPPE直接与图像特征交互,进行3D目标检测。
4.2. 3D点生成器
混合深度模块:受BEVDepth启发,本文设计了一个混合深度模块,将直接回归深度
D
R
∈
R
H
F
×
W
F
D^R\in\mathbb{R}^{H_{F}\times W_{F}}
DR∈RHF×WF与分类深度
D
P
∈
R
H
F
×
W
F
D^P\in\mathbb{R}^{H_{F}\times W_{F}}
DP∈RHF×WF使用可学习权重
α
\alpha
α进行融合,如下图所示。

简单来说,就是将深度空间
[
d
min
,
d
max
]
[d_{\min},d_{\max}]
[dmin,dmax]离散为
N
D
=
d
max
−
d
min
d
Δ
N_D=\frac{d_{\max}-d_{\min}}{d_\Delta}
ND=dΔdmax−dmin个大小为
d
Δ
d_\Delta
dΔ的区间
D
=
{
d
1
,
d
2
,
⋯
,
d
N
D
}
\mathbf{D}=\{d_1,d_2,\cdots,d_{N_D}\}
D={d1,d2,⋯,dND}后,按照分类方法预测各像素在各深度区间的概率分布
P
∈
R
N
D
×
H
F
×
W
F
P\in\mathbb{R}^{N_D\times H_{F}\times W_{F}}
P∈RND×HF×WF,然后求取期望:
D
P
=
∑
i
=
1
N
D
P
u
,
v
,
i
×
d
i
D^P=\sum_{i=1}^{N_D}P_{u,v,i}\times d_i
DP=i=1∑NDPu,v,i×di 最终的深度估计结果
D
pred
=
α
D
R
+
(
1
−
α
)
D
P
D^\text{pred}=\alpha D^R+(1-\alpha)D^P
Dpred=αDR+(1−α)DP该深度估计使用以点云生成的真实深度图
D
gt
D^\text{gt}
Dgt作为监督信号,损失函数分别为Smooth L1损失和分布focal损失:
L
depth
=
λ
sm
L
SmoothL1
(
D
pred
,
D
gr
)
+
λ
dfl
L
dfl
(
D
pred
,
D
gr
,
D
)
L_\text{depth}=\lambda_\text{sm}L_\text{SmoothL1}(D^\text{pred},D^\text{gr})+\lambda_\text{dfl}L_\text{dfl}(D^\text{pred},D^\text{gr},\mathbf{D})
Ldepth=λsmLSmoothL1(Dpred,Dgr)+λdflLdfl(Dpred,Dgr,D)其中
λ
sm
\lambda_\text{sm}
λsm和
λ
dfl
\lambda_\text{dfl}
λdfl为超参数,
L
dfl
L_\text{dfl}
Ldfl的目标是使真实深度值附近的两个深度区间(
d
i
<
D
gt
<
d
i
+
1
d_i<D^\text{gt}<d_{i+1}
di<Dgt<di+1)概率最大:
L
dfl
(
D
pred
,
D
gr
,
D
)
=
−
d
i
+
1
−
D
gt
d
Δ
log
(
P
i
)
−
D
gt
−
d
i
d
Δ
log
(
P
i
+
1
)
L_\text{dfl}(D^\text{pred},D^\text{gr},\mathbf{D})=-\frac{d_{i+1}-D^\text{gt}}{d_\Delta}\log(P_i)-\frac{D^\text{gt}-d_i}{d_\Delta}\log(P_{i+1})
Ldfl(Dpred,Dgr,D)=−dΔdi+1−Dgtlog(Pi)−dΔDgt−dilog(Pi+1)
2D到3D的坐标变换:设
K
i
∈
R
3
×
3
K_i\in\mathbb{R}^{3\times3}
Ki∈R3×3是第
i
i
i个相机的内参矩阵,
R
i
∈
R
3
×
3
R_i\in\mathbb{R}^{3\times3}
Ri∈R3×3和
T
i
∈
R
3
×
1
T_i\in\mathbb{R}^{3\times1}
Ti∈R3×1分别为从第
i
i
i个相机坐标系到激光雷达坐标系的旋转矩阵和平移矩阵,
P
i
3D
(
u
,
v
)
∈
R
3
×
1
P^\text{3D}_i(u,v)\in\mathbb{R}^{3\times1}
Pi3D(u,v)∈R3×1为第
i
i
i个相机像素
(
u
,
v
)
(u,v)
(u,v)对应的3D点,则
P
i
3D
(
u
,
v
)
=
R
i
K
i
−
1
D
i
pred
(
u
,
v
)
[
u
v
1
]
T
+
T
i
P^\text{3D}_i(u,v)=R_iK_i^{-1}D_i^\text{pred}(u,v)\begin{bmatrix}u\\v\\1\end{bmatrix}^T+T_i
Pi3D(u,v)=RiKi−1Dipred(u,v)
uv1
T+Ti 最后按3D感知范围进行归一化:
P
i
,
p
3D
(
u
,
v
)
=
(
P
i
,
p
3D
(
u
,
v
)
−
p
min
)
/
(
p
max
−
p
min
)
,
p
∈
{
x
,
y
,
z
}
P^\text{3D}_{i,p}(u,v)=(P^\text{3D}_{i,p}(u,v)-p_{\min})/(p_{\max}-p_{\min}), \ \ p\in\{x,y,z\}
Pi,p3D(u,v)=(Pi,p3D(u,v)−pmin)/(pmax−pmin), p∈{x,y,z}
4.3. 3D点编码器
将3D点 P 3D P^\text{3D} P3D输入3D点编码器获取3DPPE: PE i ( u , v ) = MLP ( Cat [ Sine ( P i , x 3D ( u , v ) ) , Sine ( P i , y 3D ( u , v ) ) , Sine ( P i , z 3D ( u , v ) ) ] ) \text{PE}_i(u,v)=\text{MLP}(\text{Cat}[\text{Sine}(P^\text{3D}_{i,x}(u,v)),\text{Sine}(P^\text{3D}_{i,y}(u,v)),\text{Sine}(P^\text{3D}_{i,z}(u,v))]) PEi(u,v)=MLP(Cat[Sine(Pi,x3D(u,v)),Sine(Pi,y3D(u,v)),Sine(Pi,z3D(u,v))])其中正余弦位置编码 Sine \text{Sine} Sine将1维坐标映射为 C / 2 C/2 C/2维向量,含两个线性层和一个ReLU的 MLP \text{MLP} MLP将 3 C / 2 3C/2 3C/2维向量映射为 C C C维向量。
4.4. 3D点感知的特征
将3DPPE与图像特征按元素相加得到3D感知的特征 F 3D F^\text{3D} F3D。
4.5. 对解码器的修改
可学习的3D参考点被送入与前面相同的编码器生成3DPPE E Q E^Q EQ,作为物体查询 Q Q Q。因此, E F E^F EF和 E Q E^Q EQ来自同一嵌入空间,进一步增强查询。
5. 实验
5.1. 与SotA方法比较
相比PETR,引入3DPPE有较大的性能提升,表明了3DPPE比起相机射线PE的优势。
5.2. 消融研究
深度质量的影响:与无深度监督时相比,引入
L
SmoothL1
L_\text{SmoothL1}
LSmoothL1和
L
dfl
L_\text{dfl}
Ldfl均能提高性能。
3D位置感知特征的比较:与相机射线PE相比,本文的3DPPE有更好的性能。
共享3D点编码器的作用:通过与不共享编码器的实验比较,本文共享编码器的方法有更好的性能。
5.4. 对进一步改进的讨论
利用时间一致性:通过时间一致性建模,3DPPE有更好的性能。
使用GT深度进行知识蒸馏:首先使用深度监督训练一个3DPPE模型,称为3DPPE-Oracle,然后在训练蒸馏模型3DPPE-distill时,在Transformer解码器中加入额外分支,与原始分支共享权重但查询参考点被初始化为与3DPPE-Oracle相同(训练时不会被微调),且同时受真实边界框和3DPPE-Oracle的预测结果监督。实验表明,蒸馏模型能提高性能。
附录
C. 对3D位置编码的分析
C.1. 3D相机射线PE
对不同的深度范围、深度区间数量和深度空间离散方式进行实验发现,结果几乎不变。因此,只要能表示相机射线的方向,相机射线PE的性能就几乎不变。因此,可以仅使用相机射线上的2个点来进行PE。
C.2. 激光雷达射线PE假设
若将深度区间数固定为1,选择不同的深度值进行实验,在深度较小的时候性能下降,但深度较大时性能基本不变。这表明此时不再是相机射线PE。由于确定射线需要两个点,而激光雷达的原点固定,因此可以通过一个点确定激光雷达射线。
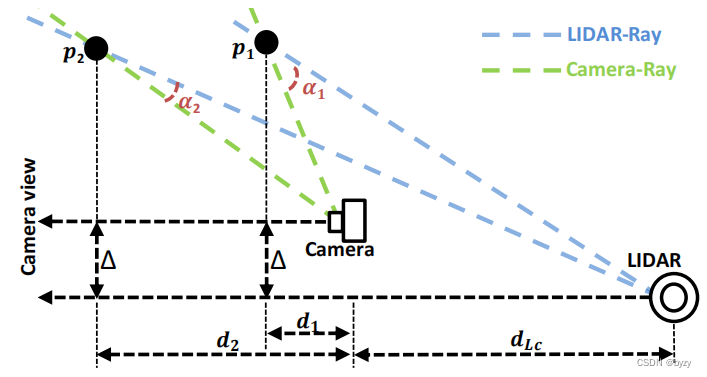
按上图计算相机射线和激光雷达射线的差异
Dis
\text{Dis}
Dis:
Dis
=
1
−
cos
(
α
)
=
1
−
cos
(
α
c
−
arctan
(
tan
α
c
+
Δ
d
1
+
d
L
c
d
)
)
≈
0.0
,
when
d
≫
d
L
c
and
d
≫
Δ
\text{Dis}=1-\cos(\alpha)=1-\cos(\alpha_c-\arctan(\frac{\tan\alpha_c+\frac{\Delta}{d}}{1+\frac{d_{L_c}}{d}}))\approx0.0,\ \ \text{when }d\gg d_{L_c}\text{ and } d\gg \Delta
Dis=1−cos(α)=1−cos(αc−arctan(1+ddLctanαc+dΔ))≈0.0, when d≫dLc and d≫Δ其中
α
c
\alpha_c
αc是相机射线的水平角,
α
\alpha
α相机射线和激光雷达射线的夹角。上述结果表明,当
d
d
d很大时,激光雷达射线基本与相机射线相同,在仅有1个点时就能与相机射线PE保持一致。















 4408
4408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











